一,源头
海光的DCU源自AMD的MI100芯片,招股说明书有描述
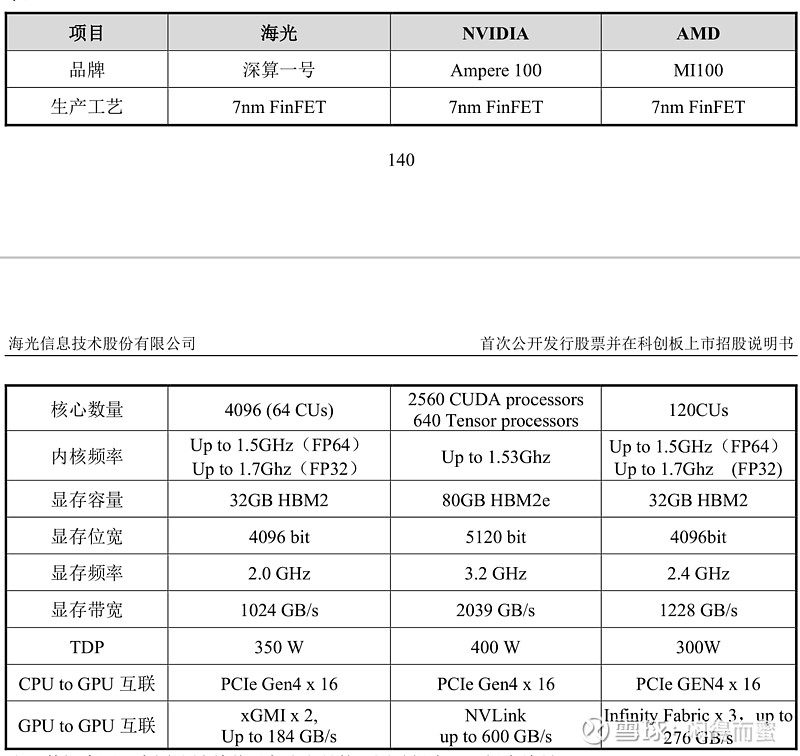
从源头可以看出,海光DCU是Mi100的裁剪版,裁剪50%的性能。
二,性能对比
那么Mi100的性能怎么样呢?将Nivida A40、AMD Mi100、海光DCU 对比如下:
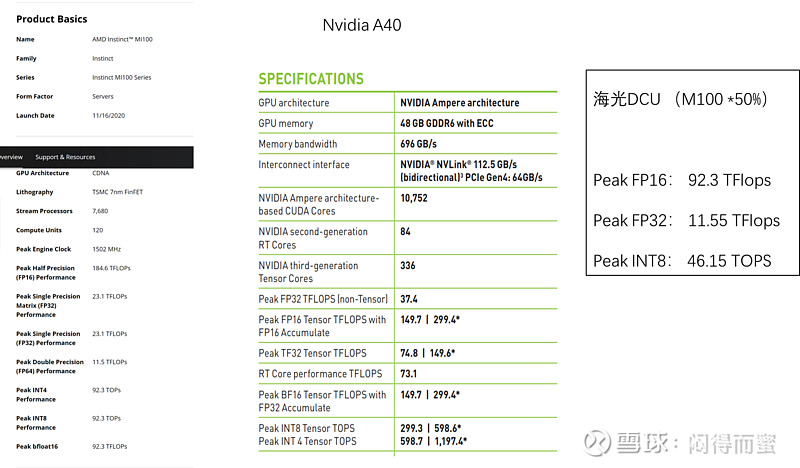
根据同比例换算后得出上述的对比数据。 所以海光DCU大概是Nvidia 上一代推理芯片A40的61%(训练场景,A40本来用于推理的,训练不擅长)、15%(推理场景)。
那么跟国产算力比怎么样呢? 以寒武纪为例:
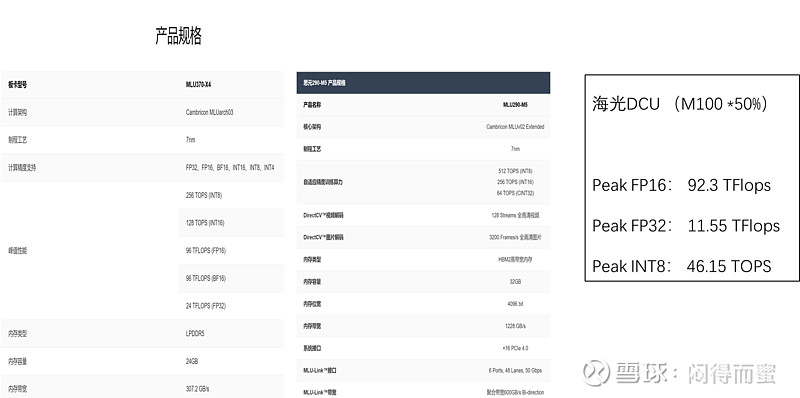
从上图可以看出,跟寒武纪的训练芯片370比(训练主要看FP16、FP32),大概在70%左右,而跟寒武纪的推理芯片比(推理主要看INT8),性能只有10%左右。
三、关键痛点
海光DCU从Mi100授权过来时,把GPU的互联接口(类似NVlink)从AMD的Infinity Fabric缩减成了xGMI接口(显卡场景),导致最多只能两颗GPU直联。因此无法组成大规模阵列(Nvidia A100可以16GPU集群,H100 256GPU集群),基本上丧失了训练能力。
总结:
1、不适合做训练,尤其不适合做大模型的训练(a、浮点性能低;b、无法集群组网)
2、推理场景性价比很低,大概是2022年代主流专用推理芯片的10%~15%性能。
3、Mi100是用于对标A100的,本来就拼不过,授权给海光时,把与训练有关的性能和关键特性做了裁剪,导致高不成(训练)低不就(推理)。
(说明:上述分析仅仅根据有限的公开披露信息推理,因为信息不全,存在不严谨,甚至结论错误的可能,所以只供交流讨论,不做投资建议。)
$上证指数(SH000001)$ $创业板指(SZ399006)$ $海光信息(SH688041)$
精彩讨论
奴役的自由人03-10 09:52作为专业人士,必须指出几个错误:
1.dcu 技术来源于vega20架构,对应AMD MI50。
2.不存在把 Infinity Fabric 改成xgmi,这两个东西就不是同一个玩意,一个是芯片内的io总线,一个是卡互联。
3.卡互联有多种方式,nvlink /xgmi 只是其中一种。xgmi 卡间互联主要看卡做几个接口(做一个当然就是两卡互联)。多机更大节点可以通过 ib 卡互联,H100 超过256 也得用ib 卡
另外,海光dcu第一款定位是用于超算中心,超算主要是科学计算,对fp64 的要求更高。当然也可以用来跑训练和推理,这个对fp32/fp16/int8 要求高点。
dcu 架构虽然来自amd 几年前的,但是在通用gpgpu 架构上,国内基本还是遥遥领先。
华为/寒武纪 基于asic 的npu 虽然算力高,但是可编程较差。asic 可以理解为一些AI计算已经固化好没法修改,gpgpu 则需要软件人员自己写代码实现
闷得而蜜03-10 09:49一个事实,海光的芯片版图制作、投片等最核心的工作,必须交由美国控制的外资控股企业去做,你就只能在人家的模块上打补丁,然后一堆人不停地洗白,还挟持爱国主义情怀,赚这些肮脏的钱。最疼恨这些麦办,披着爱国的外衣,干着麦办的实质。$海光信息(SH688041)$
艺术家Simon03-09 23:05不能只看涨幅,估值给的最高才是抱得最狠的那个,实际上寒武纪和海光才是ai抱团最狠的算力。
闷得而蜜03-09 23:23如果一定要把“GPGPU”作为挡箭牌,恰恰说明海光的DCU芯片只能用AMD的架构和版图去演进,不可能自主创新,因为你没有得到授权。19年后,即使能够拿到授权,也是严格管控的,根本不可能有网上传那么好的性能数据出来。 到处都是自相矛盾。
雪神曲玛丽03-12 14:19从首次披露回购预案来看,当日共6家公司股票回购预案金额超千万。海信视像、利亚德、牧原股份回购预案金额最高,分别拟回购不超7.53亿元、6000万元、3134.64万元。从股东大会通过回购预案来看,当日共4家公司回购预案超千万。智飞生物、绿通科技、蓝帆医疗回购金额最高,分别拟回购不超5亿元、1.5亿元、5000万元。
不要听那些买办的话术。 世界上所有的芯片都是ASIC。
什么样的课题,就用什么样的架构。能够高效解决问题的架构就是好架构。
GPU,GPGPU,原因是NVidia当年做显卡出生,他的芯片都叫Graphic process unit。 而到了AI时代,他还是继续沿用 GPU这个名词,但是为了显示在AI、科学计算等领域的作用,就变成了GPGPU, general purpose GPU。
只要能够做到大规模并行计算、提供矢量、张量的加速能力,都是GPGPU。
有些买办,为了彰显自己所依附对象的尊贵地位,故意用这些话术来压制真正的自主创新。舔。海光信息
所以寒武纪也跌了,跌就是一起的,海光太贵了
全部讨论
一个事实,海光的芯片版图制作、投片等最核心的工作,必须交由美国控制的外资控股企业去做,你就只能在人家的模块上打补丁,然后一堆人不停地洗白,还挟持爱国主义情怀,赚这些肮脏的钱。最疼恨这些麦办,披着爱国的外衣,干着麦办的实质。$海光信息(SH688041)$
找几张表格大言不惭的写一篇(韭菜级独家)简评,看看海光信息有多少家卷商机构去到公司做深入调研,各大指数基金背后没有专业调研么? 就你看见这一点点信息就以为自己得到真理了,真是可笑
如果一定要把“GPGPU”作为挡箭牌,恰恰说明海光的DCU芯片只能用AMD的架构和版图去演进,不可能自主创新,因为你没有得到授权。19年后,即使能够拿到授权,也是严格管控的,根本不可能有网上传那么好的性能数据出来。 到处都是自相矛盾。
哥们,别独家了,你这数据太老了,现在都在小批量试用深算三号了$海光信息(SH688041)$
作为专业人士,必须指出几个错误:
1.dcu 技术来源于vega20架构,对应AMD MI50。
2.不存在把 Infinity Fabric 改成xgmi,这两个东西就不是同一个玩意,一个是芯片内的io总线,一个是卡互联。
3.卡互联有多种方式,nvlink /xgmi 只是其中一种。xgmi 卡间互联主要看卡做几个接口(做一个当然就是两卡互联)。多机更大节点可以通过 ib 卡互联,H100 超过256 也得用ib 卡
另外,海光dcu第一款定位是用于超算中心,超算主要是科学计算,对fp64 的要求更高。当然也可以用来跑训练和推理,这个对fp32/fp16/int8 要求高点。
dcu 架构虽然来自amd 几年前的,但是在通用gpgpu 架构上,国内基本还是遥遥领先。
华为/寒武纪 基于asic 的npu 虽然算力高,但是可编程较差。asic 可以理解为一些AI计算已经固化好没法修改,gpgpu 则需要软件人员自己写代码实现
我咨询了中科院的朋友,海光和寒武纪同为中科系的。海光现在的技术能力确实不行,和华为、寒武纪比差距较大。产品参数落后太大。未来海光发展方向也是向嵌入式发展。您可以去了解一下。纯技术交流。
懂个鸡毛 深算2/3国内对标全精度英伟达GPGPU 寒武纪和华为是NPU 不是全精度,类Cuda只会海光,华为寒武纪那是不同的系统