对于股价的预测是研究的终极目标,基本面研究相信当前公司的优秀特征(如优秀的管理层、好的商业模式、稳健的财务等)在未来会让公司变的更加优秀,也因而未来的股价会变的更好;量化研究则是更加直观的通过基于历史统计的数据指标来提前反应未来股价。然而,这是一件非常难的事情,尤其是对于量化研究,股价含有太多的噪音和短期的影响因素,直接通过模型来研究股价规律是公认的难题。因此将二者结合起来,是一个比较不错的办法。
本文参考了2017年发表在NIPS的 《Improving Factor-Based Quantitative Investing by Forecasting Company Fundamentals》一文,通过深度学习模型来预测噪音少的基本面因子,再利用预测的因子进一步构建投资组合,将该方法在A股市场进行了实证分析。
根据在实证分析中的多次训练、取平均值后的统计结果来看,利用深度学习模型可以对基本面因子进行预测,从而提高因子收益。
第一部分:数据说明和处理
1、原始数据的获取和加工
--直接通过DATAAPI拿到原始的数据,具体数据的选取参考论文中的项目;
--财务TTM数据: REVENUE, COGS, SELL_EXP, ADMIN_EXP, FINAN_EXP, N_INCOME;
--财务MRQ数据:N_CE_END_BAL, AR, INVENTORIES, FIXED_ASSETS, INT_CL, AP, INCOME_TAX, T_LIAB, OTH_CA, OTH_NCA, OTH_CL;
--行情数据:个股市值、前1个月涨幅、3个月涨幅、6个月涨幅、9个月涨幅;
--加工计算得到的数据:THRE_EXP = SELL_EXP + ADMIN_EXP + FINAN_EXP;EBIT = FINAN_EXP + N_INCOME (简化处理,财务费用+净利润)。
2、对数据进行处理
--根据模型的输入格式要求对齐数据;
--对数据进行归一、标准化处理。
3、训练、验证、测试数据的划分
第二部分:研究思路的出发点和信心来源
可以选用很多基本面因子进行研究,此处参照论文中,使用EBIT/EV因子,对于EV的计算简单采用如下公式:
EV = Market_value(市值) + T_LIAB(负债) - N_CE_END__BAL(现金和现金等价物)
--首先对EBIT/EV因子进行测试,基于当前的因子值,看因子的表现情况;
--分别假设我们知道未来3、6、9、12个月的因子值,利用未来因子值进行组合构建,看表现情况;
--经过测试发现,基于未来因子值的组合表现比当前因子值好,说明我们去预测未来因子值是有意义的。
1、计算EBIT/EV因子值
--先计算当期的EBIT/EV因子值;
--然后将因子值进行前向shift,这样就能得到过去日期和未来因子值对齐的因子数据格式;
--将因子值存储在base_shift_factors.csv中,数据格式为:
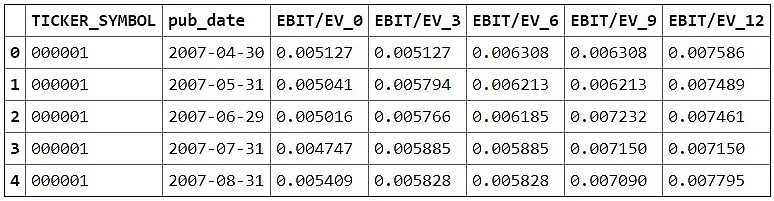
其中 EBIT/EV_0 代表当期的因子值, EBIT/EV_[N] 代表N个月之后的因子值。
2、下面以不同时期的因子在当期进行组合构建,看因子表现,组合构建方式参考论文中的方法,具体为:
--根据申万一级行业分类,每个行业中等权买入2只股票,即每期持有50只股票左右;
--因为因子为基本面的数据,因此设定调仓周期为年。
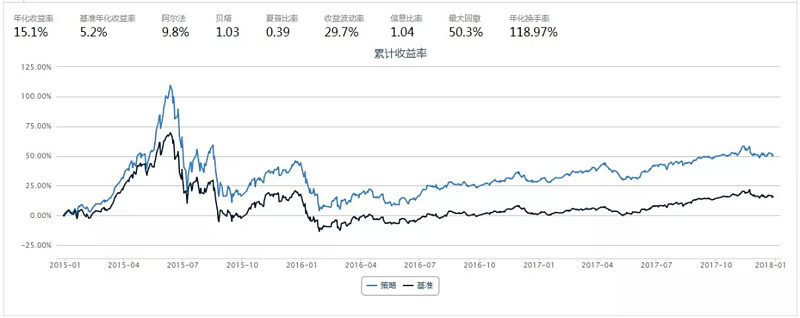
基于当期因子值进行组合构建
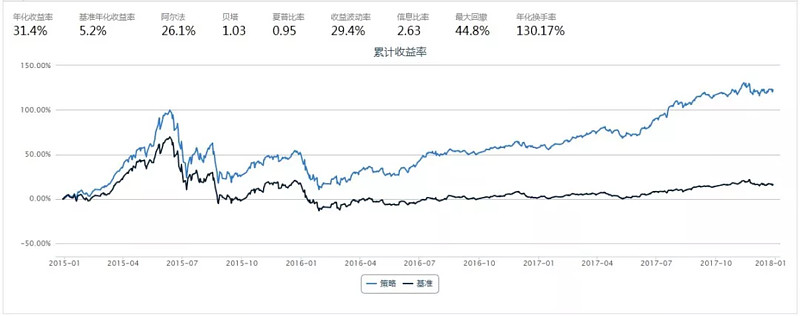
基于12个月后的因子值进行组合构建
结论:从上面的数据可以明显看出,如果能预知未来的因子值,收益可以大大提高(6个月以后),这是后文用深度学习预测基本面的基石,下文的预测指的是预测12个月以后的因子值
第三部分:利用深度学习模型对基本面因子进行预测
1、深度学习模型的结构和原理
MLP模型
感知机模型是最基础的网络结构,示意图如下:
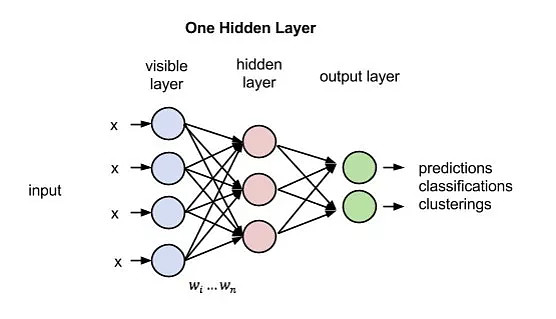
通过隐层、激活函数、全连接(也可以部分连接)实现输入和输出的非线性映射, 多层激活函数可以拟合任何函数。
传统RNN模型
金融类的数据基本都是时间序列数据,具有一定的先后顺序,而RNN模型的特点就是具有记忆功能,因此比较适用在金融领域。传统的RNN结构见下图所示:
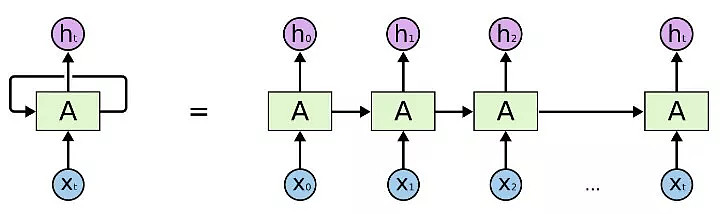
和MLP结构相比,这一结构实现记忆的核心要素为:上一次的输出作为本次的输入,可以这么理解:
--上一次的输出 = f(上一次的输入);
--本次的输出 = f(本次的输入, 上一次的输出) = f(本次的输入, 上一次的输入);
--下一次的输出= f(下一次的输入,本次的输出) = f(下一次的输入, 本次的输入, 上一次的输入);
--依次类推,可以调整网络结构来设置记忆的长度,但从上面也能看出,输出虽然是输入的结果,但经过多级f(x)转换后,可能最前面的数据对结果影响非常小,所以不能设置太长。
然而,由于网络参数进行更新时,都是通过back-propogation,由于链式法则,可能会出现以下常见问题:
--梯度消失,由于back-propogation的时候是乘法,因此多次相乘之后,最前面的参量拿到的导数可能为0,可简单理解为:0.0010.0010.001*0.001… ~= 0;
--梯度爆炸,同样的,由于乘法关系,1.1 * 1.1 * 1.1…得到的值会非常大;
--这样会导致参数利用梯度进行更新时,值不变或者变的非常大而导致网络失效;
--因此,一些变种模型会在传统RNN模型的基础上进行改进,常用的有LSTM和GRU。
LSTM结构
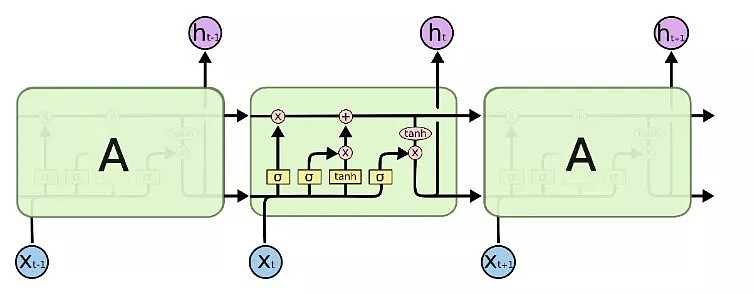
--相比于传统RNN结构,LSTM中增加了长短门控单元;
--从上图可以看出最上面的路径没有经过非门控单元(激活函数),因此当门控单元打开时,记忆信息可以直接传导下去,也因此在反向求导时,不会受到激活函数非线性区的影响,即可以避免RNN引入的梯度消失问题。
GRU结构
LSTM虽然可以解决梯度消失的问题,但是由于引入了太多的记忆门,模型参数比较多,GRU是一种类似的结构,但模型复杂度比LSTM少。
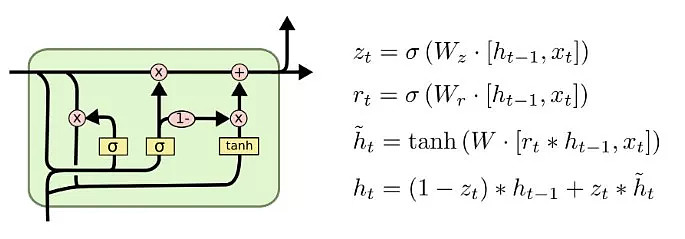
2、训练模型并在测试集数据进行预测
模型结构定义:
--MLP结构定义在MLP_MODEL的对象中;
--传统RNN结构、LSTM结构、GRU结构定义在RNN_MODEL对象中(通过model_params[‘model_name’]来选择)。
训练模型,并在测试集上进行预测得到预测后的因子值:
--模型中的参数,如:学习率、网络隐藏层层数、每个隐藏层的节点数、up_weight(EBIT在算MSE的权重)、keep_prob(dropout比率)、batch_size等都需要进行优化才能确定最佳值;
--限于运行时间,本文的模型中 学习率、网络隐藏层层数、每个隐藏层的节点数直接选用优化好的值,其余参数参考论文中的值;
--在优化参数时,可以遍历不同的参数,然后选择在验证集上MSE值最小的一组参数为最佳参数,学习率的遍历范围为[0.01, 0.001, 0.005], 隐藏层层数为[1,2], 第一层神经元个数为[100, 150, 200], 第二层神经元个数为[200, 400, 800];
--本文的目的在于提供一种思路,因此没有进行大规模调参以获得最佳参数值,代码中的参数还存在较大优化空间,读者有兴趣可以自己进行优化;
--预测后的因子值存储在 [data_save_dir]/[model_name]_predicted_group_0.csv中,存储文件格式为:

--模型在训练集、验证集、测试集的MSE值存储在 [data_save_dir]/[model_name]_mse_summary_0.csv中。
第四部分:回测分析和总结
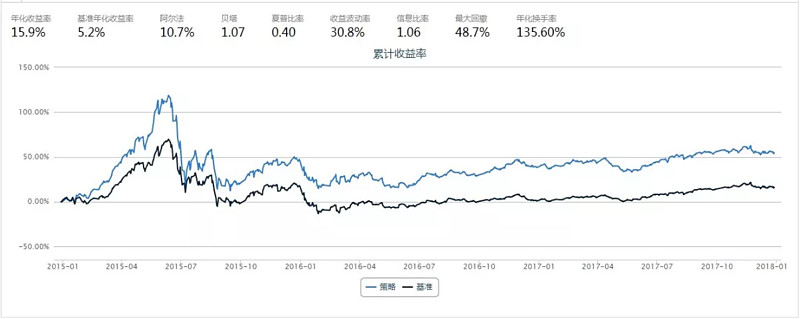
MLP模型的回测结果

传统RNN模型的回测结果
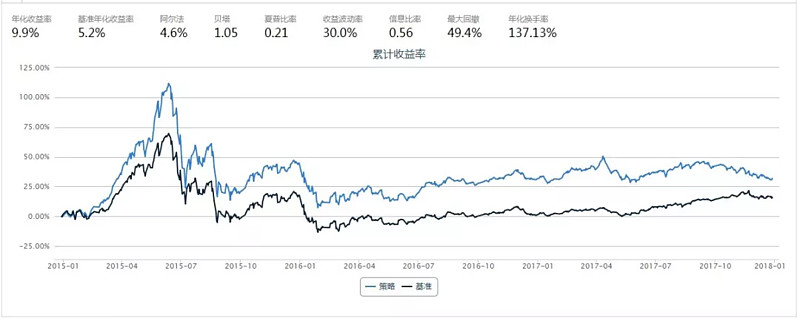
LSTM模型的回测结果
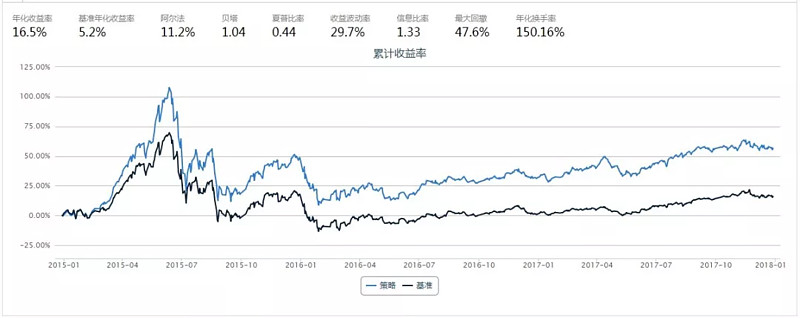
GRU模型的回测结果
总结:
从上面的结果来看,
--以回测的夏普率/年化收益进行比较,MLP, 传统RNN, GRU >basic(不进行预测,以当期因子值进行组合构建) >LSTM;
--以模型在训练集、验证集上的表现来看([model_name]_mse_summary.csv中),LSTM模型的MSE特别小,但回测效果靠后,说明模型的拟合能力过强而泛化能力不足,这种现象称为过拟合,LSTM参数最多因此比较容易发生这一现象,这也是应用深度学习的一大挑战, 可以通过在损失函数中增加正则项、提高DropOut的比率等方法改进;
--如前文所述,深度学习的训练具有一定随机性,根据我们的实验情况,不同批次训练出来的结果有差异,可以通过增加训练样本(如减少持仓周期)、减少模型参数、进行多轮次的交叉验证等方式来提高模型的鲁棒性;
--根据多次训练、取平均值后的统计结果来看,利用深度学习模型可以对基本面因子进行预测,从而提高因子收益。
意犹未尽?到优矿客户端和官网深度报告频道获取完整报告和源代码。
专业版的用户可以查看并一键克隆所有的深度报告,试用专业版的用户可以查看并一键克隆当月的两篇报告,社区版的用户可以查看我们的报告,寻找研究思路。
号外:利用平台强大的资源,优矿特推出2018量化精英养成计划,培养最优秀的Quants,寻找夜空中最亮的那颗星!来自毕业于牛津大学、北京大学、香港大学等高校的地表最强量化金工团队,手把手带你从0到1玩转量化。
