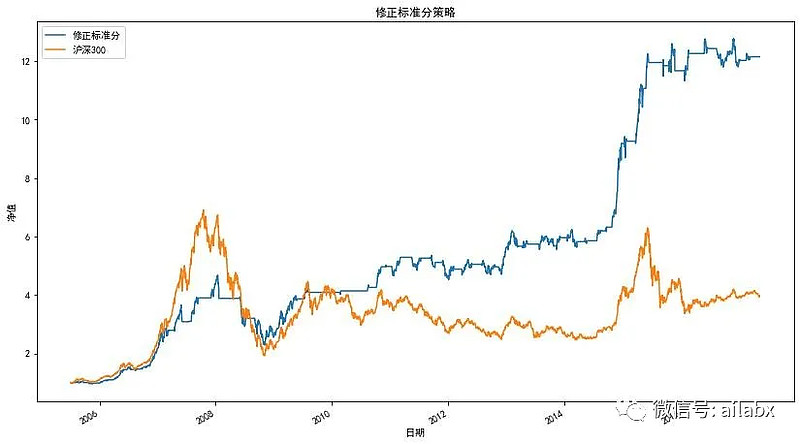
光大证券有一个RSRS指标,回测看来效果很不错,它也是基于突破的逻辑。与传统布林带这样的通道不同,它对$high最高价,与$low最低价之间做一个线性回归,看它的趋势。
只是RSRS指数要计算两个序列的相对斜率,这个指标,qlib没有实现。
——他们想到的,但还是todo。只能自己动手,丰衣足食。
# TODO:
# support pair-wise rolling like `Slope(A, B, N)`
class Slope(Rolling):
正好熟悉一下qlib的自定义指标。
其实过程不复杂,在初始化的时候,把自定义指标注册进去即可。就是下面代码里的“custom_ops”。
provider_uri = "~/.qlib/qlib_data/{}".format('index_data')
qlib.init(provider_uri=provider_uri, region=REG_CN, **{"custom_ops": [RSRS]})
而指标的实现过程如下,两个指标运算,继承自PairOperator,只需要实现这个_load_internal即可。加载数据逻辑是一样的,把se_left,se_right两个序列加载,然后进行计算。
import numpy as np
import pandas as pd
import qlib
from qlib.data import D
from qlib.data.ops import ElemOperator, PairOperator
from qlib.config import REG_CN
import statsmodels.api as sm
class PairSlope(PairOperator):
def __init__(self, feature_left, feature_right, N):
self.N = N
super(PairSlope, self).__init__(feature_left,feature_right)
def _load_internal(self, instrument, start_index, end_index, freq):
series_left = self.feature_left.load(instrument, start_index, end_index, freq)
series_right = self.feature_right.load(instrument, start_index, end_index, freq)
slope = []
#R2 = []
# 计算斜率值
n = self.N
for i in range(len(series_left)):
if i < (self.N - 1):
continue
else:
x = series_right[i - n + 1:i + 1]
# iloc左闭右开
x = sm.add_constant(x)
y = series_left.iloc[i - n + 1:i + 1]
regr = sm.OLS(y, x)
res = regr.fit()
beta = round(res.params[1], 2) # 斜率指标
slope.append(beta)
#R2.append(res.rsquared)
#df = df.iloc[n - 1:]
slope = pd.Series(slope)
return slope
if __name__ == '__main__':
provider_uri = "~/.qlib/qlib_data/{}".format('index_data')
qlib.init(provider_uri=provider_uri, region=REG_CN, **{"custom_ops": [PairSlope]})
instruments = ["sh000300"]
fields = ["PairSlope($high, $close,18)"]
print(D.features(instruments, fields, start_time="2010-01-01", end_time="2017-12-31", freq="day"))
然后我们需要实现一下pair_slope即可。
qlib自身有一个slope的计算函数。
# TODO:
# support pair-wise rolling like `Slope(A, B, N)`
class Slope(Rolling):
def __init__(self, feature, N):
super(Slope, self).__init__(feature, N, "slope")
def _load_internal(self, instrument, start_index, end_index, freq):
series = self.feature.load(instrument, start_index, end_index, freq)
if self.N == 0:
series = pd.Series(expanding_slope(series.values), index=series.index)
else:
series = pd.Series(rolling_slope(series.values, self.N), index=series.index)
return series
调用了rolling_slope这个函数。
from ._libs.rolling import rolling_slope, rolling_rsquare, rolling_resi
from ._libs.expanding import expanding_slope, expanding_rsquare, expanding_resi
我调用了statsmodels.api线性回归算法计算了,性能可能差一点,后续可以优化。
有了指标,其实策略就很简单了。
由于计算时间较长,我使用了hdf5来缓存,hdf5可以原样保存dataframe的数据,而且性能很好,可以当离线的字典来用,csv大且慢,而且dataframe写csv再读出来,index,column信息会丢失,数据格式float可能会变成str,都要自己去转换。
store = pd.HDFStore('cache.h5')
if 'cache' in store.keys():
df = store.get(key='cache')
else:
features = ["$high", "$low", "PairSlope($high, $close,18)"]
features.append('$close / Ref($close,1) -1')
names = ['high', 'low', 'RSRS', 'rate']
# 'sh000905', 'sz399006'
df = logic.load_data(instruments=['sh000300',], features=features, names=names)
df = df['feature']
df['to_buy'] = df['RSRS'] > 1
df['to_sell'] =df['RSRS'] < 0.8
明天正式来实证RSRS策略,复现光大证券研报。