
 芝能智芯出品
芝能智芯出品
在芯片和消费电子领域的激烈竞争中,高通一直以来都在不断发力,力求在芯片性能上占据领先地位。高通对其 Snapdragon X 系列的细节逐步披露,显示出其对于拥有最快 NPU(神经处理单元)的强烈渴望。

Part 1NPU的核心
当前,AI 算力已成为各厂商关注的核心焦点,英特尔 Lunar Lake 的更多细节,其中 NPU 成为重要一环。当这款处理器于第三季度上市时,将提供超过 45 个 TOPS(每秒万亿次操作),这使得英特尔在这方面与高通持平。
AMD 规划的 Strix Point 也能达到 39+ TOPS,三家制造商在这一指标上处于相似水平。
对于所有制造商而言,NPU 作为专用硬件,专为特定计算任务设计,旨在实现高效处理。不过,根据具体任务和数据类型的不同,某些计算仍需依靠 CPU 内核和 GPU 来完成。

高通 SoC 的 Hexagon NPU 是芯片的一部分。相比之下,英特尔的 NPU 位于 SoC 模块中,AMD 的则位于带有 CPU 内核的单片芯片上。
回顾高通的发展历程,其 NPU 已经演进到了第三代。在 2004 年,它们主要处理音频信号,属于 DSP(数字信号处理器)。
而从 2014 年开始,NPU 的速度比 DSP 快了十倍。如今的 NPU 更是在速度上实现了又一个十倍的提升,从而能够承担更复杂、更深入的任务。
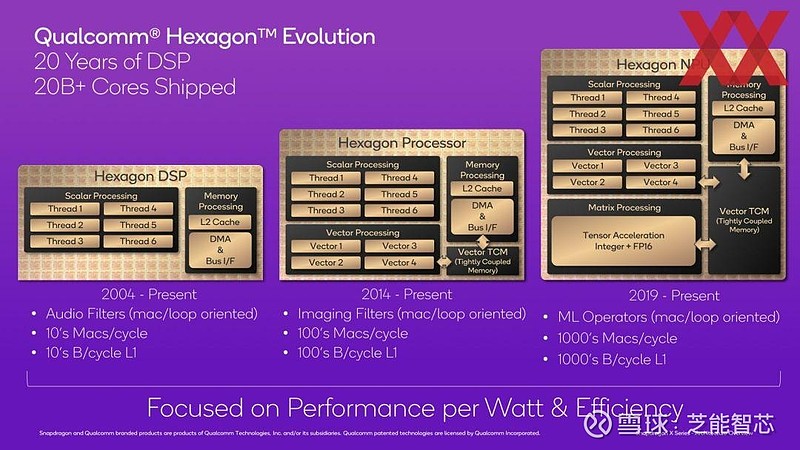
就 NPU 的应用领域来说,目前很大程度上还局限于视频会议中的滤镜,以及图像和视频编辑中的部分效果。
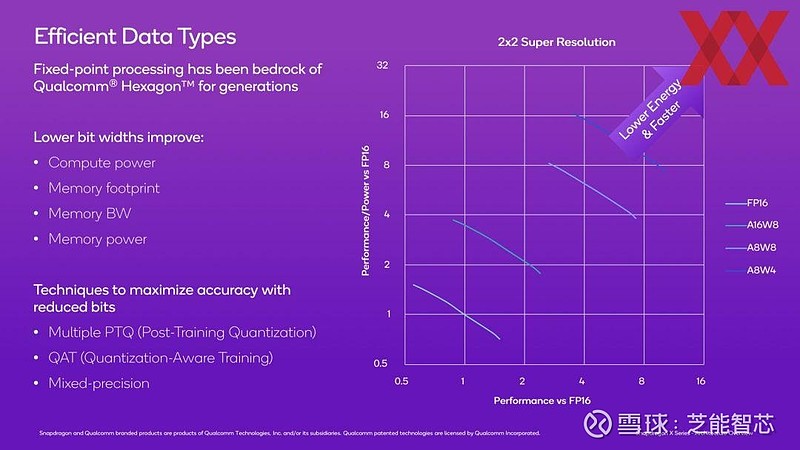
为了提高 NPU 的效率,高通采取了多种措施。其中,尽快连接到 SoC 的内存子系统是关键之一。同时,标量和矢量单元具备以不同精度级别进行计算的能力,除了 FP16 外,还规划了 A8W4、A8W8 和 A16W8 等数据类型,精度涵盖 4 位、8 位和 16 位。

通过多个 PTQ(训练后量化)和 QAT(量化感知训练)来补充,即使数据格式有所减少,仍能保证准确性。开发人员可以利用 HMX(六边形矩阵扩展)和 HVX(六边形矢量扩展)来优化计算,借助微平铺划分张量处理器中的计算单元,实现多个计算的同时进行。

Hexagon NPU 能够同时运行六个线程。相关数据理想状态下位于 NPU 的 L1 和 L2 缓存中,但必要时也可以使用连接的 LPDDR 内存,只是这样会导致额外的延迟,应尽量避免。
在 Procyon AI 基准测试中,Snapdragon X Elite X1E-80-100 的 NPU 速度几乎是 MacBook Pro 中 M3 的两倍,Intel Core Ultra 7 155H 则明显落后。
同时,高通的 SoC 功耗仅为 7.6 W,而 M3 为 9.7 W,英特尔的 Core Ultra 处理器更是达到 11 W。

Part 2高通的测试表现
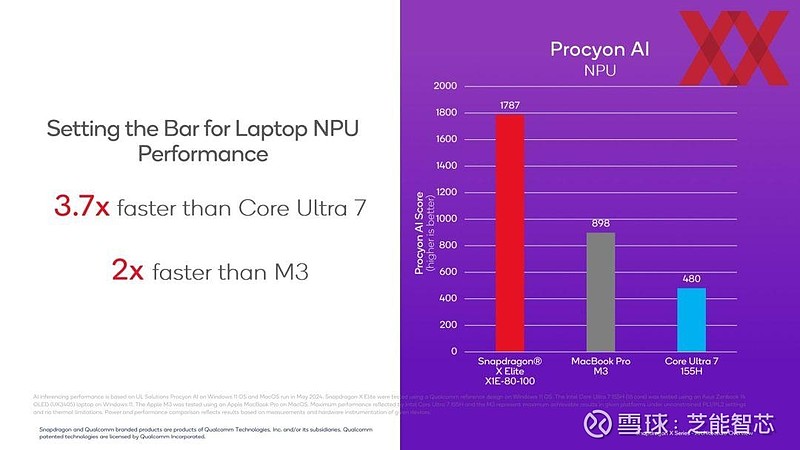
高通在进行比较时,只能使用已有的基准测试硬件,与英特尔的 Meteor Lake、AMD 的 Ryzen 7000 和苹果的 M3 等进行对比。而当相关笔记本电脑上市后,新的继任产品也会很快出现。从纸面上看,高通所提供的技术数据和性能值表现出色。
尽管一些新闻代表已经被允许运行部分基准测试,但这些参考系统是在高通定义的环境中提供的,且只允许运行制造商选定的基准测试,所以不能称之为独立的价值评估。
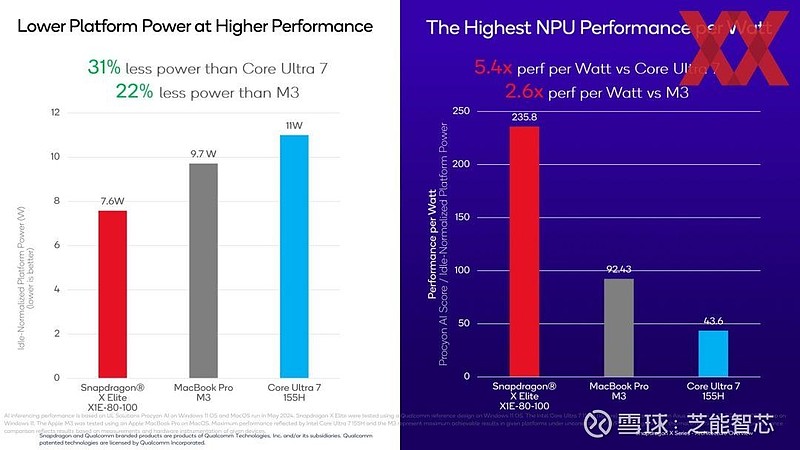
高通终于逐步揭开了其技术的神秘面纱,对于很多用户来说,NPU 的份额在一开始可能并非关键因素。PU 的强大性能可能意味着在处理特效和滤镜时能够极大地提高工作效率,节省时间。但对于普通消费者,可能更关注的是整体的使用体验、电池续航等方面。
小结
高通在追求最快 NPU 的道路上不断努力,但在市场接受和实际应用效果方面,仍有待时间和更多独立测试的检验。