一 、用到的数据
需要用到的数据
1、全体A股日线数据,用到的字段为 交易日期,股票代码,成交量,成交额,成分股信息(上证50,沪深300,中证500)
2、北向资金中沪/深股通每日持股明细(成分股择时用)
3、北向资金中沪/深股通每日汇总资金信息(原策略,总资金流入择时用)
4、指数日线数据(上证50,沪深300,中证500)
代码中用到库及一些设置
import osimport timeimport jsonfrom glob import globfrom selenium import webdriverfrom lxml import etreefrom pathlib import Pathfrom random import randintfrom urllib.request import urlopenfrom datetime import datetime, timedeltafrom joblib import Parallel, delayedimport numpy as npimport pandas as pd
pd_display_rows = 10
pd_display_cols = 100
pd_display_width = 1000
pd.set_option('display.max_rows', pd_display_rows)
pd.set_option('display.min_rows', pd_display_rows)
pd.set_option('display.max_columns', pd_display_cols)
pd.set_option('display.width', pd_display_width)
pd.set_option('display.max_colwidth', pd_display_width)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('expand_frame_repr', False)
os.environ['NUMEXPR_MAX_THREADS'] = "256" # 设为你的计算机的cpu最大线程数
从东方财富网爬取 北向资金中沪/深股通每日汇总资金信息(d.py)
# =====函数 获取 东方财富网 沪股通 历史日线数据def get_hgt():
# &ps=1000 为设置每次请求多少条记录, 设置太大无法获取数据,设置太小需要增加请求次数
# 按北上数据的 沪股通 历史天数看 设置为1000比较合适
# &p=? 为第几页的数据
url = "网页链接
url = url + "&token=70f12f2f4f091e459a279469fe49eca5&filter=(MarketType=1)&js=var%20hsVSZXUq="
url = url + "{%22data%22:(x),%22pages%22:(tp)}&ps=1000&p=1&sr=-1&st=DetailDate&rt=53437400"
# 先从第一页内容中获取所有页数
contents = get_content_from_internet(url).decode() # 量化课程中内容
contents = json.loads(contents.split("var hsVSZXUq=")[-1])
pages = int(contents['pages']) # 总页数
contents = contents['data']
# 剩余页的data
for p in range(pages+1)[2:]:
content = get_content_from_internet(url.replace("&p=1&sr=", f"&p={p}&sr=")).decode()
content = json.loads(content.split("var hsVSZXUq=")[-1])
contents += content['data'] # 记录 剩余页data
df = pd.DataFrame(contents)
df['DetailDate'] = pd.to_datetime(df['DetailDate']) # 调整为日期
df['MarketType'] = '沪股通' # 明确市场
df['LCGCode'] = 'sh' + df['LCGCode'] # 加股票代码前缀
# 重命名列名
df.rename(columns={
'MarketType': '市场类型',
'DetailDate': '日期',
'DRZJLR': '当日资金流入', # 单位 百万
'DRYE': '当日余额', # 单位 百万
'LSZJLR': '历史累计净买额', # 历史资金流入 单位 百万
'DRCJJME': '当日成交净买额', # 单位 百万
'MRCJE': '买入成交额', # 单位 百万
'MCCJE': '卖出成交额', # 单位 百万
'LCGCode': '领涨股_代码',
'LCG': '领涨股_名称',
'LCGZDF': '领涨股_涨跌幅', # 单位 %
'SSEChange': '上证指数',
'SSEChangePrecent': '上证指数涨跌幅', # 单位 1
}, inplace=True)
df.sort_values(by='日期', inplace=True) # 按时间从小到大排序
df.index = range(len(df)) # 重置index
return df
# =====函数 获取 东方财富网 深股通 历史日线数据def get_sgt():
# &ps=500 为设置每次请求多少条记录, 设置太大无法获取数据,设置太小需要增加请求次数
# 按北上数据的 深股通历史天数看 设置为500比较合适
# &p=? 为第几页的数据
url = "网页链接
url = url + "&token=70f12f2f4f091e459a279469fe49eca5&filter=(MarketType=3)&js=var%20BqGoSWyh="
url = url + "{%22data%22:(x),%22pages%22:(tp)}&ps=500&p=1&sr=-1&st=DetailDate&rt=53437679"
# 先从第一页内容中获取所有页数
contents = get_content_from_internet(url).decode()
contents = json.loads(contents.split("var BqGoSWyh=")[-1])
pages = int(contents['pages']) # 总页数
contents = contents['data']
# 剩余页的data
for p in range(pages+1)[2:]:
content = get_content_from_internet(url.replace("&p=1&sr=", f"&p={p}&sr=")).decode()
content = json.loads(content.split("var BqGoSWyh=")[-1])
contents += content['data'] # 记录 剩余页data
df = pd.DataFrame(contents)
df['DetailDate'] = pd.to_datetime(df['DetailDate']) # 调整为日期
df['MarketType'] = '深股通' # 明确市场
df['LCGCode'] = 'sz' + df['LCGCode'] # 加股票代码前缀
# 重命名列名
df.rename(columns={
'MarketType': '市场类型',
'DetailDate': '日期',
'DRZJLR': '当日资金流入', # 单位 百万
'DRYE': '当日余额', # 单位 百万
'LSZJLR': '历史累计净买额', # 历史资金流入 单位 百万
'DRCJJME': '当日成交净买额', # 单位 百万
'MRCJE': '买入成交额', # 单位 百万
'MCCJE': '卖出成交额', # 单位 百万
'LCGCode': '领涨股_代码',
'LCG': '领涨股_名称',
'LCGZDF': '领涨股_涨跌幅', # 单位 %
'SSEChange': '上证指数',
'SSEChangePrecent': '上证指数涨跌幅', # 单位 1
}, inplace=True)
df.sort_values(by='日期', inplace=True) # 按时间从小到大排序
df.index = range(len(df)) # 重置index
return df
从hkexnews.hk爬取沪/深股通每日持股详情(d.py)
该网站采用ajax架构,我们使用selenium模拟爬取。需要从 网页链接 下载你的chrome浏览器 所对应的 ChromeDriver。windows系统下,将解压的 chromedriver.exe 放到 C:/Program Files (x86)/Google/Chrome/Application 目录下。
# =====函数 基于selenium建立的无头浏览器 从 HKEXnews.hk 获取沪/深股通 一天的 持股详情def get_hs_one_day(_browser, _date):
""" 基于 selenium建立的无头浏览器 从 HKEXnews.hk 获取沪/深股通 一天的 持股详情
需要从 网页链接
下载你的 chrome浏览器 所对应的 ChromeDriver
【windows】
将解压的 chromedriver.exe 放到 C:/Program Files (x86)/Google/Chrome/Application 目录下
:param _browser: selenium 建立的无头浏览器
:param _date: 交易日期 格式为 年-月-日 '2020-08-15'
:return: pd.DataFrame """
# 选择日期框 并点击
datebox = _browser.find_element_by_id('txtShareholdingDate')
_browser.execute_script("arguments[0].setAttribute('value',arguments[1])", datebox, _date.replace('-', '/'))
datebox.click()
_browser.find_element_by_id("btnSearch").click() # 点击搜索
# 获取数据 转 pd.DataFrame
df = pd.DataFrame([
[row.xpath("./td[1]/div/text()")[1], # 股票代码
row.xpath("./td[2]/div/text()")[1], # 股票名称
row.xpath("./td[3]/div/text()")[1], # 持股量
row.xpath("./td[4]/div/text()")[1]] # 持股量百分比
for row in etree.HTML(_browser.page_source).xpath("//div[@id='pnlResult']//tbody/tr")],
columns=['code_hk', 'stock_name', 'shareholding', 'sharehold_p'])
df['market'] = _browser.current_url.split("_c.aspx?t=")[-1] # 添加市场类型
# 重定义国内代码
df['code_hk'] = df['code_hk'].astype(str)
df.loc['9' == df['code_hk'].str[0], 'code_cn'] = 'sh60' + df['code_hk'].str[-4:]
df.loc['7' == df['code_hk'].str[0], 'code_cn'] = 'sz00' + df['code_hk'].str[-4:]
df.loc['77' == df['code_hk'].str[:2], 'code_cn'] = 'sz300' + df['code_hk'].str[-3:]
df['shareholding'] = df['shareholding'].str.replace(",", "").astype(np.float) # 持股量转数值
df['sharehold_p'] = 0.01 * df['sharehold_p'].str.replace("%", "").astype(np.float) # 持股量百分比转数值单位1
df['date'] = pd.to_datetime(_date) # 添加交易日期
# 为适应 量化小讲堂 数据结构不导出 stock_name
return pd.DataFrame(df[['date', 'market', 'code_hk', 'code_cn', 'shareholding', 'sharehold_p']].copy())
# =====函数 获取 hkexnews 沪股通 历史日线数据 个股详情def hgt_detail():
today = str(datetime.now()).split(' ')[0] # 获取今天的日期
# 网页链接 网站最多能获取当前时间一年内的数据
early_day = pd.to_datetime(today) - timedelta(days=365) # 最早能获取的数据的日期
early_day = str(early_day).split(' ')[0]
hdate = list(hgt()['日期'].astype(str)) # 获取沪股通有数据的日期 东方财富网上的已有日线 日期
# data/hgt_detail 目录下的所有日期
hdate_detail = list(map(lambda f: f.split('\\')[-1].split('.')[0], glob("data/hgt_detail/*.pkl")))
# 东方财富网日线数据的日期 - 个股数据的日期 为需要去下载的北向资金的个股数据的日期
date_for_download = list(set(hdate) - set(hdate_detail))
date_for_download.sort()
# 筛选能增量获取的所有日期
can_get_date = pd.DataFrame(date_for_download, columns=['date'])
dates = can_get_date.loc[can_get_date['date'] > early_day, 'date'] # 需要下载数据的日期
if 1 <= len(dates): # 只在需要时才下载
print(f"沪股通个股数据 需要下载 {len(dates)} 个数据")
# 建立 selenium 的 chrome无头浏览器
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome(options=options)
browser.get(f"网页链接) # 加载主网页 sh沪股通 sz深股通
for date in dates:
print('\n\n', date)
db = get_hs_one_day(_browser=browser, _date=date) # 爬取数据
print(db)
db.to_pickle(f"data/hgt_detail/{date}.pkl", protocol=3) # 存储数据
db.to_csv(f"data/hgt_detail/{date}.csv", encoding='utf-8-sig')
browser.quit() # 退出网页
# =====函数 获取 hkexnews 深股通 历史日线数据 个股详情def sgt_detail():
today = str(datetime.now()).split(' ')[0] # 获取今天的日期
# 网页链接 网站最多能获取当前时间一年内的数据
early_day = pd.to_datetime(today) - timedelta(days=365) # 最早能获取的数据的日期
early_day = str(early_day).split(' ')[0]
sdate = list(sgt()['日期'].astype(str)) # 获取深股通有数据的日期 东方财富网上的已有日线 日期
# data/sgt_detail 目录下的所有日期
sdate_detail = list(map(lambda f: f.split('\\')[-1].split('.')[0], glob("data/sgt_detail/*.pkl")))
# 东方财富网日线数据的日期 - 个股数据的日期 为需要去下载的北向资金的个股数据的日期
date_for_download = list(set(sdate) - set(sdate_detail))
date_for_download.sort()
# 筛选能增量获取的所有日期
can_get_date = pd.DataFrame(date_for_download, columns=['date'])
dates = can_get_date.loc[can_get_date['date'] > early_day, 'date'] # 需要下载数据的日期
if 1 <= len(dates): # 只在需要时才下载
print(f"深股通个股数据 需要下载 {len(dates)} 个数据")
# 建立 selenium 的 chrome无头浏览器
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome(options=options)
browser.get(f"网页链接) # 加载主网页 sh沪股通 sz深股通
for date in dates:
print('\n\n', date)
db = get_hs_one_day(_browser=browser, _date=date) # 爬取数据
print(db)
db.to_pickle(f"data/sgt_detail/{date}.pkl", protocol=3) # 存储数据
db.to_csv(f"data/sgt_detail/{date}.csv", encoding='utf-8-sig')
browser.quit() # 退出网页
北向资金每日资金流入流出逻辑梳理(calc_hold_change.py)
假设有连续两个交易日,第一天和第二天,已经知道了这两天的持股详细情况,我们需要知道该交易者针对股票的,从第一天到第二天资金的流入流出情况。
第一天持股详情为
持有股票s1的量为hs1_1
持有股票s2的量为hs2_1
持有股票s3的量为hs3_1
持有股票s4的量为hs4_1
第二天持股详情为
持有股票s2的量为hs2_2
持有股票s3的量为hs3_2
持有股票s4的量为hs4_2
持有股票s5的量为hs5_2
将上述过程转为算法
1、求 day1 和 day2 股票代码的并集 day1and2
2、在 day2 中填充 day1and2-day2的差集 的股票代码 其持仓量为 0
3、在 day1 中填充 day1and2-day1的差集 的股票代码 其持仓量为 0
4、填充后的day2持仓 减 填充后的day1持仓 即为 第一天到第二天的持仓变化
持仓量变化值:若为负,卖出(减持,资金流出); 若为正,买入(增持,资金流入)
# =====函数 计算一个交易日 持仓变化def calc_change(_i, _days, _hs='h'):
""" 计算一个交易日 持仓变化 将结果保存到 对应的文件夹
:param _i: 日期的序号 从第一为到倒数第二位
:param _days: 沪/深股通 所有的交易日期列表 str_list ['2016-06-29', ...]
:param _hs: str h 或 s h代表沪股通 s代表深股通
:return: """
day1_date = _days[_i] # 第一天的日期
day2_date = _days[_i+1] # 第二天的日期
day1 = pd.DataFrame(pd.read_pickle(f"data/{_hs}gt_detail/{day1_date}.pkl")) # 读取第一天数据
day1 = day1[['date', 'market', 'code_cn', 'shareholding', 'sharehold_p']].copy() # 不需要 code_hk 列
day1_codes = set(day1['code_cn'].values) # 第一天的股票代码
day2 = pd.DataFrame(pd.read_pickle(f"data/{_hs}gt_detail/{day2_date}.pkl")) # 读取第二天数据
day2 = day2[['date', 'market', 'code_cn', 'shareholding', 'sharehold_p']].copy() # 不需要 code_hk 列
day2_codes = set(day2['code_cn'].values) # 第二天的股票代码
# 第一天和第二天所有的股票代码
day1and2 = day1_codes | day2_codes # 并集
day2_little = day1and2 - day2_codes # 并集 减 day2
day1_little = day1and2 - day1_codes # 并集 减 day1
if 0 < len(day2_little): # 当并集大于day2时 填充差值到day2的原始DataFrame
for v in day2_little:
idx = max(day2.index)
day2.loc[idx + 1] = [day2['date'][idx], day2['market'][idx], v, 0., 0.]
if 0 < len(day1_little): # 当并集大于day1时填充 差值到day1的原始DataFrame
for v in day1_little:
idx = max(day1.index)
day1.loc[idx + 1] = [day1['date'][idx], day1['market'][idx], v, 0., 0.]
# 填充后 按 code_cn 重新排序
day1.sort_values(by='code_cn', inplace=True)
day1.reset_index(inplace=True, drop=True)
day2.sort_values(by='code_cn', inplace=True)
day2.reset_index(inplace=True, drop=True)
day2['sharehold_d'] = day2['shareholding'] - day1['shareholding'] # 求 第二天的持仓变化
day2 = day2[day2['sharehold_d'].abs() > 1e-3] # 筛选持仓有变化的股票
day2.reset_index(inplace=True, drop=True)
if 0 < len(day2): # 如果不为空数据 就存储该数据
day2.to_pickle(f"data/{_hs}gt_hold_change/{day2_date}.pkl", protocol=3)
day2.to_csv(f"data/{_hs}gt_hold_change/{day2_date}.csv", encoding='utf-8-sig')
print(day2_date)
# === 沪股通
paths = glob("data/hgt_detail/*.pkl") # 沪股通日持股详情 全部文件路径
days = list(map(lambda f: f.split("\\")[-1].split(".")[0], paths)) # 沪股通日持股详情 全部日期
Parallel(n_jobs=8)(delayed(calc_change)(i, days, 'h') for i in range(len(days)-1))
# === 深股通
paths = glob("data/sgt_detail/*.pkl")
days = list(map(lambda f: f.split("\\")[-1].split(".")[0], paths))
Parallel(n_jobs=8)(delayed(calc_change)(i, days, 's') for i in range(len(days)-1))
上述代码获取了每日持仓量的变化,如果我们再查询到day2当天对应股票的均价,就能大致知道,资金流的情况了。这里算出的资金流并不精确。买卖股票时价格是在变化的,我们能获取的价格曲线也只是日线级别的,同时我们也无法确定北向资金中一个股票的持仓变化是在几个时间点以什么价格买入卖出的,我们只能用一只股票的持仓变化乘上当日均价作为资金量。
对该行数据,筛选值>0的即为资金流入市场(买股票);筛选值<0的即为资金流出市场(卖股票)。
对北向资金查询有持仓变化的股票的均价和成分股信息
股票的均价和成分股信息在全A日线数据库中(量化小讲堂中有下载),选择要用到的字段保存为pkl作为查询数据备用。
# =====函数 读取 A股日线数据库中一个股票数据def gen_one_stock(_stock_path):
""" 读取 A股日线数据库中一个股票数据
量化小讲堂中日线股票信息
【沪深300成分股】 股票当天是否是沪深300成分股,如果是则数值为""Y"",否则为空
【上证50成分股】 股票当天是否是上证50成分股,如果是则数值为""Y"",否则为空
【中证500成分股】 股票当天是否是中证500成分股,如果是则数值为""Y"",否则为空
:param _stock_path: A股日线数据库一个股票的全局路径 I:/stock/sh600000.csv
:return: pd.DataFrame """
print(_stock_path)
db = pd.read_csv(_stock_path, skiprows=1, parse_dates=['交易日期'], encoding='gbk')
db = db[['交易日期', '股票代码', '股票名称', '开盘价', '收盘价', '前收盘价', '成交量', '成交额',
'上证50成分股', '沪深300成分股', '中证500成分股']] # 选取需要的列
db.rename(columns={"上证50成分股": "is50", "沪深300成分股": "is300", "中证500成分股": "is500"}, inplace=True) # 简化命名
if not db[['is50', 'is300', 'is500']].isin(["Y"]).any().any(): # 排除不曾是成分股的股票
return pd.DataFrame()
for k in ['开盘价', '收盘价', '前收盘价']: # 数据压缩
db[k] = db[k].astype(np.float32)
# 筛选是成分股的时间段作为返回值
db = db[db['is50'].isin(["Y"]) | db['is300'].isin(["Y"]) | db['is500'].isin(["Y"])].copy()
db.reset_index(inplace=True, drop=True)
return pd.DataFrame(db)
# =====函数 并行读取 A股日线数据库中股票数据def parallel_daily_stocks(_stock_folder, _njobs=60):
""" 并行读取 A股日线数据库中股票数据 保存为一个大的 pkl data/daily_stock.pkl
:param _stock_folder: A股日线数据库 全局路径 I:/stock
:param _njobs: 并行数量 windows 最大设置为 60
:return: """
df_list = Parallel(n_jobs=_njobs)(delayed(gen_one_stock)(path) for path in glob(_stock_folder + "/*.csv"))
df = pd.concat(df_list, ignore_index=True) # 合并为一个大的DataFrame
df.index = range(len(df))
df.to_pickle('data/daily_stock.pkl') # 保存合并的数据
基于生成的全A数据 data/daily_stock.pkl
和沪/深股通的日持股变化数据 data/hgt_hold_change/.pkl data/sgt_hold_change/.pkl
通过pd.merge方法查询到 沪/深股通的日持股变化数据 对应的均价和成分股信息
# =====函数 筛选北向资金日线持股量变化 在上证50、沪深300、中证500成分股中有资金流入流出的数据行
def north_in_50_300_500():
# A股日线数据加载
a = pd.DataFrame(pd.read_pickle("data/daily_stock.pkl"))
a = a[a['成交量'] > 0] # 筛选出交量大于0的数据
a.reset_index(inplace=True, drop=True)
a['price'] = (a['成交额'] / a['成交量']).astype(np.float32) # 计算资金流入流出需要用到
a = a[['交易日期', '股票代码', 'price', 'is50', 'is300', 'is500']].copy() # 减小内存用量
a.rename(columns={'交易日期': 'date', '股票代码': 'code_cn'}, inplace=True) # 简化命名
h_hold_change = pd.concat(Parallel(n_jobs=8)(delayed(pd.read_pickle)(_) for _ in glob(
"data/hgt_hold_change/*.pkl")), ignore_index=True) # 读取 沪股通日持股 变化 详情数据
s_hold_change = pd.concat(Parallel(n_jobs=8)(delayed(pd.read_pickle)(_) for _ in glob(
"data/sgt_hold_change/*.pkl")), ignore_index=True) # 读取 深股通日持股 变化 详情数据
hold_change = pd.concat([h_hold_change, s_hold_change], ignore_index=True) # 合并 沪/深股通持股变化数据
for k in ['shareholding', 'sharehold_p', 'sharehold_d']: # 减小内存用量
hold_change[k] = hold_change[k].astype(np.float32)
del hold_change['market'], hold_change['sharehold_p']
# 生成 A股 和 沪/深股通持股变化 数据的过程文件
# 用于寻找 沪/深股通持股变化数据 在 A股数据中的 映射行
tmp_a = a.copy()
tmp_h = hold_change.copy()
tmp_a['k'] = tmp_a['date'].dt.strftime('%Y-%m-%d') + '_' + tmp_a['code_cn'] # 生成行定位列
del tmp_a['date'], tmp_a['code_cn']
tmp_h['k'] = tmp_h['date'].dt.strftime('%Y-%m-%d') + '_' + tmp_h['code_cn'] # 生成行定位列
del tmp_h['date'], tmp_h['code_cn']
# 将两个过程 DataFrame 合并
c = pd.merge(left=tmp_h, right=tmp_a, on='k', how='outer', indicator=True, sort=True)
c = c[~('right_only' == c['_merge'])] # 选择 沪/深股通持股变化数据 中的行
# 将在 A股 数据中查找到的对应数据 赋值回 持股数据
hold_change['price'] = c['price'].values
hold_change['is50'] = c['is50'].values
hold_change['is300'] = c['is300'].values
hold_change['is500'] = c['is500'].values
hold_change = hold_change[hold_change['price'] > 0] # 筛选会在成分股中有资金流入流出的数据行
hold_change.reset_index(inplace=True, drop=True)
hold_change['amount'] = hold_change['price'] * hold_change['sharehold_d'] # 计算流入流出的资金
# 保存整理的数据
hold_change.to_csv("data/hold_change.csv", encoding='utf-8-sig')
hold_change.to_pickle("data/hold_change.pkl", protocol=3)
print(hold_change)
二、基于成分股的资金流入策略
策略原理及过程和原策略一样,复杂的是数据生成过程,在前面都处理完成了
strategy2_simple_bolling_50_300_500.py
# =====函数 并行读取 A股日线数据库中股票数据if not os.path.exists("data/daily_stock.pkl"):
d.parallel_daily_stocks("I:/stock", _njobs=60)
# ===北向资金 持股变化信息if not os.path.exists("data/hold_change.pkl"):
d.north_in_50_300_500() # 如果尚未生成 北向资金持股变化信息
hold_change = pd.DataFrame(pd.read_pickle("data/hold_change.pkl"))
hold_change.rename(columns={'date': '交易日期'}, inplace=True)print(hold_change)
# ===将北向资金持股变化信息 按日期分组,统计其中在成分股中的资金流入流出
hold_clear = pd.DataFrame(columns=[
'交易日期', # 交易日期
'i50', # 当前交易日 北向资金中 流入 上证50的总资金
'i300', # 当前交易日 北向资金中 流入 沪深300的总资金
'i500', # 当前交易日 北向资金中 流入 中证600的总资金
'i3', # 当前交易日 北向资金中 流入 3个成分股的总资金
'o50', # 当前交易日 北向资金中 流出 上证50的总资金
'o300', # 当前交易日 北向资金中 流出 沪深300的总资金
'o500', # 当前交易日 北向资金中 流出 中证600的总资金
'o3', # 当前交易日 北向资金中 流出 3个成分股的总资金
])
gp = hold_change.groupby(by='交易日期')
idx = 0for k in gp.groups.keys():
print(k)
_ = gp.get_group(k)
hold_clear.loc[idx, '交易日期'] = k
hold_clear.loc[idx, 'i50'] = _[('Y' == _['is50']) & (_['amount'] > 0)]['amount'].sum()
hold_clear.loc[idx, 'i300'] = _[('Y' == _['is300']) & (_['amount'] > 0)]['amount'].sum()
hold_clear.loc[idx, 'i500'] = _[('Y' == _['is500']) & (_['amount'] > 0)]['amount'].sum()
hold_clear.loc[idx, 'i3'] = _[_['amount'] > 0]['amount'].sum()
hold_clear.loc[idx, 'o50'] = _[('Y' == _['is50']) & (_['amount'] < 0)]['amount'].sum()
hold_clear.loc[idx, 'o300'] = _[('Y' == _['is300']) & (_['amount'] < 0)]['amount'].sum()
hold_clear.loc[idx, 'o500'] = _[('Y' == _['is500']) & (_['amount'] < 0)]['amount'].sum()
hold_clear.loc[idx, 'o3'] = _[_['amount'] < 0]['amount'].sum()
idx += 1
hold_clear['交易日期'] = pd.to_datetime(hold_clear['交易日期'])print(hold_clear)
# === i50对应上证50;i300对应沪深300;i500对应中证500for i in ['i50', 'i300', 'i500']:
if 'i50' == i:
index = pd.DataFrame(d.get_index50())
elif 'i300' == i:
index = pd.DataFrame(d.get_index300())
else:
index = pd.DataFrame(d.get_index500())
# 重命名列名
index.rename(columns={
'candle_end_time': '交易日期',
'open': '开盘价',
'high': '最高价',
'low': '最低价',
'close': '收盘价',
'amount': '成交量'
}, inplace=True)
# 数据整理
index['涨跌幅'] = index['收盘价'].pct_change()
index.dropna(inplace=True)
# 为了适应针对股票的择时策略框架,对指数增加触及不到的涨跌停价格以及前收盘价等
index['涨停价'] = index['收盘价'] * 1.2
index['跌停价'] = index['收盘价'] * 0.8
index['前收盘价'] = index['收盘价'].shift()
index['收盘价_复权'] = index['收盘价']
# 筛选最小日期与 hold_clear 相同
index = index[index['交易日期'] >= hold_clear['交易日期'][0]]
index.index = range(len(index))
print(f"\n\n\n\n{i}")
print(index)
# ===将 指数数据 和 北向资金持股变化整理数据 合并
df = pd.merge(left=index, right=hold_clear, on='交易日期', how='outer', indicator=True, sort=True)
print("\n\n合并后的数据")
print(df)
# ===计算资金曲线
# 参数 原参数 252 1.5 完全不行了 选择寻优后的最优参数
if 'i50' == i:
para = [50, 1]
elif 'i300' == i:
para = [10, 0.5]
else:
para = [50, 0.5]
# 计算交易信号
df = f.signal_bolling_north_money(df, para=para, _factor=i)
# 计算实际持仓
df = f.position_at_close(df)
# 计算资金曲线
df = f.equity_curve_with_long_at_close(df, c_rate=1.2 / 10000, t_rate=0.0 / 1000, slippage=0.00)
print(df[['交易日期', 'signal', 'pos', 'equity_curve', 'equity_curve_base']])
# ===策略评价
# 计算每笔交易
trade = f.transfer_equity_curve_to_trade(df)
print('逐笔交易:\n', trade)
equity_curve = df.iloc[-1]['equity_curve']
equity_curve_base = df.iloc[-1]['equity_curve_base']
print(para, '策略最终收益:', equity_curve)
如果策略的数据没错的话
总的来说 效果比原策略差了很多
用最优参数
上证50收益 1.7 左右

沪深300收益 2 左右
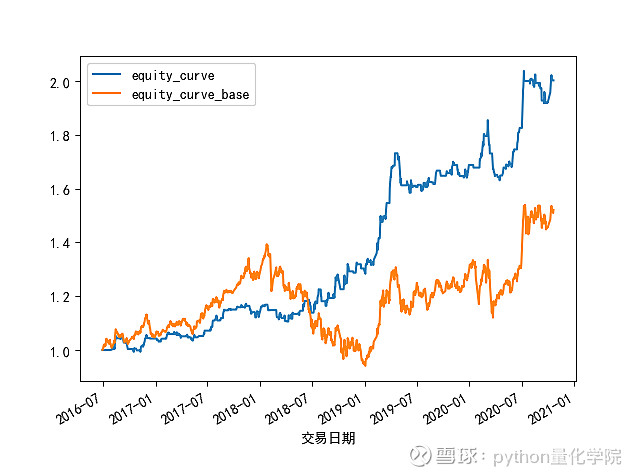
中证500收益 1.67 左右

三、代码及数据
链接:网页链接
提取码:ysta
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++
以上非完整内容