

芝能智芯出品
随着语音用户界面(VUI)系统的广泛应用,语音反欺骗技术正变得越来越重要。这些技术旨在防止涉及模仿声音的诈骗行为,并改善VUI系统的整体用户体验。

Part 1什么是语音反欺骗?
语音反欺骗是一套防止语音模仿诈骗的技术,尤其针对以下几种常见的语音欺骗方式:
● 语音合成 (SS):利用计算机模拟目标语音进行攻击。
● 语音转换 (VC):通过过滤器和其他工具,使冒名顶替者的声音尽可能接近目标的声音。
● 重放攻击 (RA):使用预先录制的受害者声音样本进行攻击。
● 模仿:攻击者模仿受害者的语音特征,如音调、韵律和词汇。
● 干扰触发:人工声音意外触发系统,导致用户不便。
语音反欺骗技术的工作原理
语音反欺骗系统通过检测和阻止录制的、计算机生成的或计算机修改的声音来防止欺骗行为。
其主要组成部分包括:
● 关键词检测:系统识别特定的唤醒词或命令,例如“Hi Renesas”。
● 特征提取:从语音信号中提取音色、发音、语调和词汇等特征。
● 语音欺骗检测 (SSD):使用算法检测重放攻击等语音伪像。
● 分类:将语音分类为真实语音或录音。
通过这些技术,语音反欺骗系统可以有效抵御不同类型的语音欺骗攻击,提升用户体验,瑞萨电子的语音反欺骗功能结合了RA MCU系列和Reality AI生成的模型,实现了高精度和快速响应。
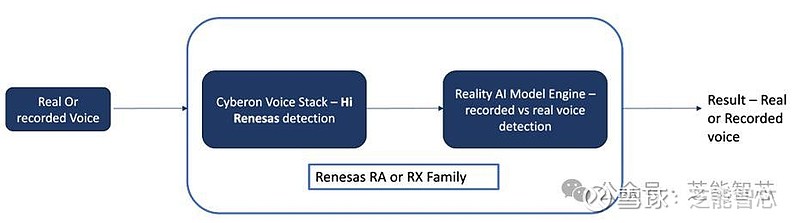
Part 2语音反欺诈的应用示例
瑞萨电子与Cyberon和Reality AI合作开发的语音反欺骗解决方案,通过“Hi Renesas”唤醒词检测,实现了高达99%的训练K-Fold验证准确率和96%的实际测试准确率。这种解决方案在智能门铃等设备中,能够有效识别和防止语音欺骗攻击,确保用户的安全和便利。
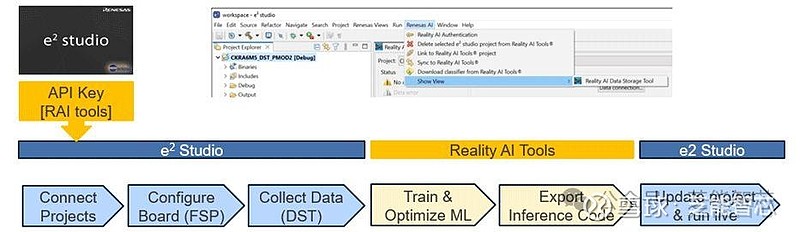
利用瑞萨电子的IDE e² studio,用户可以收集语音数据,集成Cyberon的语音堆栈进行唤醒词检测,并使用Reality AI Tools生成的AI模型。以下是具体步骤:
● 数据收集:通过瑞萨硬件麦克风录制真实语音数据。
● 特征提取和训练:使用Reality AI的引擎开发模型,达到99%的训练准确率。
● 模型集成:将模型集成到e² studio项目中,并在实际环境中进行测试,确保96%的测试准确率。
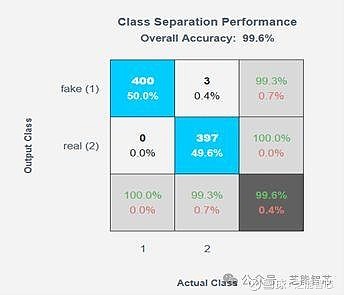
这种方法不仅提高了语音识别的精度和速度,还增强了系统的安全性,防止仿冒语音的诈骗行为。
小结
瑞萨电子的语音反欺骗解决方案展示了通过Reality AI Tools应对现实挑战、改善用户体验的能力。这些小巧而高效的AI模型,可以通过灵活的数据收集和训练进行扩展,进一步提升VUI系统的适应性和安全性。
通过这种创新的技术,智能门铃和其他VUI设备将变得更加可靠和安全,为用户提供更好的服务体验。