$英伟达(NVDA)$ $博通(AVGO)$ $谷歌A(GOOGL)$
昨天,黄仁勋在斯坦福有两场演讲,其中后一场信息量很大。提到了英伟达面临的几个挑战,内容很多,信息量很大。今天接上黄教主的话题,探讨一些有关AI格局的思考,希望能直击读者心灵、促发读者思考。若能如此,就是对读者最大的尊重和回报。
考虑到公众号文不能太冗长,我们今天只接黄教主一个球。
我特意挑出期间最为关键话题:“有关ASIC的竞争”。希望就这个话题深入探讨话题的起源、背后及对未来的影响,借此探讨帮助读者建立对未来格局一个清醒全面预判。
我们,先看一下黄教主是怎么说的?
我平时也会不定期在"只¥是$ 兴 %裘"(刘翔科技研究)上,对一些最新科技动向做解读。帮助读者透过现象看本质、真正理解事物的底层逻辑,从而帮助读者应对未来
“关于ASIC的竞争
我们不仅有来自竞争对手的竞争,我们还有来自客户的竞争(云厂),而且我是他们眼中唯一的竞争对手。而且我们明明知道客户即将设计一款芯片来取代我们,我还要继续向他们展示我目前的芯片、下一代的芯片,以及之后的芯片,各种秘密。这样做的原因是,你要尝试让他们相信你在这个领域是最好,他们才会不得不选择你。因此,我们都是完全透明的。诚然你可以为特定的算法构建一款优秀的芯片(ASIC),但记住,计算不仅仅是关于transformer,更何况我们正在不断地发明新的transformer变种,除此之外,软件的种类非常丰富,因为软件工程师就喜欢创造新玩意儿。Nvidia擅长的是加速计算,我们的架构不仅能加速算法,而且是可编程的,这意味着你可以用它来处理SQL(SQL自20世纪60年代IBM以来就出现了,它是存储计算中非常重要的部分,每几年就有300ZB的数据被创造出来,其中大部分都存储在SQL结构化数据库中),我们可以加速量子物理、加速所有的流体和粒子代码等等广泛领域,其中之一才是生成式AI。对于那些希望拥有大量客户的数据中心来说,无论是金融服务还是制造业等,我们都是一个最棒的标准。我们存在于每一个云服务中,存在于每一个计算机公司中。因此,我们公司的架构经过大约30年成为了一种标准。这就是我们的优势。如果客户能够有更具成本效益的替代方案,我甚至会为此感到惊讶。原因是,当你看到现在的计算机时,它不像笔记本电脑,它是一个数据中心,你需要运营它。因此,购买和销售芯片的人仅仅考虑的是芯片的价格,而运营数据中心的人考虑的是整个运营成本、部署时间、性能、利用率以及在所有这些不同应用中的灵活性。总的来说,我们的总运营成本(TCO)非常好,即使竞争对手的芯片是免费的,最终算下来它也不够便宜!我们的目标是增加如此多的价值,以至于替代品不仅仅是关于成本的问题。当然,这需要大量的努力,我们必须不断创新,我们不能对任何事掉以轻心。我本来希望不要听起来太有竞争性,但约翰问了一个竞争问题,我以为这是个学术论坛....这触发了我的竞争基因,我道歉,我本可以更艺术地处理这个问题。(哄笑)”
“为什么英伟达开始想做ASIC?
我们是否愿意定制化?是的,我们愿意。为什么现在的门槛相对较高?因为我们平台的每一代产品首先有GPU,有CPU,有网络处理器,有软件,还有两种类型的交换机。我为一代产品建造了五个芯片,人们以为只有GPU一个芯片,但实际上是五个不同的芯片,每个芯片的研发成本都是数亿美元,仅仅是为了达到我们所说的“发布”标准,然后你必须将它们集成到一个系统中,然后你还需要网络设备、收发送器、光纤设备,以及大量的软件。运行一个像这个房间这么大的计算机,需要大量的软件,所以这一切都很复杂。如果定制化的需求差异太大,那么你必须重复整个研发过程。然而,如果定制化能够利用现有的一切,并在此基础上增加一些东西,那么这就非常有意义了。也许是一个专有的安全系统,也许是一个加密计算系统,也许是一个新的数值处理方式,还有更多,我们对这些非常开放。我们的客户知道我愿意做所有这些事情,并认识到,如果你改变得太多,你基本上就全部重置了,浪费了近千亿美元。所以他们希望在我们的生态系统中尽可能地利用这些(减少重置成本)。”
如上很显然,黄教主对定制ASIC的竞争话题已经不淡定了。
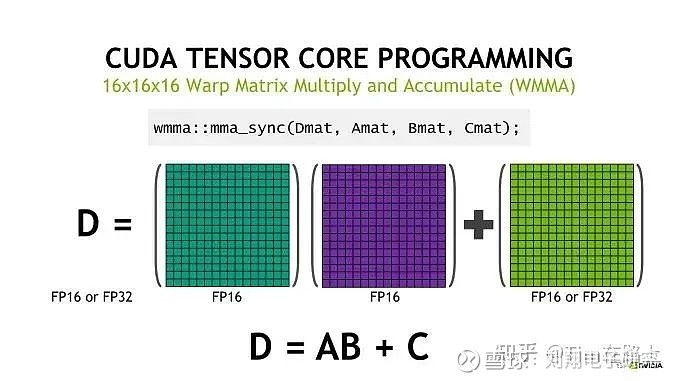
首先,什么是定制ASIC?英伟达出的产品是GPU,GPU和CPU类似,都是通用芯片,其中核心计算单元是CORE(如下图),不仅仅可以结算FMA(Fused Mutiply-Add)这样简单的运算,还可以执行更加复杂的运算操作,例如tensor张量(tensor core)或者光线追踪(ray tracing core)相关的操作。这个很像以前我们做图像或者信号处理,算法里面经常用到傅里叶变化,硬件电路经常是用TI或者ADI的DSP来实现。因为DSP的“乘累加”电路基础单元,特别匹配傅里叶变化。定制ASIC,与CPU、GPU和DSP不一样,是为某一个具体应用专门定制的集成电路芯片。
在公众场合,黄教主前后两次重点谈及定制ASIC的竞争。显然这并不是就一个随口提问的答复,而是有针对性的回应。那回应的是谁呢?为啥这么强烈的回应呢?这背后一定有故事!
黄教主的不淡定触动了一个资深双师(分析师和工程师)的敏感神经,我第一时间把黄教主的发言发在知识星球上,并针对该话题连续发问,期待引起大家的探讨反馈。不过很遗憾,并没有人接招。

因为平时积累、思考的差异,每个人对话题的敏感度也不一样。我是早在好几个月前,就特别意识到这一点,为此还专门写了一篇文章《科技巨头不让英伟达一家独大,AMD逢缘》。
这种隐隐的不安最近又莫名地加强了。尤其是,上周末博通和marvell的业绩说明会上的一些信息,让我意识到必须重视这个技术路径分歧了。
博通的业绩说明会主要内容,大家可以参考我前两天公众号文《又一个70亿美元的竞争对手出现了,英伟达的股价要不要心慌1秒?》的后半段。我为读者做了22点精选摘要。
有关定制加速器芯片(即与英伟达竞争的定制ASIC),博通电话会提到几个关键信息点:
2023Q4,数据中心相关半导体收入33亿美元、同比大幅增长46%,增长主要是因为两个超级大客户定制AI加速器,且定制AI芯片增速超过了普通AI加速芯片增速。
由于人工智能强劲,本来12月预计24财年半导体AI收入占比25%,现在要把这个占比提升到35%。预计24财年AI半导体收入超100亿美元。
AI半导体收入从一个季度前预计的75亿美元提升至100亿美元,比原预期多增加25亿美元。新增部分70%由超级客户要求的定制AI加速器贡献、30%由标准AI加速器贡献。
100亿美元AI半导体中,70%是AI加速器,20%是交换机和路由器芯片,剩下的10%就是光器件、DSP这些元件。
为两个超级大客户定制AI加速芯片,但也仅仅两个。定制芯片是需要大量资金来匹配,还要考虑商业模式,需要不断迭代,还需要和客户的软件、固件匹配。和CPU时代不同,定制AI加速器在GPU时代还处于很早期。
AI加速器不仅仅是一大堆浮点乘法器或者矩阵回归分析计算,还需要大量的高速内存,外购高速内存颗粒一起结合起来做成AI加速器。即使定制的AI逻辑计算部分毛利率高,但是总体毛利率不会高,因为需要外购昂贵的HBM。
其实不单单是博通收到了大客户的定制AI加速器(GPU)订单,Marvell也有收到。Marvell在业绩说明会上是这么讲的:
预计两个定制AI加速器芯片在24年第一季度首批出货,并有望在本财年下半年大幅增加。
预计AI加速器芯片的年收入有可能与快速增长的数据中心光学业务收入差不多。作为参考,数据中心光学业务在 2024 财年增长到 10 亿美元以上。过去两年中,已经成功设计了多个 5 纳米AI加速器芯片,并与云客户就新的 3 纳米方案进行了深入合作。
宣布延长与台积电的长期合作,以开发业界首个技术平台,以生产 2 纳米的AI加速器芯片。
全年预计定制AI加速器收入10亿美元,而且从客户预测值来看25年仍然会非常好。
AI方面,定制加速芯片会和标准GPU非常互补,两者都有存在的必要。
两个客户的AI定制芯片处于生产爬坡的初始阶段,3nm的项目会非常值得期待,还会带动交换机、光学DSP业务。
全球四大超级云厂商都非常需要满足差异化的独特解决方案,满足更多的sku,而且速度比预想的快。
然而,不仅仅是博通和marvell,据说思科也收到了类似订单。博通提到的两个定制AI加速器超级云厂商客户,公司在会上没说具体公司名,但是我猜是meta和谷歌;marvell的两家也没点出具体名字,我只能猜出一家是亚马逊,另外一家希望知道的读者能留言告诉我。
对于这个技术路径的分歧,很多英伟达投资者可能会说:黄教主在回应里面明确地说定制ASIC根本没有竞争力,你看博通(AVGO.O)和marvell(MRVL.O)股价这两天跌了不少,尤其marvell。是的,他们两家股价是跌的,但是我认为跌的原因是他们其他业务预期实在是不行,但AI相关却是超预期的。
英伟达与博通和marvell对AI定制芯片的看法,分成两派。虽然两派各执一词,但却不完全相斥。比如marvell高管就认为:定制AI加速器和通用GPU两者互补,都有巨大的市场空间,并不是一场零和游戏。我认为,marvell高管的观点是中肯的。
至于定制ASIC有没有价值?我想我们应该听听客户们的意见,毕竟他们才是客户啊,他们说的算。这几大超级云厂商给博通、marvell实实在在的加单却是诚实的。
如果行动是诚实的,那英伟达是不是已经面临丢单的风险?也不对,我认为。
我认为是:这些超级云厂商在做大模型训练的迭代过程中,看到了大模型简直是喂不饱的吞算力兽。他们看到如要做出真正完美的世界模拟器,未来对算力需求将是在现在的基础上还有几个数量级的提升。
正是因为看到这一点,OPenAI CEO奥特曼才提出来要投资7万亿美元,为此还去专门拜访了台积电和海力士。很显然,作为模型厂商他要涉足上游的上游,自己下场制造算力芯片。如果未来的算力芯片需求是一个可预期的、不算惊人的数字,值得一个还算初创的模型厂商跨过上游的上游自己下场亲自干?
其实亲自干还不仅仅是OpenAI,还有微软、谷歌等。wintel(windows+intel)的搭配,造就了PC时代微软的成功。微软可能比硅谷的任何一家公司都明白分工的意义。肩并肩一路同行了十多年,微软很理解他和英特尔两者之间是互相需要、互相依存的关系,而不是一个依附于另外一个的关系。而今天的微软甚至已经在4个月前的2023年11月,冒然单独行动,发布了自研的人工智能芯片Maia100。这说明了啥?说明了:要么微软特别担心对英伟达的人身依附,要么英伟达的产品确实还不够完美配合自家模型。
我的判断是:两者皆有。
读者你,请再重读一遍最上面黄教主的回应。很显然,黄教主虽然口口声声说愿意为客户定制ASIC。但他所谓的定制,是大的基础通用架构不改的前提下,在其上增加一个或加密、或数值计算的小模块。站在英伟达的角度,这么做最有利,不单享受了定制芯片的高毛利还不破坏他们家的规模效应。
我们再听听博通和marvell两家公司对定制AI加速器的看法。marvell业绩说明会上,其高管反复强调他们与台积电合作的2nm加速器芯片的性能值得期待,这是在经过5nm、3nm不断迭代之后的新产品;博通高管也多次强调他们与两个大的云服务厂商在定制ASIC的合作历经8年,在模型适配、软件适配、参数调整上面做过很多次的迭代。看得出来,他们是真正地在为客户做定制,真正地不断调优的定制。
所以,客户那边也用巨额的真金白银加单回馈了。比如,以博通而言,24财年预计100亿美元的AI半导体收入,其中70%的AI加速器中又有70%是两家超级大客户定制的。那就是说,两家云服务厂商可是一年要给博通超过50亿美元来定制AI加速芯片。平均一家一年25亿美元,而且还在加速中。一年25亿美元可不是小数字。这还只是AI加速器,还不包括配套的网络芯片、交换芯片呢。
训练做的是大模型,非常复杂,不单需要的算力硬件庞大,而且训练时间长。因而对硬件算力效率看得特别重。所以符合自家模型的定制ASIC会更受欢迎。
推理相对于训练来说,算力要求简单些却多样化,能适配大多数情形的通用AI加速器自然就更好。
黄仁勋说,他们家产品用于推理的占比在2023年是40%,在2024年会占到70%。这个结果和我上面的判断也是匹配的。
最后还是落实到行业、对公司的判断,我把一些结论放在知识星球。随着跟踪的推进,观点的修正也是持续进行的。然而,敢于亮出观点就是态度,真诚欢迎各位读者参与进来一起在星球讨论。