在mongo里完成了基础数据以及时间序列的存储之后,后面就开始数据使用及分析。
一、数据加载及预计算
对于特定的一支证券时序数据,从效率的角度考虑,可以缓存在本地csv,如果本地数据不存在,则从远程mongo数据库中加载。
#按code的顺序加载df,并做预计算
def load_codes(codes):
dfs = collections.OrderedDict()
for code in codes:
df = load_code(code)
df.index = df['_id']
del df['_id']
df.sort_values(by='trade_date',ascending=True)
if 'adj_factor' in list(df.columns):
for col in ['open', 'high', 'low', 'close']:
df[col] = df[col] * df['adj_factor'] #直接后复权了
del df['adj_factor']
if 'adj_nav' in df.columns:
df['rate'] = df['adj_nav'].pct_change()
elif 'close' in df.columns:
df['rate'] = df['close'].pct_change()
dfs[code] = df
return dfs
按trade_date从前往后排序,同时如果有复权因子,把OHLC的数据按后复权计算。然后把根据close字段及adj_nav(基金的复权净值) 使用 pandas的pct_change()计算日计收益率。
二、数据提取与合并
为了便于分析,会把多支证券的数据合并起来,常见的合并有如下几种:
a)纵向合并,日期取所有dataframe里最大的,而后按日期取并集,重新索引所有的dataframe。这样做是由于A股与美股交易的caledar不一样,如果不处理的话,放到一起会有一些日期为NaN。
def merge_dfs(dfs):
max_date = calc_max_date(dfs)
for code,df in dfs.items():
df = df[df['date'] > max_date]
dfs[code] = df
calendar = calc_calendar(dfs)
new_dfs = []
for code,df in dfs.items():
df.index = df['date']
del df['date'] #要选删掉,否则date会ffill
df = df.reindex(index=calendar, method='ffill')
df['date'] = df.index
df.index = df['date'] + '_' + df['symbol']
new_dfs.append(df)
df_all = pd.concat(new_dfs,axis=0)
df_all.dropna(inplace=True)
df_all.sort_index(inplace=True)
return df_all
得到如下合并好的数据集:
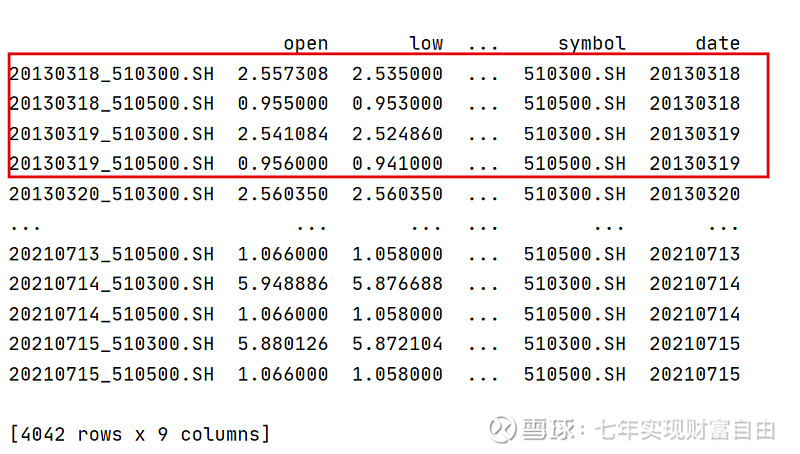
b)横向合并,把收益率合并,用于组合或多个时间序列做分析。
#在纵向的基础上,把rate合并出来
def dfs2rate(df_all,codes=None):
if codes:
symbols = codes
else:
symbols = df_all.symbol.unique()
prices = []
for s in symbols:
df = df_all[df_all['symbol']== s]
df.index = df['date']
se = df['rate']
se.name = s
prices.append(se)
return pd.concat(prices,axis=1)
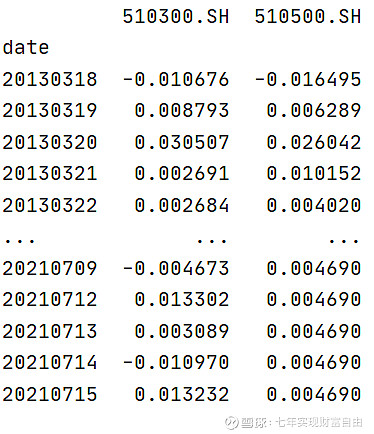
c)纵向多索引,两个索引分别是date,symbol,这是因子分析框架alphalens需要的输入格式:
#纵向合成,并把Date,symbol作为多索引
def dfall_to_multiindex(df_all):
df = df_all.copy()
df['date'] = df['date'].apply(lambda x: datetime.strptime(x, '%Y%m%d'))
df.set_index(['date', 'symbol'], inplace=True)
df.sort_index(inplace=True)
return df
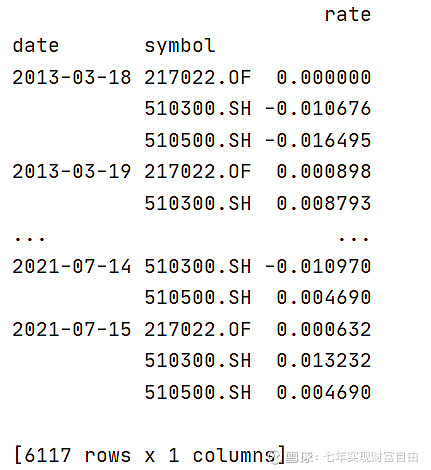
至此,数据准备工作基本完成,可以进行数据分析了。
(公众号: 七年实现财富自由(ailabx),用数字说基金,用基金做投资组合,践行财富自由之路)