这篇报告的作者就是当年给了$特斯拉(TSLA)$ 拆股前10元目标价的那个人,本来对这篇报告毫无兴趣的,不过看雪球上讨论满多的,闲着也是闲着,正好@cowgirlMMQ 给了份报告,拿来读读。
正在读,随手写下点评,读到哪儿写到哪儿,随时更新。【】里的是报告原文,其中中文是谷歌翻译。
一
【The autonomous car has been described as the mother of all AI projects. In its quest to solve for autonomy, Tesla has developed an advanced supercomputing architecture that pushes new boundaries in custom silicon and may put Tesla at an asymmetric advantage in a $10trn TAM.
自动驾驶汽车被称为所有人工智能项目之母。为了解决自动驾驶问题,特斯拉开发了一种先进的超级计算架构,该架构突破了定制芯片的新界限,并可能使特斯拉在 10 万亿美元的 TAM 中处于不对称优势。】
“mother of all AI projects”,没有这个说法。
"that pushes new boundaries in custom silicon",没有证据显示如此,ASIC看起来都这样。
“a $10trn TAM.”,还不知道是什么有10万亿(?),等看到下面再回来点评。
二
【We believe that Dojo can add up to $500bn to Tesla's enter- prise value, expressed through a faster adoption rate in Mobility (robotaxi) and Network Services (SaaS). The change drives our PT increase to $400 vs. $250 previously. We upgrade to Overweight and make Tesla our Top Pick.
我们相信,Dojo 可以为 Tesla 增加高达 5000 亿美元的企业价值,这可以通过移动(机器人出租车)和网络服务(SaaS)更快的采用率来体现。 这一变化促使我们的 PT 上涨至 400 美元,而之前为 250 美元。 我们升级至“增持”,并将特斯拉列为首选。】
这是这篇报告的核心逻辑。

但是分析师似乎没有搞清楚Dojo和FSD和Mobility (robotaxi) and Network Services (SaaS)的关系,Network Services (SaaS)是啥?
分析师甚至连Dojo是啥都没搞明白?是不是这样?等看到下面再来修正。
如果说将来FSD很赚钱、Robotaxi很赚钱,所以我提升目标价,巴拉巴拉,还有一点逻辑性。Dojo只是提供AI算力的一项基础设施,假设特斯拉没做Dojo,除了成本上有一点点影响之外一点都不影响特斯拉做FSD。Dojo是什么,其实Musk在最近的财报电话会议里——财报电话会议里不能乱吹牛——讲过。
2023Q2:【And I really just don’t know how anyone could do what we’re doing, even if they had our software and had our computer, if they did not have the training data. So, speaking of which, our Dojo training computer is designed to significantly reduce the cost of neural net training. It is designed to -- it’s somewhat optimized for the kind of training that we need, which is a video training. So, we just see that the need for neural net training -- again, talking -- speaking of quasi-infinite things, is just enormous. So, I think having -- we expect to use both, NVIDIA and Dojo, to be clear. But there’s -- we just see demand for really vast training resources.我真的不知道如果没有训练数据,任何人怎么能做我们正在做的事情,即使他们拥有我们的软件和计算机。因此,说到这里,我们的 Dojo 训练计算机旨在显着降低神经网络训练的成本。它的设计目的是——它针对我们需要的培训类型(视频培训)进行了一定程度的优化。所以,我们看到神经网络训练的需求——再次强调——说到准无限的事物,是巨大的。因此,我认为我们希望同时使用 NVIDIA 和 Dojo,这一点很明确。但我们只是看到了对大量培训资源的需求。】
【So that’s what Dojo is designed to do is optimize for video training. It’s not optimized for LLMs. It’s optimized for video training. With video training, you have a much higher ratio of compute-to-memory bandwidth, so -- whereas LLMs tends to be memory bandwidth choked. So that’s it. I mean -- but like I said, we’re also -- we have some -- we’re using a lot of NVIDIA hardware. We’ll continue to -- we’ll actually take NVIDIA hardware as fast as NVIDIA will deliver it to us. Tremendous respect for Jensen and NVIDIA. They’ve done an incredible job.Dojo 的设计目的就是针对视频训练进行优化。它没有针对 LLM 进行优化。它针对视频培训进行了优化。通过视频训练,您的计算与内存带宽的比率要高得多,因此,LLM 往往会受到内存带宽的限制。就是这样了。我的意思是 - 但就像我说的,我们也 - 我们有一些 - 我们正在使用很多 NVIDIA 硬件。我们将继续——实际上,我们将按照 NVIDIA 向我们交付硬件的速度来获取 NVIDIA 硬件。对 Jensen 和 NVIDIA 表示极大的敬意。他们做了令人难以置信的工作。】
以及被问到Dojo的资本开支时【And frankly, I don’t know if they could deliver us enough GPUs, we might not need Dojo, but they can’t. So they’ve got so many customers. They’ve been kind enough to nonetheless, prioritize some of our GPU orders. But yes, the sheer magnitude of video training -- because like I said, we’re not trying to just get as good as human. We want to get to 10 times better than human, maybe 100 times better than human.坦率地说,我不知道他们是否能为我们提供足够的 GPU,我们可能不需要 Dojo,但他们不能。所以他们有很多顾客。尽管如此,他们还是很友善地优先考虑了我们的一些 GPU 订单。但是,是的,视频训练的规模是巨大的——因为就像我说的,我们并不只是想变得和人类一样好。我们希望比人类好 10 倍,甚至比人类好 100 倍。】
2023Q1:【So, yes, so we're also very focused on improving our neural net training capabilities as is one of the main limiting factors of achieving full autonomy. So, we're continuing to simultaneously make significant purchases of NVIDIA GPUs and also putting a lot of effort into Dojo, which we believe has the potential for an order of magnitude improvement in the cost of training.
所以,是的,我们也非常注重提高神经网络训练能力,这是实现完全自主的主要限制因素之一。因此,我们在继续大量采购 NVIDIA GPU 的同时,也在 Dojo 上投入了大量精力,我们相信 Dojo 有可能大幅降低训练成本。
And it also -- Dojo also has the potential to become a sellable service that we would offer to other companies in the same way that Amazon Web Services offers web services, even though it started out as a bookstore. So, I really think that, yes, the Dojo potential is very significant.
而且,Dojo 也有潜力成为一项可销售的服务,我们可以像 Amazon Web Services 提供 Web 服务一样向其他公司提供这种服务,尽管它最初是一家书店。所以,我真的认为,是的,Dojo 的潜力非常巨大。】
“Dojo 也有潜力成为一项可销售的服务,我们可以像 Amazon Web Services 提供 Web 服务一样向其他公司提供这种服务”,实际上,AWS已经在提供着AI算力服务了,不光是AWS,谷歌和微软也已经在提供着了,并且,它们也和特斯拉一样,自己做了xPU,比如我们听说过的谷歌的TPU。
至此,我给Dojo下个定义:Dojo是一项由特斯拉针对视频训练优化的AI算力基础设施。
三
【With a highly experienced semiconductor team, Tesla has built a custom AI ASIC chip, that, due to its core function of processing vision-based data for autonomous driving use cases, can operate more efficiently (energy consumption, latency) than the leading cutting-edge general-purpose chips on the market (NVIDIA's A100s and H100s), and at a fraction of the cost. Dojo is a training computer made up of many thousands of D1 chips housed in an AI data center. It trains the inference engine (FSD chip) that sits within the vehicles at the edge which Tesla has designed in-house for the past 7 years.】
这段话是被广为误解的,“more efficiently (energy consumption, latency) than the leading cutting-edge general-purpose chips on the market (NVIDIA's A100s and H100s)”,比市场上最领先、前沿、尖端的通用芯片 (NVIDIA's A100s and H100s)还要xxx、xxx、xxx。“cutting-edge”往往被翻译为“边缘”,因为他行文下面也用了个“that sits within the vehicles at the edge”,如果是我写这段文字,我会换个词而不用“cutting-edge”。。。
“It trains the inference engine (FSD chip) that sits within the vehicles at the edge”,但是,这是啥意思,作者想说啥?把几个不相干的东西搅在一起,一脑子浆糊。
四
【The more we looked at Dojo, the more we realized the potential for underappreciated value in the stock. Like many other large cap tech stocks on your screen, we believe Tesla can reasonably test its all-time highs of $400 over the next 12 months.
我们对 Dojo 的研究越多,就越意识到该股票价值被低估的潜力。与屏幕上的许多其他大型科技股一样,我们相信特斯拉可以在未来 12 个月内合理地测试其 400 美元的历史高点。】
去研究一下AWS、Google Cloud和Azure呗。。。【We believe that Dojo can add up to $500bn to Tesla's enter- prise value】,那亚马逊、谷歌和微软已经有了大量“Dojo”客户和收入了,该add多少enterprise value呢?
五
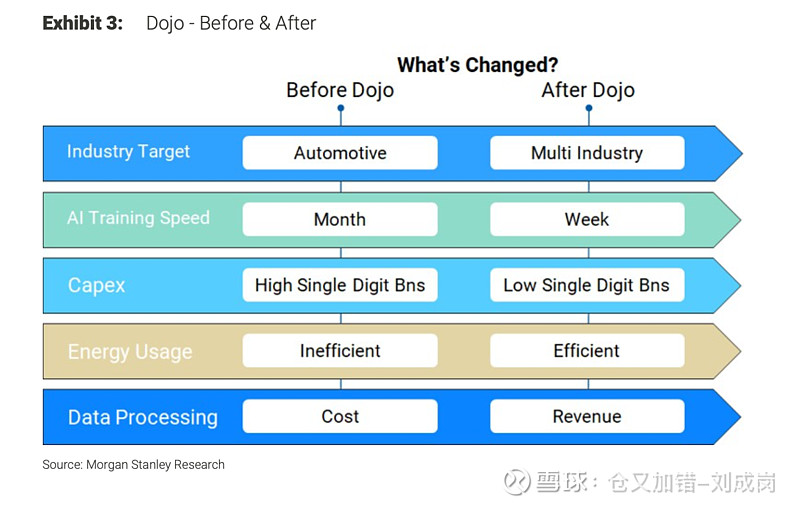
这图是认真的吗?特别是最后一行,怎么就用了Dojo后Data Processing就从Cost变成Revenue了?
六
【For our Tesla modeling purposes, we focused on the potential for Dojo to deliver autonomy and network services revenues at a faster attach rate with higher average monthly revenue per user (ARPU), driving a material increase to our estimates. We have NOT given Tesla credit for specific cost savings from Dojo vs. its current supercomputing budget. Nor have we given Tesla credit for any non-auto-related revenue streams. With significantly increased computing power and faster processing speeds (latency), Tesla's path to monetizing vehicle software can materialize sooner, and at higher recurring revenue rates. We also for the first time incorporate non-Tesla fleet licensing revenue into our Network Services model as we expect recent charging station cooperation will extend into FSD licensing (discussions ongoing) and operating system licensing. We now forecast Tesla Network Services to reach $335bn in revenue in 2040 vs $157bn previously, and expect the segment to represent over a third of total company EBITDA in 2030, doubling to over 60% of group EBITDA by 2040 (vs. 38% previously). This increase is largely driven by the emerging opportunity we see in 3rd party fleet licensing, increased ARPU, with operating leverage driving higher long-term EBITDA margin vs. prior forecast (65% from FY26 onwards, vs. 50% previously). In addition to Network Services, we indirectly ascribe the value of Dojo to our Tesla Mobility robotaxi assumptions (increased long term fleet size and margin), and 3rd Party Battery Business, as we believe the charging and FSD deals will also result in higher hardware attach.
出于 Tesla 建模目的,我们重点关注 Dojo 以更快的附加率和更高的每用户平均月收入 (ARPU) 提供自治和网络服务收入的潜力,从而推动我们的预期大幅增长。 与当前的超级计算预算相比,我们并未将 Dojo 的具体成本节约归功于特斯拉。 我们也没有将任何非汽车相关的收入来源归功于特斯拉。 凭借显着增强的计算能力和更快的处理速度(延迟),特斯拉的车辆软件货币化之路可以更快实现,并获得更高的经常性收入。 我们还首次将非特斯拉车队许可收入纳入我们的网络服务模式,因为我们预计最近的充电站合作将扩展到 FSD 许可(仍在讨论中)和操作系统许可。 我们现在预测 Tesla Network Services 的收入将在 2040 年达到 3,350 亿美元,而之前为 1,570 亿美元,并预计到 2030 年该部门将占公司 EBITDA 总额的三分之一以上,到 2040 年将翻一番,达到集团 EBITDA 的 60% 以上(之前为 38%) 之前)。 这一增长主要是由于我们在第三方车队许可方面看到的新兴机会、ARPU 的增加以及运营杠杆推动长期 EBITDA 利润率高于之前的预测(从 2026 财年起为 65%,而之前为 50%)。 除了网络服务之外,我们还间接将 Dojo 的价值归因于我们的 Tesla Mobility 机器人出租车假设(长期车队规模和利润的增加)以及第三方电池业务,因为我们相信充电和 FSD 交易也将导致更高的硬件附加值 。】
这段看起来是估值建模的核心逻辑了,行,你说的其它的我暂且都信,但是,“higher average monthly revenue per user (ARPU)”和“ higher recurring revenue rates.”和Dojo有啥关系?用户会因为你用Dojo就多付钱?情怀?
七
【Stretching your thinking. Could success in vehicle autonomy enable Tesla to become Go-To provider for visual data processing across other adjacent markets? Although Dojo is still early in its development, we believe that its applications long-term can extend beyond the auto industry.拓展你的思维。车辆自动驾驶方面的成功能否使特斯拉成为其他邻近市场视觉数据处理的首选提供商?尽管Dojo仍处于发展初期,但我们相信其应用长期可以扩展到汽车行业之外。】
嗯,向中国同行学习,Stretching your thinking。。。好吧,我们先Stretching吧,那么,既然你都说了【Dojo仍处于发展初期】,说明这事办不成的概率大啊,那么这部分估值上要不要打个1折?
八
您没来过中国看过中国的AI公司吧?。。。要不然用同样的逻辑给海康威视、商汤科技、云天励飞等公司估估值?
九
【According to Morgan Stanley's US semis analyst Joe Moore, vision-based training is actually less complex than large language model (LLM) training摩根士丹利美国半导体分析师 Joe Moore 表示,基于视觉的训练实际上没有大型语言模型 (LLM) 训练复杂】
特斯拉最新的端到端FSD技术路线,视觉训练远比LLM复杂多了,在 这篇采访 中,受访者表示“现在还有巨大的gap。比如给一段视频,能不能预测出合理的下一帧,这个是LLM现在已经具备的能力了。另外给一段视频,针对视频内容提问,能不能给出正确的答案。”,说明如果视频训练到LLM这个水平,假设理论上可行的话,现在的训练还远远不够,不足以产生“涌现”。
十
【The first Dojo ExaPOD (online since July 2023) was expected to target Tesla's auto-labeling networks…第一个 Dojo ExaPOD(自 2023 年 7 月起上线)预计将针对特斯拉的自动标签网络……
While not claiming perfection, Tesla has described this upcoming FSD version as its 'ChatGPT moment' in terms of delivering a major step change improvement in performance of the system (without labeling, without LiDAR and without HD maps). While the in-house Dojo D1-based system is seen as a critical enabler for this development, Tesla If successful, we would expect to see Tesla rely even further on its own in-house technology.虽然特斯拉并没有声称完美,但特斯拉将即将推出的 FSD 版本描述为“ChatGPT 时刻”,因为它在系统性能方面实现了重大的一步改变改进(没有标签、没有激光雷达和没有高清地图)。虽然特斯拉内部基于 Dojo D1 的系统被视为这一开发的关键推动者,但如果特斯拉成功,我们预计特斯拉将进一步依赖自己的内部技术。】
您前面刚写了,2023年7月份才上线,那这个2023年7月份才上线的东西,怎么就成了“关键推动者”了呢?
十一
【Tesla predicts that they will reach 100 exaFLOPs of compute by Q4 2024, up from ~4.5 today. According to Tesla, that's the equivalent of ~300,000 A100 GPUs, which on our estimates would cost $7.5bn - $8.0bn. Whether the 100 exaFLOP goal becomes reality by then or not, management believes that Dojo features greater efficiency, scalability, cost-effectiveness, and functionality than any other GPU.
Tesla 预测,到 2024 年第四季度,他们的计算能力将达到 100 exaFLOP,而目前约为 4.5。据 Tesla 称,这相当于约 30 万个 A100 GPU,我们估计这将花费 75 亿至 80 亿美元。无论 100 exaFLOP 目标届时是否成为现实,管理层都相信 Dojo 比任何其他 GPU 都具有更高的效率、可扩展性、成本效益和功能。】
视频专门优化定制的芯片和AI计算架构,确实可以提高效率降低成本的。
十二
【X (Formerly Twitter) – Investors have wondered where Twitter can fit in the Tesla ecosystem. Twitter can benefit from shifting away from its current compute systems and switching to no/low-cost data computation from the most powerful supercomputer systems in the world, greatly accelerating the platform to new heights. Dojo V2 is anticipated to incorporate the general-purpose AI limitations that V1 currently lacks. Training itself through the LLMs can provide a huge ecosystem of data that feeds into itself. As we've long said, owning and moderating a free speech platform poses incredible moral, political, technological, and regulatory challenges – a supercomputing system has the potential to support the platform. Finally, Twitter’s vast collection of data from its hundreds of millions monthly active users provides Tesla with another source of data that can be used to train its systems.
X(以前的 Twitter)——投资者想知道 Twitter 在特斯拉生态系统中的定位。 Twitter 可以从当前的计算系统转向世界上最强大的超级计算机系统的无/低成本数据计算中受益,从而大大加速该平台达到新的高度。 Dojo V2 预计将包含 V1 目前缺乏的通用 AI 限制。通过法学硕士进行自我培训可以提供一个巨大的数据生态系统,这些数据可以反馈给自身。正如我们长期以来所说,拥有和管理一个言论自由平台会带来令人难以置信的道德、政治、技术和监管挑战——超级计算系统有潜力支持该平台。最后,Twitter 从数亿月度活跃用户那里收集的大量数据为特斯拉提供了另一个可用于训练其系统的数据来源。】
这段我挺感兴趣的,有任何证据显示Dojo V2可以用于通用AI计算吗?我是不是漏过了什么资料?请大家补充。因为文字的AI计算和视频AI计算在技术上有巨大的不同,很难想象一个为视频专门优化的ASCI又能很好地处理文字。另外,印象中Twitter是不是刚向英伟达下了一个GPU大单?
更新,答案找到了【Next generation Dojo will have a broader AI scope. According to a tweet by Musk in June 2023, Dojo V1 is highly optimized for vast amounts of video training while Dojo V2 will incorporate any generalpurpose AI limitations that V1 currently faces. Teslhat an upwards of 10x improvement can be achieved when the next-gen hardware (V2) is developed and implemented, which can enable the company to reach 100 exaFLOPs by 4Q24.下一代 Dojo 将拥有更广泛的 AI 范围。根据 Musk 于 2023 年 6 月发布的推文,Dojo V1 针对大量视频训练进行了高度优化,而 Dojo V2 将纳入 V1 目前面临的任何通用人工智能限制。】,是Musk的推文。
【SpaceX – SpaceX’s thousands of satellites communicate with each other via Intersatellite Link (ISL), which provides a direct link within the space segment without the need of an intermediate ground segment to relay the data. Since the satellites communicate through lasers, large amounts of data is required for precise measurements needed to connect and hand off. Additionally, immense computational power is required in the field of orbital debris mitigation and avoidance for the satellites need to avoid collisions, where the required metrology can benefit from AI computations. The same way Dojo can be used in autonomous driving to avoid obstacles and create a planned path to use, SpaceX can use Dojo to train their systems to communicate and avoid debris collisions.
SpaceX – SpaceX 的数千颗卫星通过卫星间链路 (ISL) 相互通信,该链路在太空段内提供直接链路,无需中间地面段来中继数据。由于卫星通过激光进行通信,因此需要大量数据来进行连接和切换所需的精确测量。此外,在轨道碎片减缓和规避领域需要巨大的计算能力,因为卫星需要避免碰撞,而所需的计量可以从人工智能计算中受益。就像 Dojo 可用于自动驾驶以避免障碍物并创建计划的路径一样,SpaceX 也可以使用 Dojo 来训练其系统进行通信并避免碎片碰撞。
Batteries – Analysis of the behavior of magnetic fields and chemical reactions are used to design motors and batteries respectively, using predictive analysis of the thermal properties of such devices. The supply chain, infrastructure, battery, and electric motor are all interconnected with each other and deal with large amounts of data. Tesla has long described the charging network as an extension of the battery and how battery systems can be optimized from the data gathered from the battery fleet on the road and in ESS applications.
电池——对磁场和化学反应行为的分析用于分别设计电机和电池,并通过对此类设备的热性能进行预测分析。供应链、基础设施、电池和电动机都相互关联并处理大量数据。特斯拉长期以来一直将充电网络描述为电池的延伸,以及如何根据从道路上和 ESS 应用中的电池车队收集的数据来优化电池系统。】
这。。。@齐之以和 老哥说“大摩的Adam Jonas是看传统汽车行业的,看懂这个是难为他了。”,确实是难为他了。
注意,这些段落是他前面有个观点的说明【Major potential within the 'Muskonomy': We think that there's a possibility that the Dojo system isn’t just being built to accelerate and train FSD and Optimus; rather it could be a solution that builds a moat around Tesla and Musk-universe companies with highly advanced ML and AI capabilities. Looking internally at other Musk companies, we believe that Dojo may have the capability to be the core of the Muskonomy.
“Muskonomy”的主要潜力:我们认为 Dojo 系统的构建可能不仅仅是为了加速和训练 FSD 和 Optimus;相反,它可能是一个围绕特斯拉和马斯克宇宙公司构建护城河的解决方案,这些公司拥有高度先进的机器学习和人工智能功能。纵观马斯克内部的其他公司,我们认为Dojo可能有能力成为Muskonomy的核心。】
为了论证“Dojo可能有能力成为Muskonomy的核心”,真是“脸都不要了”。。。
十三
【According to Tesla can replace 6 GPU boxes with a single Dojo tile, which enables the company to reduce network training time from ~one month to ~one week. Put differently, Tesla can achieve the same throughput on 4 Dojo cabinets as they can with 4,000 GPUs. The first of aforementioned 7 total ExaPODs came online in July 2023 at the Palo Alto, CA facility and is expected to be 2.5x their current auto-labeling capacity. We note that the state of the art of supercomputing is constantly changing… comparisons of one chip/box/system is complicated on an apples to apples basis and must be seen relative to the trade-offs (cost/energy consumption) and from the perspective of the AI problem being solved (vision vs.
据特斯拉称,可以用单个 Dojo 块取代 6 个 GPU 盒,这使该公司能够将网络训练时间从大约一个月减少到大约一周。换句话说,Tesla 在 4 个 Dojo 机柜上可以实现与使用 4,000 个 GPU 相同的吞吐量。上述 7 个 ExaPOD 中的第一个已于 2023 年 7 月在加利福尼亚州帕洛阿尔托工厂上线,预计将是其当前自动贴标能力的 2.5 倍。
Each Dojo tile requires 15kWh of power o 39kWh for 6 DGX A100s (GPU boxes), a ~60% improvement. Data center space has become scarce as a result of demand from hyperscalers, and there is a dire need to upgrade the power grid due to the capacity and power density of GPUs (2-3x power per square foot). Dominion Energy, the primary power provider in Loudoun County, VA (world's largest concentration of data centers)s major customers that power delivery could be delayed until 2026. Corroborating the gravity of the strain on the electrical grid, Tesla that while testing Dojo in Oct'22, they tripped the power grid in Palo Alto.
每个 Dojo 块需要 15kWh 的电力,或者 6 个 DGX A100(GPU 盒)需要 39kWh,提高了约 60%。由于超大规模企业的需求,数据中心空间变得稀缺,而且由于 GPU 的容量和功率密度(每平方英尺 2-3 倍功率),迫切需要升级电网。弗吉尼亚州劳登县(世界上最大的数据中心集中地)的主要电力供应商 Dominion Energy 的主要客户表示,电力输送可能会推迟到 2026 年。特斯拉在 10 月份测试 Dojo 时证实了电网压力的严重性。 22 年,他们使帕洛阿尔托的电网跳闸。】
这段提供的信息挺有意思的,我没想到特斯拉会把AI计算中心建在Palo Alto,一般来说,AI计算中心这种高能耗项目会建在电力便宜、气温低的地方,比如微软、亚马逊、谷歌们在挪威、海底建计算中心。
十四
【In 2023, GPUs are projected to account for 92% of cloud AI semiconductor deployment, with 8% allocated to custom AI chips – but our Asia Semiconductors team (led by Charlie Chan) ased on the larger scale of AI computing demand that justifies the cost, and the need for vendor diversification given NVIDIA’s bargaining power. Generally, the upfront chip design cost for ASICs is too high at low scale, which is why many major cloud service providers like Meta and Microsoft have been using GPUs until recently. It’s expected that hyperscalers will increase their adoption of custom AI ASICs to improve performance per watt and cost of ownership.
到 2023 年,GPU 预计将占云 AI 半导体部署的 92%,其中 8% 分配给定制 AI 芯片 - 但我们的亚洲半导体团队(由 Charlie Chan 领导)认为 AI 计算需求规模更大,这证明了成本的合理性,以及考虑到 NVIDIA 的议价能力,供应商多元化的必要性。一般来说,小规模情况下 ASIC 的前期芯片设计成本过高,这就是 Meta 和 Microsoft 等许多主要云服务提供商直到最近才使用 GPU 的原因。预计超大规模企业将更多地采用定制 AI ASIC,以提高每瓦性能和拥有成本。】
“Generally, the upfront chip design cost for ASICs is too high at low scale, which is why many major cloud service providers like Meta and Microsoft have been using GPUs until recently.”自相矛盾了。。。
十五
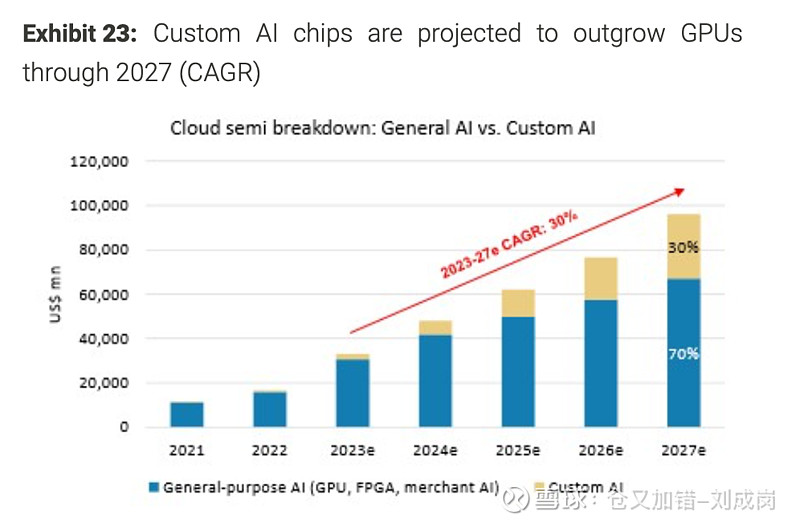
这图的数字仅供参考,但是AI ASIC的占比提升这个观点我是同意的,英伟达的毛利率太高了。
十六
【Beyond cost and efficiency justifications, without diversifying, Tesla's reliance on external GPUs will intensify. If the generative AI trends currently dominating the market continue, demand for NVIDIA systems will remain elevated and procuring sufficient supply of A100s/H100s to meet Tesla's 100 exaFLOP goal will prove difficult. If Tesla were to rely solely on NVDA to reach their stated compute power goal, they alone could comprise 6-11% of NVIDIA’s revenue (assuming Tesla replaces their GPUs every 2-3 years). Tesla’s incorporation of their in-house FSD system in early 2019 (Hardware 3.0), and now their proprietary training chips, begin to mitigate overreliance on NVDA. When combining the tailored capabilities of ASICs and better economics that Tesla can realize with fixed-cost leverage given the company's scale, we view custom AI as the best path forward.
除了成本和效率方面的理由外,如果不进行多元化,特斯拉对外部 GPU 的依赖将会加剧。如果目前主导市场的生成式 AI 趋势继续下去,对 NVIDIA 系统的需求将继续上升,并且采购足够的 A100/H100 供应来满足 Tesla 的 100 exaFLOP 目标将变得困难。如果 Tesla 仅依靠 NVDA 来实现其规定的计算能力目标,那么仅 NVDA 就可以贡献 NVIDIA 收入的 6-11%(假设 Tesla 每 2-3 年更换一次 GPU)。 Tesla 在 2019 年初整合了内部 FSD 系统(硬件 3.0),现在又整合了专有的训练芯片,开始减轻对 NVDA 的过度依赖。当将 ASIC 的定制功能与特斯拉通过考虑到公司规模的固定成本杠杆实现的更好的经济效益相结合时,我们认为定制人工智能是最佳的前进道路。】
同意这个观点。
十七
【Who Else Is Developing Their Own PurposeBuilt AI Chips?
还有谁在开发自己的专用人工智能芯片?
Beyond general purpose chip makers like NVIDIA, Cerebras, and Graphcore, many compute-centric companies have begun turning to custom solutions. A key advantage in a custom chip is that since the company knows their workloads, they can tailor the chip and system to serve a direct purpose. While NVIDIA A100s and H100s are the cutting-edge general-purpose GPU for ML training, a chip built to specifically accomplish a certain purpose (such as utilizing video data to train Tesla’s neural network to accelerate FSD) can be more efficient than the best chips that may have better overall specs. Several companies such as Apple, Microsoft, Google, Amazon, and Meta either develop orevelop their own purpose-built chips. The report from our Asia Semiconductors team estimates that custom AI ASIC chips will represent $6.2bn of market value in 2024e, with the combination of Tesla’s Dojo and FSD amounting to $1.2bn.
除了 NVIDIA、Cerebras 和 Graphcore 等通用芯片制造商之外,许多以计算为中心的公司也开始转向定制解决方案。定制芯片的一个关键优势是,由于公司了解他们的工作负载,他们可以定制芯片和系统来服务于直接目的。虽然 NVIDIA A100s 和 H100s 是用于 ML 训练的尖端通用 GPU,但专门为实现特定目的(例如利用视频数据训练 Tesla 神经网络以加速 FSD)而构建的芯片可能比最好的芯片更高效可能有更好的整体规格。苹果、微软、谷歌、亚马逊和 Meta 等几家公司要么开发或开发自己的专用芯片。我们亚洲半导体团队的报告估计,到 2024 年,定制 AI ASIC 芯片的市场价值将达到 62 亿美元,其中特斯拉 Dojo 和 FSD 的总市值将达到 12 亿美元。
Google: Following Google's announcement of its first-generation TPU (Tensor Processing Unit) in 2016, now the fourth generation (TPU v4) is going through Broadcom’s design service. Google TPU claims 2-3x greater energy efficiency compared to contemporary ML DSAs (machine learning domainspecific accelerators), and more than 3x relative performance improvement over its previous generation, TPU v3.
谷歌:继2016年谷歌发布第一代TPU(张量处理单元)之后,第四代(TPU v4)正在通过博通的设计服务进行。谷歌 TPU 声称,与当代 ML DSA(机器学习领域特定加速器)相比,能效提高了 2-3 倍,相对性能比上一代 TPU v3 提高了 3 倍以上。
Google invented the transformer model over a decade ago, so their 5th generation TPU silicon is fairly optimized around transformers which are suddenly the most important models that there are.
谷歌十多年前发明了 Transformer 模型,因此他们的第五代 TPU 芯片围绕 Transformer 进行了相当优化,而 Transformer 突然成为最重要的模型。
Amazon: Amazon Web Services (AWS) started its ASIC strategy quite early, with the first announcement in 2018. AWS claimed that its first Inferentia chip delivered up to 2.3x higher throughput and up to 70% lower cost per inference (or up to 50% greater performance per watt) than comparable Amazon EC2 instances (using GP GPUs). Its second-generation chip (manufactured using TSMC's 7nm process, going through Alchip’s design service) delivers up to 4x higher throughput and up to 10x lower latency compared to its first-gen Inferentia chip.
亚马逊:亚马逊网络服务 (AWS) 很早就开始了 ASIC 战略,并于 2018 年首次发布。AWS 声称其首款 Inferentia 芯片的吞吐量提高了 2.3 倍,每次推理成本降低了 70%(或降低了 50%)。与同类 Amazon EC2 实例(使用 GP GPU)相比,每瓦性能提高 %。与第一代 Inferentia 芯片相比,其第二代芯片(采用台积电 7 纳米工艺制造,并通过 Alchip 的设计服务)可提供高达 4 倍的吞吐量提升和高达 10 倍的延迟降低。
Microsoft: Since 2019, Microsoft has been developing its own AI chip named Athena. The chip is designed to handle LLM training on TSMC's 5nm process, and is expected to debut sometime in 2024.
微软:自2019年以来,微软一直在开发自己的AI芯片,名为Athena。该芯片旨在处理台积电 5nm 工艺的法学硕士培训,预计将于 2024 年某个时候首次亮相。
Meta: Meta announced its first-gen AI inference accelerator
Meta:Meta 宣布推出第一代人工智能推理加速器
MTIA v1 this year (2023). According to Meta, this AI ASIC (based on TSMC's 7nm process) can reach up to 2x performance per watt vs. an AI GPU and is targeting 2025 for launch.
今年(2023 年)MTIA v1。据 Meta 称,这款 AI ASIC(基于台积电 7nm 工艺)每瓦性能比 AI GPU 最高可达 2 倍,预计于 2025 年推出。】
这段信息很有用,不要以为只有Dojo D1
十八
【NVIDIA used the demanding performance of gaming to develop the world's most powerful GPU chips. Can Tesla use the demands of autonomous cars/FSD to become a global leader in custom AI chips?
NVIDIA 利用游戏的苛刻性能开发了世界上最强大的 GPU 芯片。特斯拉能否利用自动驾驶汽车/FSD的需求成为定制人工智能芯片的全球领导者?】
作者显然是对“custom AI chips”对custom有什么误解,既然是custom,它一定不是general的,只适合特定领域,特斯拉custom的只适合于视频,当然马老师已经在X上吹出牛了可以用于文字,我们师母已呆。
十九
全文高潮来了,
【As the market expands, Tesla can ‘turn on’ new features and services for its vehicle fleet… turning owners into ‘subscribers.’ These services can include everything from charging $2k for a software update that shaves more than 1 second off your 0 to 60 time, improves your access to available media content, enables various levels of highly automated driving/ FSD, insurance products, access to charging infrastructure and a host of other telematics services. Sound familiar?
随着市场的扩大,特斯拉可以为其车队“开启”新功能和服务……将车主变成“订户”。这些服务包罗万象,包括收取 2000 美元的软件更新费用,将 0 到 60 英里的时间缩短 1 秒以上,改善您对可用媒体内容的访问,实现各种级别的高度自动化驾驶/FSD、保险产品、充电访问基础设施和许多其他远程信息处理服务。听起来有点熟?
As more and more consumers ‘opt in’ for a range of these services, Tesla increases its proportion of regularly recurring and high margin (in some cases 100% margin) businesses while further improving the addressable market and the customer experience. This adds stickiness of users to the platform, ballast to the financial profile and top line and margin to the bottom line…. further enhancing the company's ability to make continuous improvement to its core auto product (the hardware) to reduce cost, cut price, expand the user base… and so on.
随着越来越多的消费者“选择”一系列此类服务,特斯拉增加了定期重复和高利润(在某些情况下为 100% 利润)业务的比例,同时进一步改善了目标市场和客户体验。这增加了用户对平台的粘性、财务状况的稳定性、营收和利润的利润……。进一步增强公司对其核心汽车产品(硬件)进行持续改进的能力,以降低成本、降低价格、扩大用户基础……等等。
This double-flywheel is only further accelerated and integrated via the compute power of Dojo.
这个双飞轮只能通过 Dojo 的计算能力进一步加速和集成。】
接下来是详细估值,吧啦吧啦。。。看得眼花缭乱,我一点都不感兴趣,但还是把图放出来供大家观赏。
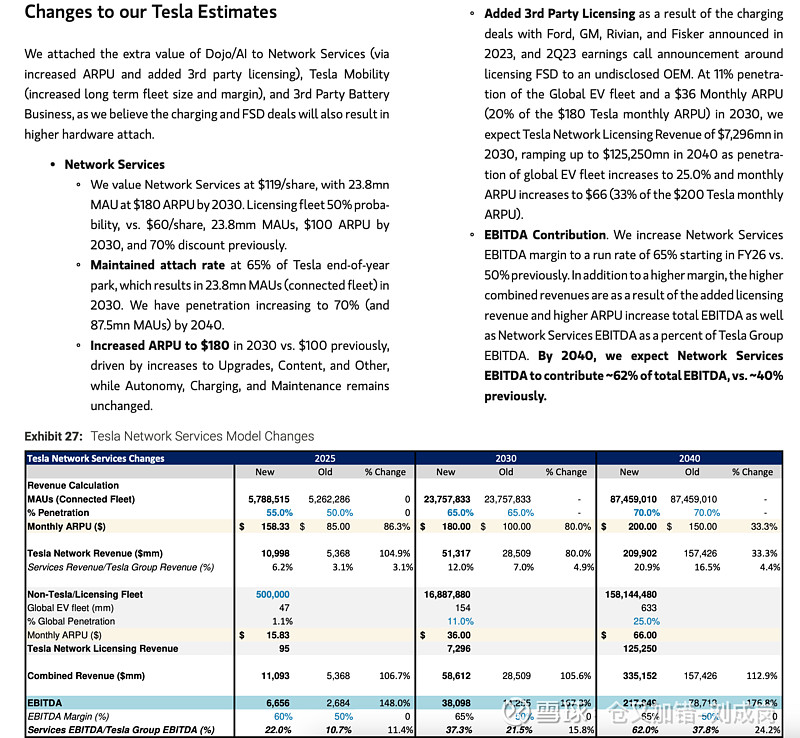
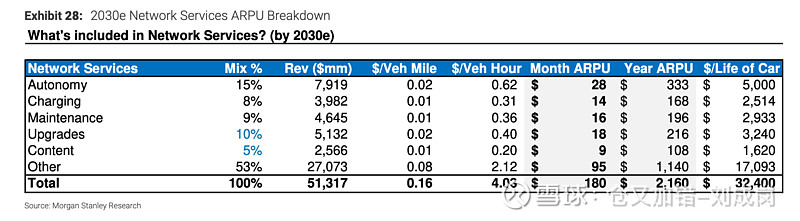
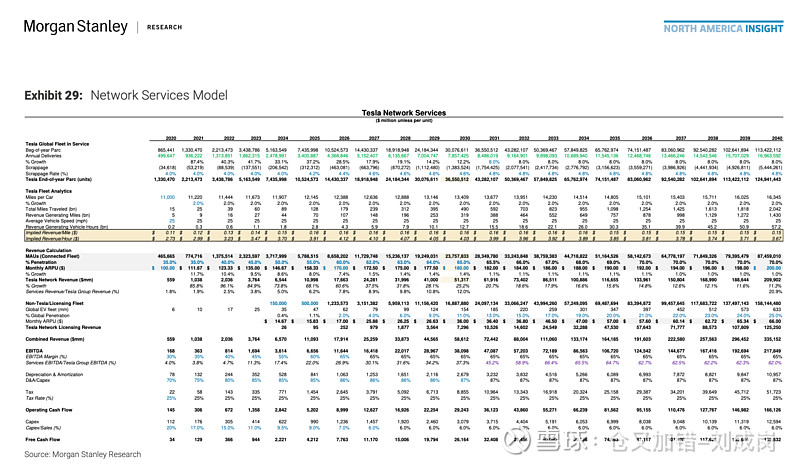
但是,“这个双飞轮只能通过 Dojo 的计算能力进一步加速和集成”吗?这么重要的估值逻辑,基于这么脆弱的一个支点。您是在唱多还是唱空啊。
特斯拉的自动驾驶(假设)领先其它主机厂,可不是因为特斯拉有Dojo别家没有啊,用英伟达的GPU一样可以做自动驾驶的。
我还以为作者发现了一个新大陆,靠Dojo自己拿下开篇所谓的一个“$10trn TAM”。。。
二十
【As Tesla begins to unlock Dojo synergies in the back half of the decade and beyond 2030, we expect to see meaningful EBITDA margin expansion. We forecast Network Services to deliver a 65% EBITDA margin, and that it will represent 62% of Tesla's total EBITDA in 2040. We can thus imply a 35% total company EBITDA margin in FY40e, up from 15% in FY23e and 24% FY30e.
随着特斯拉在本世纪后半叶以及 2030 年以后开始释放 Dojo 协同效应,我们预计 EBITDA 利润率将出现有意义的扩张。我们预测网络服务将实现 65% 的 EBITDA 利润率,到 2040 年将占特斯拉 EBITDA 总额的 62%。因此,我们可以暗示 2040 财年公司 EBITDA 利润率为 35%,高于 2023 财年的 15% 和 2030 财年的 24% 。
As Network Services, at meaningfully higher margins powered by Dojo, begins to compose a greater share of total company EBITDA, we expect to see a mix shift in EBITDA margin up beyond 2030, similar to AWS' role at AMZN today.
随着 Dojo 推动的网络服务利润率显着提高,开始在公司 EBITDA 总额中占据更大份额,我们预计 2030 年之后 EBITDA 利润率将出现混合变化,类似于 AWS 今天在 AMZN 中的角色。】
好吧,in the back half of the decade
到此我已经看不下去了。全文终。