
$芯原股份-U(SH688521)$ $寒武纪-U(SH688256)$ $景嘉微(SZ300474)$
这几天每天复盘笔记中一直在提ChatGPT,但是没有完整整理过思路。机器学习和深度学习已经是三四年前学习的知识,都陌生了,但是当这个消息出来,那就不一样了:
2月2日消息,免费聊天机器人ChatGPT火爆后,OpenAI宣布将推出“ChatGPT Plus”付费订阅版本,每月收取20美元,约合人民币134元。作为付费用户,ChatGPT Plus用户将获得在高峰时段更快的响应、优先使用新功能和改进。
其实上个月,OpenAI还发布了每月42美元(约285人民币)的专业版ChatGPT Pro。但当时月活并没有那么吓人。而按照瑞银的最新研究报告数据,ChatGPT 的月活跃用户在1月份预计达到了1亿,成为史上增长最快的消费者应用。
当一件新事物,月活上亿,流量上来,并且开启商业变现之后,硬着头皮掏出西瓜书,再熟悉熟悉一些概念和原理,再把各种资料看起来,把这个东西扒一扒。
一、ChatGPT是什么?
简单说,可以理解成一个超智能的小爱同学或者天猫精灵。
他具备基础的世界知识(比如2022年以前的所有,只要训练集中包含),比绝大多数人掌握的知识面要广,要深。
他具有语言生成能力。并且根据他“掌握”的知识,可以拟人化的和你交流,根据对话内容,做出翔实和公正的回应,与各种AI聊天相比,他的回应会更加的长,更加的拟人。
他可以结合上下文,自由应对与你的交流,而不仅仅是一问一答。
他还可以拒绝某些不当的问题,他的设定是要遵循人类正确的价值观,对于某些不当的问题,比如颜色类,歧视类会拒绝,并可能反向给你灌输正确的价值观(当然,目前据说可以引导他跳出这种底线)。
他具有强大的推理和泛化能力,除了应答之外,可以进行推理,比如完成简单的作业;编写代码和debug;甚至可以进行创作,比如论文、诗词、剧本等。
当然,根据当前的知识和能力,他有可能给你编造出一个毫无逻辑,但又不容易看出对错的答案。但对于深度精细和专业化的问题,他无法做到的时候,也会承认自己的不足。
根据他的能力,他有可能通过图灵测试,你在交流时,可能完全不知道,对面是一个AI。
二. ChatGPT不能做什么?
ChatGPT的两个重要能力:知识和推理。但他的能力还存在一些问题:
(1)知识具有时效性。他的知识来源于训练过程中数千亿的参数和数据集,如果这个数据是2022年12月提供的,那么2023年1月发生的事情他无法知晓。
互联网虽然可以实时更新各种信息,但目前为止,他还不能实时的从互联网检索,不过,OpenAI已经进行过相关的测试。
(2)推理能力有限。在自然语言处理中,对于模棱两可不需要推理的,或者某些地方具有简单逻辑,但某些地方模糊的,它可以很好的处理。
但对于非常严谨,不能有任何歧义的问题,他无法进行推理。比如严格的数学证明。
(3)不能实时修改模型信念:如果模型中含有的部分知识本身是错的,他没有能力去修改模型对这一知识的信念。
三、 ChatGPT的能力如何获得?
从这部分开始,不得不引入更加专业性的名词,并且把不同的能力进行细分。
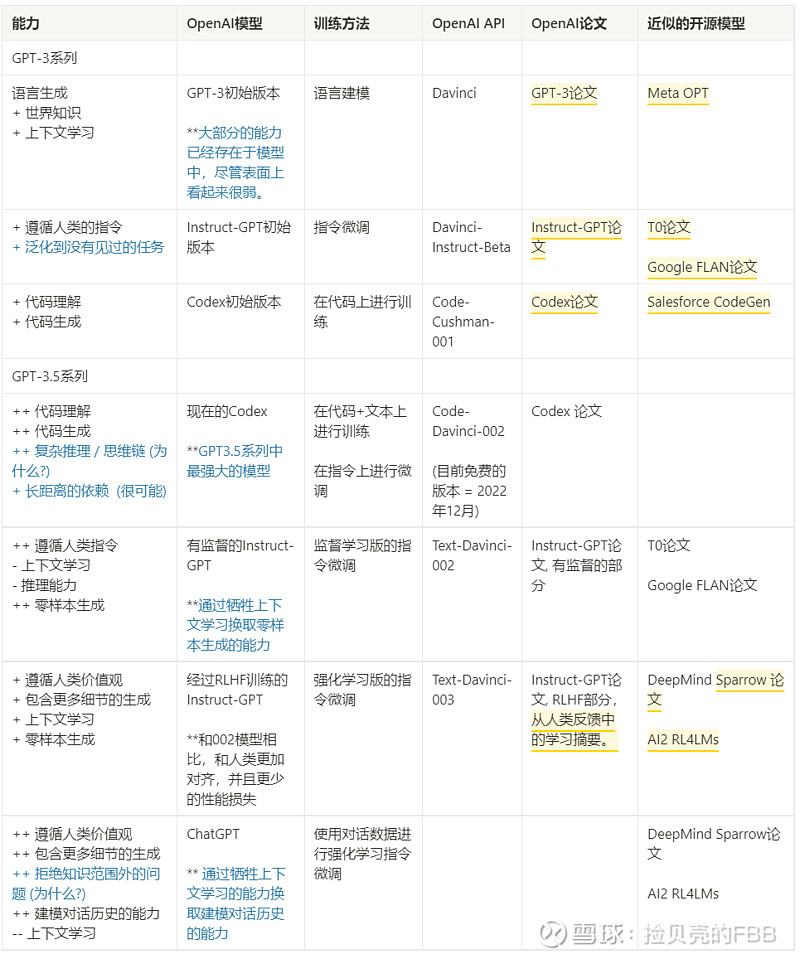
在ChatGPT发展过程中,经历了2020年的GPT-3 series的001阶段(code-davinci-001和text-davinci-001), 和2021~2022的GPT-3.5 series的002阶段( code-davinci-002 和text-davinci-002),以及GPT-3.5 series的003阶段( text-davinci-003和ChatGPT)。
1.ChatGPT的基本能力(001阶段):
(1)语言生成:根据提示词,生成语句,进行交互。来自于语言建模的训练目标。
(2)世界知识:包括事实性知识和常识。来自于 3000 亿单词的训练语料库和 1750 亿的参数。其中模型参数是为了存储知识。
(3)上下文学习:遵循给定任务的几个示例,然后为新的测试用例生成解决方案。这是 ChatGPT的重点。可能来自于同一个任务的数据点在训练时按顺序排列在同一个 batch 中。
以上三种能力都需要大规模预训练。在001阶段就已经获得。因为知识的性能与模型参数大小相关,千亿的参数+语料,注定了这是一个大模型的大规模预训练,需要大量的算力支撑。
但是实际上2020年左右的ChatGPT 001阶段并不够智能;开源的OPT模型与GPT-3模型非常接近,根据测试过的人员的反馈,与目前上线的ChatGPT相比,天差地别。
在后续的能力进化的002/003阶段,ChatGPT才达到了如今的拟人程度。
Note: 这里插一句,目前好多山寨版的ChatGPT APP,大概率就是基于OPT模型。
2.能力进化(002/003阶段):
在GPT-3.5 series开始引入代码训练和指令微调,包括有监督学习和强化学习。
其中,指令微调的好处是:训练所需的数据量比预训练数据量少几个数量级,可以节省算力开支和训练成本。
1.能力进化1:经过监督学习指令微调和代码训练,模型进化到002阶段,有了一些新变化,比如:
(i)代码生成和代码理解:基于代码的训练,这个显然可以增强。
(ii)泛化:可以自动在没见过的新指令上生成有效回答—-> 这是最终上线部署的关键,可以更好的响应人类指令,并生成更合理的答案;而不仅仅依赖于训练中的语句。
(iii)推理:利用思维链进行推理,这是代码训练的副产物,也是chatGPT在上线之后表现突出的能力来源
(iv)长距离依赖:可以上下文学习后的能力增强。
2.能力进化2:基于人类反馈的强化学习的指令微调(RLHF),模型进化到003阶段,也就是我们目前见到的ChatGPT,RLHF 触发了一些新的能力:
(i)更加翔实的回应:ChatGPT 的回应比002阶段更加冗长。
(ii)公正的回应:ChatGPT 对涉及多个实体利益的事件会给出非常平衡的回答,俗称上帝视角。
(iii)拒绝不当问题:这是内容过滤器和 RLHF 触发的模型自身能力的结合,过滤器过滤掉一部分,然后模型再拒绝一部分。比如拒绝其知识范围之外的问题。
到这一步,基本就是我们目前看到的ChatGPT了。
但要说明的是,指令微调不会加入新能力,两个阶段进化的新能力,不是在后续的代码训练和指令微调获得的,实际上是在三大基本能力的基础上的解锁和增强。
而三种基本能力,在大模型预训练之后就已经具备了。但三种基本能力对应的001阶段根本不出圈,到003阶段才真正开始火起来,这是需要思考的地方。
同时,指令微调可以让不同的模型具有不同的能力侧重,比如text-davinci-003更擅长上下文学习,而ChatGPT更擅长对话。这也是可以理解的,因为最终AI 落地之后不同的应用,有不同的侧重点。
下图可作为参考,ChatGPT的发展基本如此。
四、 国内的发展关键在哪里?
目前已知的信息—>ChatGPT完美运行的三要素是:训练数据+模型算法+算力;
结合GPT发展过程中获得的信息,在当前高科技发展处处被针对的前提下,我们按照这三个要素来看,谁才是关键?
(1)数据:中国不缺数据,百度、腾讯等互联网公司应该都有便捷的渠道获得类似的训练数据。不过数据采集之后,还需要对数据进行清洗、分离,获得不同的用于训练和测试调优的数据集。
这部分工作,也有对应的公司去做,问题是不大的,投入人力和物力即可。这基本上是个累活,训练数据很重要,但没有到只有谁才能做的地步,不存在什么你有我无的问题。
(2)算法:ChatGPT的基础能力在001阶段的GPT-3就已经获得,开源模型OPT与GPT-3模型近似,所以获得基础模型的难度并不大。
三大能力的获得是在基础模型上的大规模预训练,存储大量知识的能力来自 1750 亿的参数量(神经网络)。这部分需要大量的算力。目前已知的ChatGPT已经导入至少1万颗英伟达高端GPU来训练模型。
后续新能力的获得是模型调优后获得的解锁和进化,也就是指令微调和代码训练。
模型调优,我们有大量的调参侠可以去重复工作,并且这部分对算力的需求降低了几个数量级。只要有足够的算力+调参投入,获取一个类似的模型,看起来并不难。
当然,对于能创造算法的公司而已,那是他的核心竞争力。
(3)算力:其实到这一步,我们应该已经能推导出最关键的地方在哪里了?就是算力。也是我们最受限的地方。
数据可以获取,模型和模型调优,只要算力足够抗造,是可以做到类似的产品的。从百度宣称3个月后推出类似的chatGPT,应该可以佐证。
数据采集:对百度比较简单。
模型:百度本身对AI研究投入很大,又有飞桨,所以,模型以及调优,也是不受限。
从这几点看来,都不卡脖子。但问题是,中国不只有一个百度,还有大量需要算力支持的企事业单位。哪怕百度的昆仑,一旦台积电不给造了怎么办?芯片老化损坏后怎么办?
所以,我们不仅仅是需要一个昆仑,我们还需要更多高端的通用的,或者专用的算力芯片,包括云、端、边缘,包括训练和推理。
因为底层的芯片才是支撑算法运行的基石。明天,再找时间聊聊,算力芯片。95%的市场在英伟达手里。
国产的从云到端,上市公司、初创公司、互联网大佬(领投)纷纷下场,这是一个蓝海啊,有得聊呢