文/张健
对于全球自动驾驶行业,特斯拉FSD v12的量产推送是重要分水岭。
端到端神经网络架构,将带来迭代范式和开发逻辑的演变,以及企业所需能力和资源投入的深刻变化。
相比FSD以前的版本,这回能够继续跟进的玩家将会屈指可数。那些有能力跟进的,将组成第一集团并拉开与其他厂商的差距。对自动驾驶“皇冠上的明珠”的争夺,也将在这寥寥数家之间展开。
全球范围内,有能力跟进FSD的整车厂商,全部在中国。
在刚过去的2023年,中国智驾行业的焦点是头部造车新势力和华为的“城市NOA开城大战”。然而,无论是华为的“全国都能开”,还是小鹏的224城,还是理想的110城,还是蔚来的“65万公里”,都无法彰显高人一筹的领先性。
这是因为,各家的产品进度虽有先后,但技术成熟度都处在追赶特斯拉FSD v11的阶段——从时间维度看,大致相当于FSD在2022年11月的状态。
如今FSD v12已经展现出了完全数据驱动带来的迭代速度优势,中国厂商们跟进端到端架构刻不容缓。
事实上他们已经在行动了——1月30日,何小鹏明确表示小鹏智驾的下一步目标是端到端模型全面上车;而据媒体报道,蔚来将在今年上半年推出端到端架构的主动安全功能,理想的端到端AD智驾系统也计划在今年上线。
为什么一定要转向“端到端”呢?它究竟是一个营销词汇,还是通向自动驾驶的圣杯?
一、为什么要“端到端”
在AI神经网络的早期发展阶段,人们倾向于认为应该“让神经网络做尽可能少的事”。例如,在将语音转换为文本时,人们认为应该先分析语音的音频,再将其分解为音素,等等。但是后来发现,(至少对于“类人任务”)最好的方法通常是尝试训练神经网络来“解决端到端的问题”,让它自己“发现”必要的中间特征、编码等。
——摘自《这就是ChatGPT·神经网络训练的实践和学问》,作者Stephen Walfram
一个逐渐凝聚的共识是,传统的自动驾驶技术架构,虽在过去几年做到了持续降低接管率、提升ADAS辅助驾驶体验,甚至在特定地理边界内实现了Robotaxi运营,但终究无法实现像人类司机那样“在任何道路都能开”的自动驾驶。
在实践中,传统的技术架构主要凸显出以下几个问题:
1.“分而治之”的模块化架构,可能圄于局部最优解而难以达到全局最优。
当前主流的自动驾驶系统,将“感知、预测、规划、控制”四个任务细分为探测跟踪、静态环境建图、高精定位、动态物轨迹预测、自车轨迹规划、运动控制等模块。
基于此种“分而治之”的架构,在车企的智驾研发部门,每个模块分别由不同的团队负责。
由于每个任务相对独立、容易解决,人工标注使数据的针对性强,监督学习使模型训练的信号强,因此AI模型能迅速提升性能,有利于快速实现一个完整的产品。但在到达“局部最优解”之后,这些模型难以进一步提升,且串在一起之后形成累积误差,不利于追求全局最优解。
假如能利用深度神经网络的属性,将各个模块用可微分的方式连接起来进行梯度回传,出现误差时,以最小化整体损失函数为目标更新权重,就可实现端到端全局优化。
端到端架构将所有模块串在一起统一训练,更利于追求“全局最优解”,但数据的针对性更弱、模型训练的信号更弱,意味着提升性能所需的数据量和算力规模更大。
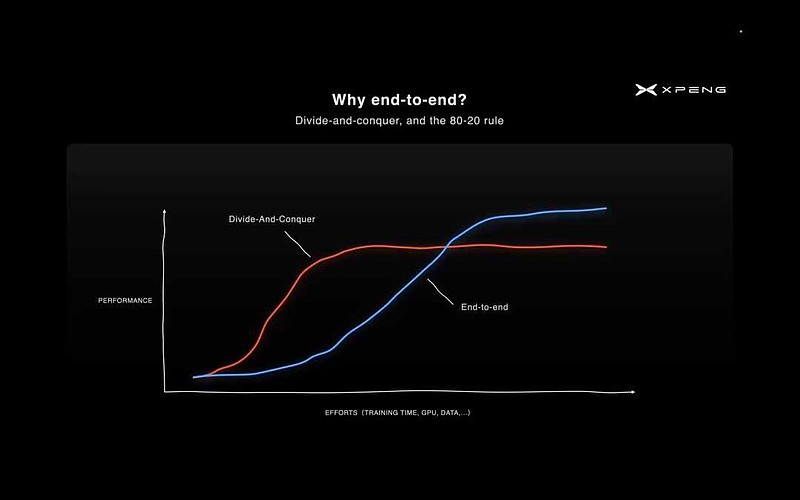
图片来源:2023年CVPR,刘兰个川,(时任)小鹏XPilot感知首席工程师
2.基于人工代码的规控模块,无法穷尽驾驶场景中的corner case,且难以做到车辆动作的“拟人”。
在传统的决策规划框架中,研发人员会根据不同的ODD定义好规则,面对特定场景时找到对应的规则,然后调用相应的规划器生成控制轨迹。
这种架构需要事先写好大量的规则,故称为“重决策方案”。
重决策方案较易实现,在简单场景下也堪称高效,但在需要拓展ODD、或把不同的ODD连接起来时,就需要大量的手写规则来查缺补漏,从而实现更连续的智驾体验。
这样做的弊端很明显:当遇到未学习过的场景,即corner case时,系统会表现得不够智能甚或无法应对。同时,开发者需要维护大量的if-else(判断逻辑)来做场景细分,开发测试周期长、成本高。
举个例子:处理加塞时,重决策方案需要根据对旁车姿态的计算,匹配事先写好的规则(如旁车的横摆角达到多少度、旁车车轮是否压线等)来做出是否减速让行的决策。然而,车辆并线的场景千差万别无法穷尽,要想提升加塞应对能力,就得无穷无尽地增加规则,代码越写越长。
重决策方案,本质上是用数学/几何计算的方式判断人类驾驶员的动作和意图并应对之。确定的规则和精确的控制参数,导致车辆动作机械化、不拟人。
与规则代码不同,神经网络的本质属性是学习。在上述判断加塞的例子中,神经网络不会明确地计算旁车横摆角的数值,而是通过学习车轮、车灯、车道线,以及环境中的其他特征,判断旁车的加塞意图。
人们并不知道神经网络内部是如何工作的,其判断旁车是否加塞、该何时做出应对,均是基于(人类无法看懂的)中间特征和编码。
简单说,神经网络是一个黑盒,但在完成拟人化任务方面比规则代码更奏效——网络上的实测视频显示,FSD v12展现出了一些v11从未具备的能力和特征,例如行驶中自行绕开路面上的积水,或是到达设定目的地后,自行在附近街区寻找车位直至泊入等。
3.不断积累的手写代码,与追求更简洁系统的目标相悖。
规划和控制模块是自动驾驶系统的“代码重灾区”,特别是针对交通参与者多样、行车环境复杂的城市场景。
小鹏汽车曾在2022年10月透露,其城市NGP在预测、规划、控制模块的代码量是高速NGP代码量的88倍。与之对比,城市NGP总体代码量是高速NGP的6倍,而感知模块的神经网络模型数量是高速NGP的4倍。
时至今日,各家已初步实现了感知模块的AI化,预测模块次之,规控模块则是最难啃的骨头。
关注FSD的读者,一定对其历来详细冗长的更新日志不陌生。然而到了v12,更新日志只剩下短短一句话:
FSD Beta v12对城市街道驾驶栈进行了单个端到端神经网络的升级,这个神经网络基于数以百万计的视频片段训练而来,替换了超过30万行明确编写的C++代码。
为什么要追求更简洁的系统架构?
马斯克曾在Lex Fridman采访中表示,当前用计算机实现的智能非常费电——人类的高级脑部功能(Higher Brain Functions)只要不到10W的功率。即使只有10W,这个人脑仍能写出比10MW的GPU集群更棒的小说,能效比后者高6个数量级。
就自动驾驶系统而言,当前的特斯拉FSD功率约为100W,马斯克相信未来可以做到50W以下。
开发任何一项新技术,都是先让它可行,再提高它的效率。
对任何一款汽车产品,在同等性能下,每降低一个kg、kW、TOPS,都是对效率和成本的巨大优化。
例如,小鹏XNGP技术架构中,原本仅负责动态感知的XNet就要耗费一颗OrinX算力的122%,最终经过优化仅用9%的OrinX算力就实现了同样功能——省下来的车端算力,可用于更多功能或更强性能。
结构更简化的自动驾驶系统,有利于降低车端功耗和成本,这一点即使在端到端大模型的时代也仍然成立。
正如马斯克的经验分享:the more effort in training, the less effort needed in inference.云端训练遵循scaling law的大参数、大数据、大算力,成熟后部署到车端的模型则越小越好。
综上,端到端系统的结构更简单优雅、性能上限更高、应对长尾问题(corner case)的能力更强,因此被视为自动驾驶技术架构的最终形态。
二、特斯拉是如何做的
在特斯拉FSD v12之前,端到端方案仅停留在理论层面——学术界虽不乏优秀论文,但工业界普遍认为量产尚远。
在特斯拉内部,端到端项目于2022年12月立项。这不得不让人联想到GPT的时间线——OpenAI于2022年11月底上线ChatGPT,仅不足一个月后特斯拉就上马“端到端”,一个合理的推测是,Scaling Law在大语言模型上的奏效,坚定了特斯拉Autopilot团队探索端到端的信心。
最开始马斯克是有怀疑的——他认为“无需火箭打苍蝇,用苍蝇拍就够了。”
四个月之后的2023年4月中旬,马斯克试驾了当时的v12版本,对效果非常满意。在由20多个身穿黑色T恤的Autopilot团队成员参加的总结会上,马斯克注意到一个核心信息:端到端方案最开始的效果并不好,直到它学习的高质量视频片段(Clip)超过100万个,体验才出现了显著跃升。
2023年8月26日,马斯克在X平台上进行了一段时长45分钟的FSD v12试驾直播。他在直播中表示,这是有史以来第一个端到端AI自动驾驶系统,是特斯拉FSD迄今为止最重要的一次升级:
“没有一行代码告诉它减速通过减速带,没有一行代码告诉它避让骑自行车的人,没有一行代码要求它在停车标识前停下、或是等待另一辆车、或是需要等待几秒……什么规则都没有,它完全是在学着做人类做的事情。我们完全是通过视频训练来实现这一切的,完全通过人工智能和摄像头,就像人类完全通过眼睛和大脑(来实现驾驶)一样。”
在直播中与马斯克同行的Ashok Elluswamy解释说,虽然v12不再通过代码来编程,但可以通过填喂不同的数据来调整模型的参数(不失为另一种形式的“编程”)。
端到端的FSD跑通了!业界纷纷侧目,有人惊叹有人质疑,特斯拉继续狂飙:
2023年11月25日,马斯克证实,特斯拉已向内部员工推送了FSD v12进行内测。
2023年12月24日,特斯拉又向员工推送了更新的v12.1版本,有消息称推送人数已扩展到1.5万人。
2024年1月23日,特斯拉首次将FSD v12推送给美国的少量媒体人(据称规模在100人左右),版本号为v12.1.2。
到了2024年2月19日,特斯拉首次向普通车主推送FSD v12。据Teslascope报道,这一轮推送名单采用随机选取的方式,收到推送的车主约占FSD全量用户的0.5%-2%。
若以50万FSD全量用户计,这意味着目前收到v12的普通用户规模在2500人到1万人之间。
虽然当前推送率仅有不到2%,但从特斯拉采用随机选取用户(而非两年前v10时的基于安全驾驶评分)的方式看,其对v12的成熟度已颇具信心。
从网络上流出的很多测试视频看:相比v11,转成端到端后,v12在部分基础体验上出现了倒退,例如当它“独自一车”行驶在空旷笔直的大道上时,它会时而加速、时而减速,反而不如跟随其他车辆时来得平稳。但在处理更难的问题——例如复杂场景博弈、绕过路面上的积水、窄路错车等——时,v12却表现得自信流畅,颇像一个人类司机。
这些特性,与ChatGPT横空出世时何其相似——它会犯(让人难以理解的)低级错误、会产生幻觉,但它同时也展现出前所未有的拟人性和巨大的提升潜力(有GPT-4相比ChatGPT的巨大提升为证)。
怀疑的人们,会继续将放大镜对准v12表现不佳的案例,但相信的人们在呐喊:“它才刚刚训练了1年啊!想想5年后、10年后会怎样?”
特斯拉究竟是如何做出了自动驾驶界的ChatGPT呢?
遗憾的是,截至目前,特斯拉并未公开分享过端到端架构的细节,甚至连会否在2024年举行新一届AI Day,都还不明朗。
但基于已知信息,笔者尝试对FSD v12做下述解读,以供探讨:
回顾2022年12月这个节点:FSD的感知模块在当时已经是成熟的神经网络模型,预测部分也已完成了AI化。特斯拉要做的就是把规控也变成神经网络——即训练一个Planner模块,给它大量5星司机的驾驶数据,让它模仿人类的驾驶行为,输出控制信号。
换句话说,FSD v12采用的端到端方案,并非完全摒弃v11版本中的成果而从头打造一个单一的神经网络模型,而是将旧版本中各模块的小模型加以聚合、重组,再增加一些新的AI模块、去除一些不再适用的旧模块,最终将此前的规则代码全部替换成神经网络模型。
深度神经网络固有的特性也支持这样的聚合——在设计神经网络时,一个新的网络可以直接包含另一个已经训练过的网络。当整个技术栈都替换成神经网络之后,运用反向传播法进行训练,就可以将整个系统视为一个统一的“端到端”神经网络模型。
2月25日,X平台上的知名特斯拉黑客“绿神”发布了自己观察到的信息,侧面证实了以上猜测:
在目前的FSD v12.2.1中有231个神经网络,但其中一些是更大的“复合”网络的一部分,所以特斯拉将它们算作一个网络。
还有,几乎每个网络都有复制品,分为prod(量产)和experimental(试验)版本,但我最后一次检查时,它们是完全相同的。

三、要跟进,难在哪?
特斯拉跑通FSD v12的难度究竟何在?这里通过三个方面粗浅解析:
1.“端到端”神经网络的设计无法一蹴而就:
推送日志对FSD v12的描述看似是一场推翻重建,但实际上是前序版本中的每一步工作促成了下一步工作、下一个版本,最终发展到完全由神经网络构成。
过去几年,是手写代码让FSD v9、v10、v11成功地在道路上行驶,收集到大量真实数据,从而训练出了处理无数小任务的模型,开发过程中再不断将这些模型聚合、重组,最终形成了组成v12的模型。
这些工作的完成,并不是一个直截了当的过程。
一名人工智能从业者向笔者介绍:设计一个可工作的推理神经网络需要大量的专业知识,而训练它就更复杂了。例如,需要选择合适的输入/输出信号、归一化、偏差、神经网络层数、每层神经元数量、非线性输出函数(例如 RELU)……并且整个系统中的许多神经子网络都可能涉及这些问题,工作量巨大。
2.设计完成后,对模型的训练并非“无需人工参与的”自动化过程:
“分模块”变为“端到端”之后,之前的测试、改进手段都失效了,需要重新设计。
“端到端神经网络”仅是指从视频输入到控制信号输出的整个技术栈不再包含手写代码,但在训练模型时,仍需人类工程师手写代码来完成筛选数据、处理数据、组织模型训练等工作(如下图所示——其中绿色为手写代码,红色为神经网络)。
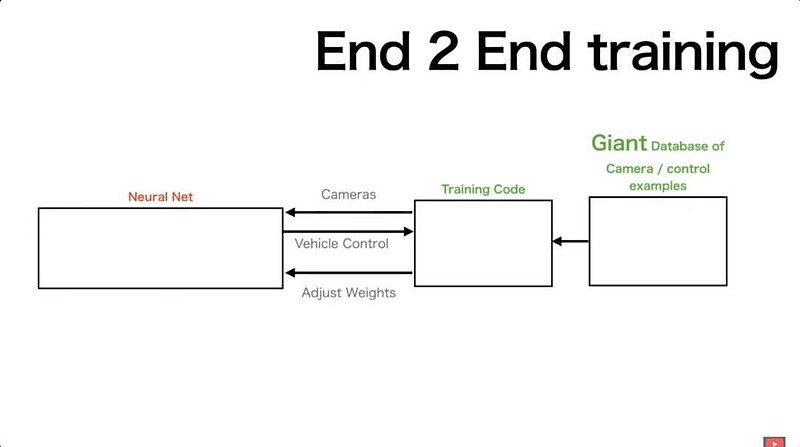
图片来源:James Douma
这些工作,无不需要基础知识扎实、经验丰富的工程师团队花费大量精力反复试错验证。
3.端到端架构需要投入更多资源和资金:
Andrej Karpathy还在特斯拉时,因为还处在“分模块”阶段,也因为他是一个“强训练信号”(strong training signal)的信徒,所以其方式是花很大人力清洗、组织数据,用监督训练的方式训练模型,这样模型的能力会提升得很快,但上限不高。
而端到端架构下,上述训练方式不再适用,换成用更大量的数据、自监督的方式进行训练,对模型多个方面的能力进行“缓慢的、潜移默化的”提升,提升速度慢但上限更高。
更大的数据带宽(包括绝对数据量和数据的筛选、清洗、标注、传输、存储等能力)、更大算力的超算基础设施,以及训练和部署更大参数量的模型的能力——每一项都意味着更高额的资金投入和人才密度更高的团队。
其中,数据量和算力(资金)的劣势,可能是当前中国厂商追赶特斯拉的最大障碍。
数据方面,截至2023年12月,特斯拉FSD Beta的累计行驶里程为8亿英里(12.9亿公里)——这是从2022年12月时的9000万英里爬升仅1年的结果。
与之相比,中国智能电车累计销量最大的理想汽车,NOA历史累计里程为5.6亿公里(包括高速NOA和城市NOA)。
当然,要强调的是,绝对数据量并非成功的充要条件。要从每年10亿英里(16亿公里)级别的行驶数据中筛选出用于训练的有效数据,世界上没人有过这样的经验——特斯拉也同样在探索当中。
算力方面,根据公开信息,部分厂商的训练资源如下:
特斯拉 10 EFLOPS(2023 年 8 月)
华为2.8 EFLOPS(2023 年 11 月)
极越(百度):1.8-2.2 EFLOPS(2024年2月)
蔚来1.4 EFLOPS(2023 年 9 月)
理想1.2 EFLOPS(2023 年 6 月)
2024年,特斯拉仅计划在超算集群上的投入就接近15亿美元(包括5亿美元Dojo、5亿+美元英伟达H100,以及未知金额的AMD芯片),目标是到2024年底达到100 EFLOPS。
与之相比,小鹏汽车2024年计划投向智驾等AI技术的总研发费用约为35亿元人民币。
可以说,自动驾驶转向“端到端”,不仅是一个技术问题,更是智能电动车企业最核心的战略问题之一。如何掌握节奏、合理分配资源,以保持自身的持续竞争力,是各家都在面对的挑战。
总结
经过特斯拉、华为、小鹏、理想、蔚来等厂商的量产探索,自动驾驶技术在分模块的架构下取得了长足进步。期间,中美两地的开发团队积累了大量研发、测试、验证、量产的经验,一大批AI人才与汽车工程人才完成了相互的融合与滋养。
2024年,特斯拉FSD v12的量产是一个新起点,标志着自动驾驶技术切换到数据驱动的开始,能继续跟进的玩家不会太多了。
在接下来的对决中,数据能力将是本质的决胜因素,算法能力和算力资源则是参与竞争的基础。