
文|白 鸽
编|王一粟
当数智化的风吹向银行业,是从底层数据的融合开始的。
在银行风控场景中,一个人想要进行风险投资或借贷,银行往往会评估这个人的信贷和风控策略。在以往的办理模式中,会需要办理人提交各种资料,但也无法对其情况进行更精准判断。
但如果多家银行能够合规共享这个人的相关数据,那么这个人在多家银行的的信用和风险数据就可以被精准融合分析,针对这个人的信贷和风控策略也就会更准确。
这就是数据流通的价值。当前,数据正在成为新质生产力,数据流通的价值也正在被深度挖掘。
据5月24日举办的数字中国峰会上发布的《数字中国发展报告(2023)》显示,2023年我国数据生产总量达32.85ZB,同比增长22.44%。

国内众多企业也纷纷开展相关布局,如电信构建了“数链智网(DCAN)”数据要素能力体系,华为打造了数据要素流通解决方案参考架构等。
“现阶段各行业对数据的需求正在急剧提升,但数据要素一定要跨域流转,才能够释放更多的价值。”蚂蚁集团副总裁、首席技术安全官韦韬说道。

然而,数据想要真正以要素的形态进入市场,在主体间进行流转,也面临着诸多挑战。
其中,数据流通中的安全、成本和易用性,像一个「不可能的三角」。想要打破这个三角,需要一个有力的方式破局。
技术层面,韦韬认为,未来数据要素在外循环流通过程中,基于密码学与可信的密算技术,将为数据可信流通提供全流程保障。密态计算,将是数据要素流通的必经之路。
现阶段,密态计算整体的技术发展基本已经成熟,而随着行业对数据流通价值需求的不断爆发,可以说万事俱备,只差成本和易用性的东风。而这股东风,需要借助市场机制及产品标准化能力。
于整个行业而言,接下来要做的,就是降低技术成本,推动数据大规模可信流转,从而通过低成本的密态计算技术,让数据价值像自来水一样即开即用。
数据流通从局部到广域
隐私计算关键“管道”技术
数据要素要“用得好”,关键是“流得动”。
蚂蚁集团董事长兼CEO井贤栋以城市自来水网来打比方,数据要素的流通发展,就像城市自来水网的发展一样,会经历四个阶段:
第一阶段,原始的数据孤岛,企业拥有数据自研能力,自产自销,就像自家水井;
第二阶段,实现数据要素点对点流通,就像桶装水,基础设施不完善,流通的范围也有限;
第三阶段,数据要素在行业和区域进行可信流转,就像城市自来水网;
第四阶段,数据广域可信流转,好比综合水利工程,实现跨行业、跨地域和跨云可信流转和互联互通,真正普惠千行百业。
目前,数据要素流通正在迈向第三阶段,也就是实现行业和区域间的可信流转。
在前两个阶段中,数据流通往往采用传统的数据交易方式,通常是基于对主体的信任,双方之间用明文数据流通,“直接拷贝一份或者接个API”,也就是用裸露的明文数据去共同计算、合作。
这种方式数据价值全面且成本低,但风险很高。韦韬表示:“数据本身的复制成本非常低,明文数据很容易造成二次分发,一旦分享出去就容易失控。”
数据在脱离自身控制后,对方是否会任意复制、是否会交给第三方、是否会将这些数据用于违法犯罪,这些问题变成了一个未知。
过去在各类安全标准未完全完善的情况下,数据交易中出现信息泄露以及其他合规风险的可能性较大,这也导致产业链相关方存在“不敢流通”、“不会流通”、“流通不起”等问题,大大抑制了数据要素的流通性。
随着 “数据二十条”等引导、规范数据要素流通的政策文件落地,各领域对数据要素的需求全面爆发,而随着数据资源开发能力的持续增强,也为智慧城市建设运行、工业互联网开发利用、金融行业等数智化应用提供了丰富的“原料”。
在2024年数字中国建设峰会上,国家数据局会同多个部门发布了首批20个“数据要素X”典型案例,涵盖了工业制造、现代农业、商贸流通、交通运输等12个行业和领域,通过典型经验做法,进一步促进数据要素开发利用。
但数据要素的流通依然面临非常多的挑战,尤其是涉及到数据隐私安全等问题。那么,如何才能实现数据在行业和区域中进行可信流转,最大化发挥数据要素价值?
推动数据要素从局部流通,进入到广域流通,隐私计算是关键的“管道”技术。
在韦韬看来,数据只有以密态形式的流通,保障存储、计算、运维、研发,直到销毁全链路的控访,才能实现有效的流转,并兼顾好安全和发展的诉求。
为什么密态计算能够解决数据流转过程中的安全问题?
蚂蚁集团隐私计算部隐语总经理王磊解释道,密态计算的本质逻辑,是机构一将数据通过密态环境给到机构二。在这个密态环境中,机构二知道有这部分数据,且能够使用这部分数据,但在使用的过程中,机构二并不能够看到这些数据。
因此,机构二只能够按照双方约定方式使用数据,且其通过加工后的数据也只能存放到密态环境中,并不能够随意取用,只有当双方经过严格数据确权后,数据衍生产品才能够成为明文数据析出。
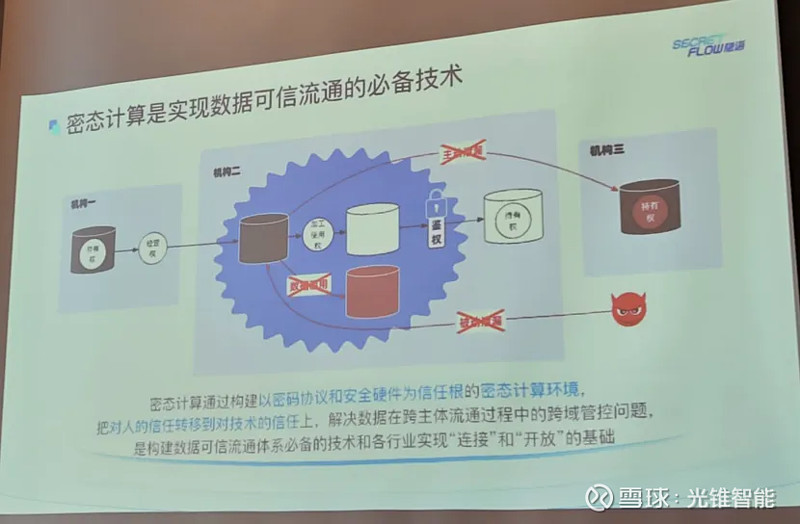
“密态计算,实际上就是把对人的信任转移到对技术的信任,从而实现数据跨主体流通过程中跨域管控的问题。”王磊如此说道,通过利用密态计算技术,实现数据密态流转,做到数据“可用不可见,可控可计量”。
密态计算解决了数据流通中的安全问题,但迈向数据密态时代的过程中,在保证多方数据安全的前提下,如何实现相对低成本门槛的数据价值合作,则也成为推动数据要素大规模流通的关键。
成本和价值的性价比
是数据流通的关键
当前,由数据泄漏造成的安全成本增加问题正日益严重。
据IBM《2023年数据报告》显示,2023年数据泄露的全球平均成本上升至445万美元,达到历史新高,比2022年的435万美元增加了2.3%,比2020年的386万美元增加了15.3%。
数据泄漏会导致企业数据资产的丢失,为企业造成严重的网络安全危机,从而带来成本的增加。
但现如今问题在于,网络安全技术成本非常高昂,致使行业中对安全技术的投入较低,无法为数据流通提供足够的安全保障。
“现实是,只有约三分之一的企业能够通过自己的安全团队发现问题,大部分公司都无力组建能够跟黑产对抗的安全团队。”韦韬说道。
因此,如何平衡安全技术的成本和数据价值,让密态技术能够更好的为数据流通做底层安全保障,则成为推动数据大规模流转的关键。
一个商品,只有在成本降到一定程度时,才能大规模普及。在数据要素的流通中,亦是如此。
韦韬认为:“数据要素在行业大规模应用和大规模推广的时候,最后一定是要把正向的业务价值和负向的风险综合考虑,让行业的费用达到最优解。”
而能够平衡技术成本和数据价值应用之间的关键,则在于市场的问题需要交给市场解决。
以美国为例,美国公司在进行数字化贸易合作过程中,会要求合作的公司购买网络安全保险,这其实是一个数据流通安全险。
如果在数据流通过程中,合作的公司在数据安全保障中做的比较好,这部分保费就会比较低,后续如果数据流通安全做的不好,风险较高,则保费费用会不断提高。
美国其实是通过一个市场化的机制,来让数据流通的价值与成本实现一种平衡。“这是整个市场自发的调节机制,推动行业在安全方面做更多的投入,最后达到一个综合性的最优。”
因此,韦韬表示:“实际密态计算成本能够控制在数据流通价值的5%以内,就可以达到非常好的阶段,相关数据方也非常愿意把数据拿出来。”
在一个尚未市场化的场景中,5%这个数据是怎么计算得来的?
韦韬解释道,这个数字,来源于安全保险行业的多年实践。美国保险市场发展比较成熟,尤其是在网络安全保险上,其最终要对效果负责,毕竟要真金白银做赔偿。
因此,美国保险的保费费率,是基于对安全技术水平的评估。
目前美国保险保费费率在2%-20%之间,综合大概在10%左右。但当安全工作没做好,风险控制不及预期的时候,往往会上升到10%,甚至到20%以上。
当使用密态技术时,风险会显著降低。目前美国保险公司已基本采用密态技术做相关费用评估,可以实现保费控制在2%以内,整体低于7%。
这也就会让行业对数据流通过程中的安全问题没有后顾之忧,毕竟有保险可以兜底。
“在金融行业,我们的密态计算成本已经低于5%,达到非常好的效果。”韦韬对光锥智能说道,“在不同的领域,随着技术的提升,成本都会逐渐下降,只要其成本低于领域数据流通价值的5%,就可以触发明文数据的密态流通,激发未来数据价值更好的流通和利用。
隐私计算发展至今,最初纯密码学体系的存算成本非常高,体现在数据交易上,则是其在数据流通价值中的占比会非常高,数据流转和交易的成本就非常高。
现如今,随着密态技术的发展,低成本的密态技术能够不断降低数据交易成本,最终则可以让数据价值像自来水一样即开即用。
当密态计算“遇上”云
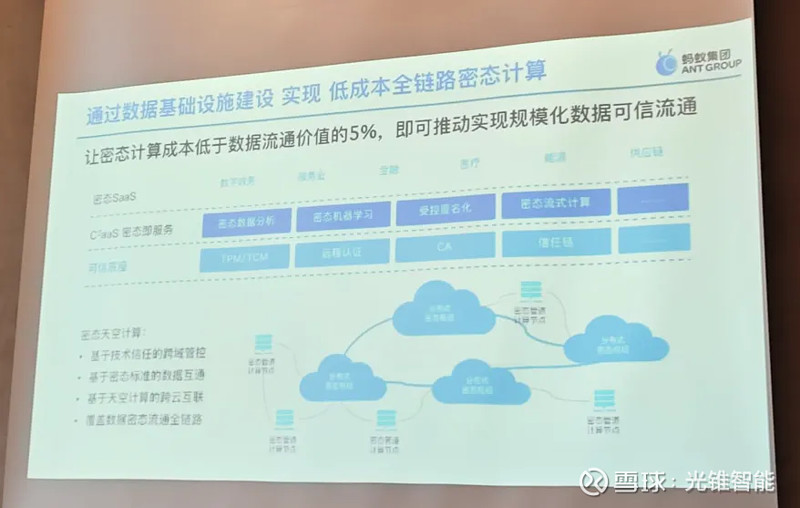
除通过技术的提升降低成本外,将技术产品化,让千行百业应用起来,也是关键。事实上,密态技术在行业中的应用,也经历了从PoC到规模化应用的阶段。
以蚂蚁集团为例,其早在2016年就开始布局隐私计算技术及规模化应用实践。
2016年-2018年,蚂蚁集团主要做前瞻性的技术布局,此时并未有很多的应用场景出现;2018年-2022年,则开始在中国农信、浦发银行等金融场景中落地一些PoC案例。
2022年至今,得益于国家数据要素市场化大规模的推进,整个数据安全需求开始爆发,隐私计算技术也逐渐开始进行规模化落地应用。
在这一阶段,蚂蚁集团的隐私计算技术在新能源、金融、保险等场景都落地数十家公司。如在金融风控场景中,基于蚂蚁隐私计算技术将多家银行数据进行安全的融合,能够更好的提升风控效果。
规模化落地的背后,源于蚂蚁集团围绕数据要素流通构建的全链路解决方案,包括 “隐语”可信隐私计算开源技术框架,及“星绽”可信执行环境操作系统Occlum等。
这其中,隐语是一个非常重要的开源产品,它能够通过统一的架构、原生应用、开发拓展、性能卓越等特性,显著降低用户使用成本。
比如在统一的架构下,用户能够在不同的场景中,让用户使用不同的技术路线,从而降低需要不同场景切换不同技术路线的成本。在开放拓展下,隐语通过采用模块化设计,可以让用户不需要使用隐语整个产品体系,而是按需使用,并根据场景做定制化设计。
现阶段,隐语已经助力多个场景的数据安全流转与融合。
如在新能源车保险定价场景中,由于缺少新能源汽车产品数据,为了后续不出现亏损,新能源车的保费一般都会略贵于燃油车。蚂蚁集团通过隐语将多方数据安全汇总到一起,并进行分析,能够为保险公司提供更精准的定价。
“目前已落地十多家保险公司,促使新能源车平均保费下降了8%。”王磊如此说道。
在农村金融中,针对农村用户的信贷问题,由于缺乏数据,导致银行无法精准判断客户风险,致使农村金融批贷的时候规模受限。通过密态计算,蚂蚁集团将农业农村部大数据发展中心与网商银行数据做了安全融合,实现了农村金融的秒贷秒批。
截至2024年5月初,已经有超过600万种植户获得贷款额度,其中78.3%农户种植面积不到10亩,是以往金融服务难以覆盖的人群。
虽然隐私计算技术已经进入规模化应用阶段,但从数据流转的角度来看,其还停留在固定场景之中,并未实现从点对点桶装水,到区域和行业城市自来水网的可信流转。
“2024年开始,我们希望通过密态计算技术构建数据可信的流转体系,能够让数据要素像自来水一样开箱即用。”王磊说道,“但想要数据真正实现在大范围内的可信流通,还需要体系化的去解决这里面存、算、研、治、用等全流程的安全问题。”

也正因此,近日蚂蚁还首次对外披露“隐语Cloud”密态计算云服务,可以让企业像购买云服务一样购买隐私计算服务,支持数据跨云跨端可信流通,相关产品和服务将在今年内陆续发布。
已经有了隐语这一开源产品,为什么蚂蚁还要做密态计算云服务?
以金融行业为例,之前数据的使用流转都是点对点,但随着行业的发展,其瓶颈也会非常明显。而数据上云之后,除了规模的优势,还可以实现数据“存算联”的智能使用。
同时,也只有做到数据全链路的安全、高效使用,数据才有价值。“隐语Cloud云服务平台就是是希望去解决数据‘大规模’可信流通的问题。”王磊说道。
据介绍,“隐语Cloud”将围绕数据流转全链路提供数据密算服务、大模型密算服务、密态数据托管、密态数据研发等服务,具有“按需获取、即开即用”特点,让中小微企业也可以低成本地获得密算服务,降低技术门槛,打开产业协作空间。
同时,隐语Cloud也将带来三个核心价值:
一是跨云跨端,通过统一的密算服务打通多云和多端的物理边界,在空间上让数据能够延展到各个地域;二是全生命周期可信,即从数据的采集、使用一直到数据的销毁,在数据的全生命周期中,通过可信的技术与参与管控的能力,确保这些数据在整个时间维度的生命周期中可信可控。
三是成本可控,如果需要大规模的应用支持大规模的可信流通,低成本和高性能是它必不可缺的能力。王磊表示:“通过软硬结合的方式,我们希望密态计算的成本能够缩小至明文计算的2—10倍,性能能够逼近明文的1/2—1/10。”
云计算是数智化时代的算力底座,数据从点对点的流转,到最终大规模的可信流转,必然离不开云的支持。同时,随着大模型时代的到来,数据要素流转价值的需求进一步爆发。
大模型时代
数据的永动机
大模型的到来,让数据流通的需求进一步提升。毕竟,高质量的数据是大模型迭代升级的关键。因此,越到后期,数据的瓶颈就会让大模型对数据的价值更加重视、甚至是渴求。
事实上,在早期人工智能发展过程中,AI虽然也是通过大量数据进行学习,但这些数据必须先经由人类进行分类和标注才能使用。“有多少人工,就有多少智能”也成为当时的真实写照。
在进入大模型时代,基于AI能力能够更快更高效的获取高质量数据后,更重要的则是需要打破数据孤岛,让更多的数据流动起来,才能够产生更高的价值,从而促进整个行业发展。
以医疗行业为例,现阶段各个医院的数据都相对独立,如果有一个全医疗行业的数据集,汇总所有医疗行业相关数据资源,并能够在保证数据隐私安全的前提下,公开给行业使用,这将大大提升整个行业的效率。
如果说大模型是一个动力机,那么依托隐私计算的数据,就是保证动力机源源不断升级、发电的高质量燃料。未来,还需要不断释放我国海量数据和丰富场景优势潜力。