理解无人驾驶,就需要理解三个重点:软件比硬件重要、智能比感应重要、预判比识别重要,我将分三个小章节论证这三个重点。基于这三个重点,我会在最后一个小节做出我对未来完全自动驾驶技术路线的预判。
一、十年前的智能手机,十年后的智能汽车。
如今,我们总是能看见这样的营销对比:某某厂商的激光雷达、超声波雷达、毫米波雷达等等,几乎每一种传感器的数量都远超竞争对手。这让我感觉似曾相识,过去的历史在今天又在变着法着重演。十年前,当我们从移动电话走向智能手机时,其实就开始了这种参数对比。那就是我们国产手机的处理器更强,内存更强,屏幕更大,分辨率更高、摄像头像素更好。
2014年,小米以13.7%的智能手机出货量市场份额,排名第一,苹果、华为、联想和三星,分列第2至5名。按照出货量计算,小米也是2014年中国最大的智能手机厂商。十年后,苹果以17.9%的份额位居国内智能手机份额榜首。当我们再看配置表会发现,大多数参数还是国产手机遥遥领先(除了被制裁的芯片)。
从这个历史中我得出了一个结论,当我们说一个手机是“智能”的,那么它的软件体验的权重就远远大于硬件参数。在智能手机这个赛道上,显然硬件占的权重较小。即使在局部取得了极大优势,也无法保证在全局竞争的市场中获得绝对优势。智能手机的本质,是“软件定义电话”,正如今天的智能汽车,是“软件定义汽车”。当我们说车是“智能”的,那么也就代表它的软件体验的权重会远远大于其硬件参数。
二、传感器冗余,还是智能冗余?
很多人认为传感器冗余就代表了安全冗余,这其实是不对的。具体需要什么冗余,取决于问题本身的难点是什么。举一个极端的例子,如果想在拳击擂台上打败泰森,你并不需要清华大学的博士学位,智商虽然也重要,但是你打拳并不需要“智能冗余”,同理,如果你想要在围棋上赢过柯洁,你也不需要百米跑进9秒俱乐部,比赛中的体力虽然也重要,但是体力的权重也绝对比不上棋力。同理,我想论证的是,自动驾驶的传感器虽然也很重要,但是感应的权重绝对比不上智能。智能驾驶的难点在于常识理解、逻辑推理、因果预测等,所以我认为真正需要的应该是“智能冗余”。
人类早就实现了不载人的火箭发射,但却实现不了无人驾驶汽车,我想原因是显而易见的。火箭发射的全过程在发射之前就已经计算好,模拟过上千次。火箭的路径、轨道都需要极其精确,所以它是一个“传感器问题”——你需要尽可能多的,甚至是冗余的传感器来保证火箭在预定轨道飞行,因为偏离轨道哪怕一丁点都可能酿成灾难性后果。多种传感器的数据需要交叉验证,互相印证,才能得出可靠的飞行状态判断。冗余的传感器还可以在某个传感器失灵时作为备份,保证飞行数据的连续性和完整性。
不同的是,自动驾驶却是一个“智能问题”。当传感器不足时,足够强的智能依然可以“感知”并“决策”。当智能不足时,传感器却无法弥补。晚上光线不好,看错路牌走错路了?没事换一个路线也能到,但这需要智能。被远光灯短暂致盲了?足够的智能会懂得减速,并看向右侧车道线来保持在车道内。如果大雾天气摄像头和激光雷达都不好使了?足够的智能会懂得减速,或者是靠边停车以保证安全。如果事故不可避免,不得不撞了?那么是撞保时米?还是撞保时捷?怎样损失更小,这个当然也需要智能。交通拥堵了?怎样加塞,怎样与别的司机博弈,这还是需要智能。
驾驶这件事情,既没有固定路径,也难以对所有路况进行预先设计。它需要在不完整、不确定的感应信息基础上,识别出交通参与者,并推理出交通参与者可能的行为意图,预测交通状况的发展趋势。这一切对软件的智能提出了很高要求。自动驾驶的终极难题其实是“电车难题”,比如拉着钢卷的大货车司机是刹车自己传送到异世界?还是撞过去把别人传送到异世界?这些道德伦理问题是非常非常难的,也就是意味着我们需要很多很多很多的“智能冗余”。
有人可能觉得,为什么不能两手抓?事实上是的原因是,自动驾驶太难了。很多人不理解,真正解决全自动驾驶需要价值万亿的数百万车队,经过多年的积累,拿到数十亿公里的训练数据。我们需要价值上千亿的训练算力,很多都是有价无市。我们还需要全世界最好的团队,很多关键人才如今仍然非常短缺。那些市值万亿的科技大厂,正在不惜一切代价的竞争这些关键人才。对于全人类来说,自动驾驶都是一个难到变态的难题,几乎等同于解决AGI。因此,我们很难有足够的资源,以一种“既要又要”的魄力去横推这个关卡。
相反,我们只能有所取舍,找到问题的关键点,基于第一性原理去单点突破。要知道,就算安装上所有传感器,并奇迹般让它们和谐共处、取长补短,自动驾驶问题也仅仅解决了10%,现实世界仍然存在90%的极其困难的问题需要极高的智能才能攻克。完美的传感器可以完美的解决10%的部分问题,但完美的智能可以以一种还算能接受的程度解决100%的问题。

三、防御性驾驶:安全的关键在于预判
无人驾驶汽车要想安全上路,光靠识别能力是远远不够的。车载的传感器也许能捕获到、并识别出前方有一个行人,但更关键的是要判断出这个行人接下来可能采取的行动。比如,一个低头看手机的行人,即使车来了也可能心不在焉地横穿马路。一对在人行道上发生口角的行人,下一秒很可能就会失控打起来,甚至滚到车道上。路口的一辆小电驴,骑手已经等得不耐烦了,说不定下一秒就要违规闯红灯。这些都需要无人车具备更高层次的理解能力,提前判断可能出现的危险情况,未雨绸缪做好防御性驾驶。
防御性驾驶的关键,就在于无人车系统能否从海量路况数据中学习到交通参与者的行为模式,从而对他们接下来的意图做出较为准确的预判。这需要融合计算机视觉、因果推理等,构建起一套复杂的意图预测模型。模型需要理解人的心理,洞察人在不同情景下可能做出的决策。这其中包含了大量的不确定性和模糊性,对算法的泛化能力和鲁棒性提出了极高的要求。
可以说,要让无人驾驶技术走向成熟,最后一公里的挑战,恰恰在于这些看似“细枝末节”的人性化预测能力。无人车竞争是一个拼智商的游戏,并不是一个拼传感器的游戏。无人车不能只当一个“精准的执行者”,更要成为一个“善解人意的驾驶员”。唯有如此,它才能像人类驾驶员那样,与周遭的交通参与者和谐互动,灵活应对各种突发情况。
四、端到端大模型:全自动驾驶的唯一答案
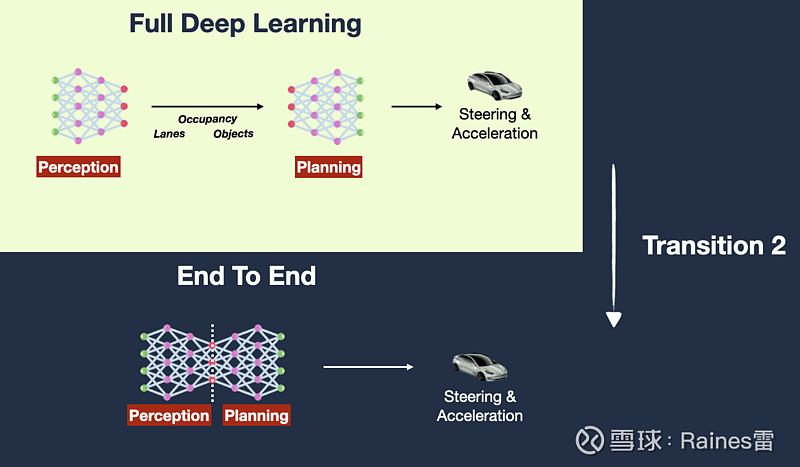
综上所述,要实现全自动驾驶,我们需要从根本上转变思路。与其在硬件上做文章,不如在软件上下功夫。与其追求感应的精确性,不如提升智能的泛化力以更好的感知并决策。与其满足于对当下场景识别的准确率,不如追求预判的空间广度和时间深度。这一切,都指向了一个方向:端到端的大模型。
端到端大模型的优势在于,它可以最大限度地利用输入数据中蕴含的信息。传统的模块化方案,每一个模块都会对数据进行筛选和简化,导致信息在传递过程中不可避免地出现损失。就像传话游戏一样,到最后一个环节时,留存下来的信息往往已经面目全非。而端到端模型可以直接将原始输入映射到最终输出,中间不经过任何压缩或过滤,从而最大程度保留了信息的完整性。这种信息量的最大化保留,正是实现精准预测的关键。

在传统的“感知、规划、控制”模块化设计下,信息流通受损可能会导致很多问题。想象这样一个场景:当一辆无人车行驶在一条郊区公路上,前方有一个骑自行车的人。摄像头拍到了骑手的位置和速度,并且还收集到了骑手头部和肩部细微的倾斜。感知模块准确地检测出了自行车骑手的位置和速度,将骑手抽象为一个简单的"自行车物体",并将其位置、速度等少量信息传递给规划模块。在这个过程中,自行车骑车的头部和肩部动作就被当成不重要的“噪音”给过滤掉了。
规划模块基于感知模块的信息,对无人车的未来轨迹进行了规划。按照常理,只要与自行车保持安全距离并适时减速就可以安全通过。但实际上,骑手正准备突然减速左转进入一条小路。如果规划模块能够获得骑手头部左倾的信息,或许就能推断出他的意图,进而及早减速留出安全距离。可惜这些关键信息都已经被感知模块“过滤”掉了。
在这种情况下,即使控制模块再精准,也难以弥补前期决策的失误。因为在控制模块眼中,眼下的局面不过是“跟踪自行车物体的轨迹”,它没有任何理由去怀疑规划模块给出的指令。直到自行车骑手真的突然左转,一切都已经太晚了,最终无人车不得不进行紧急刹停。
这个例子揭示了模块化架构的一个潜在缺陷:每个模块都倾向于按照自己的“理解”,对数据进行抽象和简化。在这个过程中,一些看似无关紧要的细节实际上可能暗含着重要信息,但却被过早地丢弃了。这种信息流通的“中断”和“丢失”,会从根本上限制整个系统的能力上限。
相比之下,端到端的一体化模型就能避免这个问题。传感器的完整数据可以直接参与到决策过程中,哪怕是一些细枝末节,也有可能成为影响决策的关键因素。更重要的是,模型可以自主地学习哪些信息是有价值的,无需人工设定筛选规则。久而久之,它或许能领悟到一些人类尚未意识到的微妙规律。
事实上,无论是纯视觉方案,还是融合视觉方案,都有实现全自动驾驶的潜力。因为我们之前已经论证过了,全自动驾驶问题是一个“智能问题”而不是“传感器问题”。这就好像一个人考不考得上清华北大,与他是近视眼、远视眼、还是标准视力都没有太大的关系。因为高考是一个“智能问题”,而不是一个“传感器问题”,我们需要的是“智能冗余”,而不是“传感器冗余”。$赛力斯(SH601127)$ $特斯拉(TSLA)$