大家好,我是Lucy@FinTech 社区。这篇文章是关于如何使用机器学习预测股票价格。
推荐理由:(1)详细讲解因变量的去噪和自变量的特征提取(2)构建长短期记忆循环神经网络模型预测价格(3)详细介绍神经网络训练的优化器和正则化处理
文章同步发布于微信公众号fintech社区上,欢迎大家关注技术 | 使用AI的最新成果来预测股票市场变动
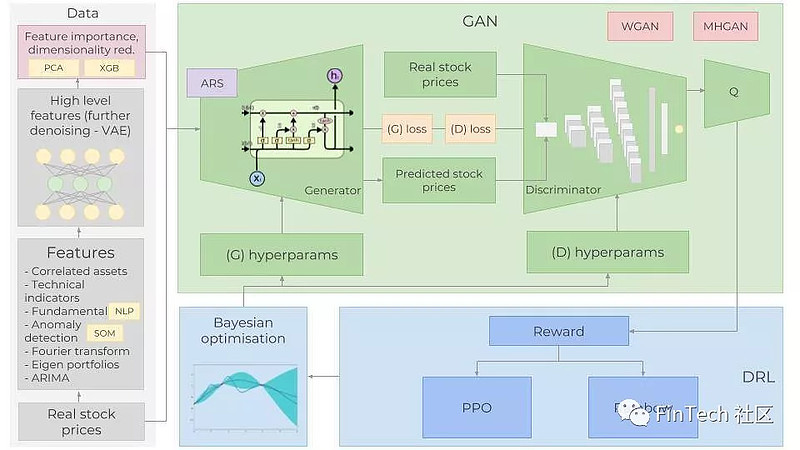
在这篇文章中,我将创建一个完整的程序来预测股价波动。我们将一起取得一些很好的效果。为了达成目的,我们将使用GAN,用LSTM作为生成网络,CNN作为辨别网络。使用LSTM的原因是因为我们尝试预测时间序列数据,为什么我们使用GAN并且以CNN作为辨别网络,后面会有专门的解释。
我们会深入每一步的具体细节,当然,最困难的一部分是GAN,要成功训练一个GAN最棘手的部分就是得到正确的超参数集。为此我们将是使用贝叶斯优化器(连同高斯过程)和强化学习来决定何时以及如何改变GAN的超参数。在构建强化学习时,将使用最新的进展,例如Rainbow 、PPO。
我们将使用到许多种输入数据。除了股票历史交易数据和技术指标,还将使用自然语言处理NLP的最新成果(BERT,基于transformer的双向编码表示器,一种NLP的迁移学习)来做舆情分析;使用Fourier transforms来提取整体趋势方向;使用Stacked autoencoders来识别高级特征;使用Eigen portfolios来查找相关资产;自回归移动平均模型(ARIMA)用于股票函数逼近,和许多别的技术,以便获得股票更多的信息、模式、依赖。正如我们所指,数据越多越好,预测股价变化是一个非常复杂的任务,所以对股票越了解,提升才会越高。
为了搭建所有的神经网络,我们将使用MXNet和他的高级接口-Glluon,并用多个GPU训练他们
1. 介绍:
精准的股市预测是一项复杂的工作,因为特定的一只股票向特定的方向移动是需要许多的事件和前提条件的。所以我们需要尽可能的挖掘出这些前提条件。
我们还需要做出几个重要的假设:
1.市场不是完全随机的
2.历史会重复
3.市场遵循人们理性的行为
4.市场非常完美
我们将尝试预测高盛公司(纽约证券交易所代码:GS)的价格走势。为此,我们将使用2010.1.1~2018.12.31的所有每日收盘价(其中七年用于训练,两年作为测试验证)。我们将互换者使用‘Goldman Sachs’和‘GS’两个术语。
2. 数据
需要了解是什么影响着GS的股价涨跌。因此,需要结合尽可能多的信息(从不同的方面和角度描述股票)。我们将使用1582天的每日数据也就是70%的数据来训练不同的算法,并预测之后的680天(测试数据)。然后我们将对预测结果和测试数据进行比较。每种数据(作为特征参考的)在之后的段落中会解释具体细节。从总体上来看,我们将用到:
① Correlated assets相关资产-其他的资产(任何类型,不只是股票,比如商品、外汇、指数、或者固定收益证券)。像高盛这样的大公司显然不会孤立的存在世界上,它会依赖于许多外界因素并相互互动,包括他的竞争对手,客户,全球经济,地缘政治形式,财政和货币政策,融资渠道等等,这些细节稍后将被一一列出。
② 技术指标-许多投资者是跟随技术指标的。我们将使用许多常用的指标作为独立特征。其中有:7日和21日均线,指数均线,动量效应,布林带,MACD。
③ 基本面分析-一个指示股票涨跌的非常重要特征。有两个特征可以用于基本面分析:1.用10-k、10-Q(季报、年报)来分析公司的情况,分析ROE(净资产收益率)和P/E(市盈率)等等(我们不会使用这个)2.新闻-新闻有可能会意味着即将发生的会使得股价涨跌的事件。我们将获取每天有关高盛公司的所有的新闻并提取分析出当天关于高盛公司的所有的舆论是有利的、中立的还是不利的(用0~1来打分)。因为许多投资者会阅读新闻,并据此做出投资决定,所以如果高盛公司今天的新闻非常有利,认为股票将大涨,那么这就是一个比较好的机会。一个关键点是,我们将在之后对每个特征去分析特征的重要性(feature Importance)(即其对GS股价的走势的指示性如何),并决定是否采用它。稍后详解。
为了能够精确的进行舆论预测,我们将涉及到自然语言处理(NLP),我们将使用BERT-谷歌最近发布的针对情绪分类、股票新闻舆情提取的NLP方法。
傅里叶转换(Fourier transforms)-针对每日的收盘价,我们将使用傅里叶转换来生成几个长期和短期的走向,通过这些转换我们将消除许多噪声(随机游走),并创建出实际股票走势的近似值。走势近似值可以帮助LSTM网络获得更精确的预测趋势。
自回归移动平均模型(ARIMA)-这是最流行的用来预测未来时间序列数据的技术之一(在前神经网络年代)。通过使用ARIMA,看看能不能得到一个重要的预测特征。
堆叠自编码器(Stacked autoencoders)-经过几十年的研究,人们已经发现了大部分之前提到的特征值(基本面分析、技术面分析,等等)。但或许还有一些我们没发现特征值。也许还有一些人们无法理解的潜在关联在大量的数据点,事件,资产,图表等等中。通过Stacked autoencoders(一种神经网络)我们可以通过计算机来找到一些新的影响股票走势的特征值。即使我们不能按人类的语言来理解它们,我们也可以将他们运用到GAN中。
对于期权定价的异常检测的深度无监督学习算法:我们将再使用一个特征-对于每天我们会加上高盛股票90天的看涨期权价格。期权价格包含了许多数据。期权合同的价值依赖于股票的未来价值(分析师为了得出最精准的看涨期权价格也会尝试对股价价格进行预测)。通过使用深度无监督学习(SOM自组织映射算法)我们将尝试发现出每天期权价格的异常。异常(比如价格剧烈的变化)可能意味着一个会对LSTM网络学习所有股价规则有帮助的事件。
之后,有了这么多特征,我们还需要执行几个重要的步骤:
1. 对数据的质量进行统计检查。如果我们的数据是有缺陷的,那么无论多么复杂的算法,结果都不会好。检查包括确保数据不会受到异方差性(heteroskedasticity),多重共线性(multicollinearity)或串行相关性(serial correlation)的影响。
2. 构建特征重要性检测(feature importance)。如果一个特征对于我们想要预测的股票没有解释力,那么就没有必要用来训练神经网络。我们将使用XGBoost(eXtreme Gradient Boosting),一种增强树回归算法。
3. 作为我们数据准备的最后一步,我们将通过主成分分析(PCA)创建Eigen portfolios(特征组合)来降低自动编码器(autoencoders)输出的特征的维度。
注意:这一节的目的是为了展示数据预处理过程和使用不同数据特征值的理由,因此我将只使用其中一部分子集(用来训练的)。


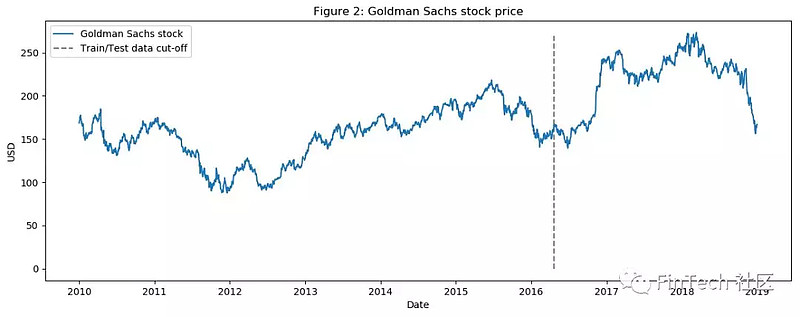
可视化近九年的股价,用垂直虚线来划分测试集训练集。


2.1 相关资产
正如之前所述,我们将使用其他资产作为特征值,不仅仅是GS的股票。
有哪些资产会影响到GS股票的走势呢?对公司有更好的了解对于选择合适的相关资产非常重要,比如公司的业务线,竞争格局,依赖关系,供应商和客户类型等。
1. 首先是和GS类似的公司,我们将会把JPMorgan Chase和Morgan Stanley,等公司加入数据集
2. 作为投资银行,高盛公司的发展依赖全球经济。经济不景气或者波动意味着没有并购M&As或者募股IPOs行为,并且可能限制自营收益。这就是为什么我们会包括全球经济指数。另外,我们还将包含LIBOR(以美元和英镑计价)利率,因为分析师需要考虑设定的这些利率和FI证券导致的经济冲击。
3. 每日波动率指数(Daily volatility index)-也是由于之前所述的原因。
4. 综合指数 - 如纳斯达克和纽约证券交易所(来自美国),FTSE100(英国),日经225(日本),恒生和BSE Sensex(亚太指数)指数
5. 货币-全球贸易经常受到货币变动的影响,因此使用一篮子货币(如美元兑日元,英镑兑美元等)作为特征。
总的来说,我们在数据集中有72个其他资产-每个资产的每日价格.
2.2 技术指标
前面已经解释了什么是技术指标以及我们为什么使用他们,所以直接跳到代码实现吧。我们将只为GS创建技术指标。
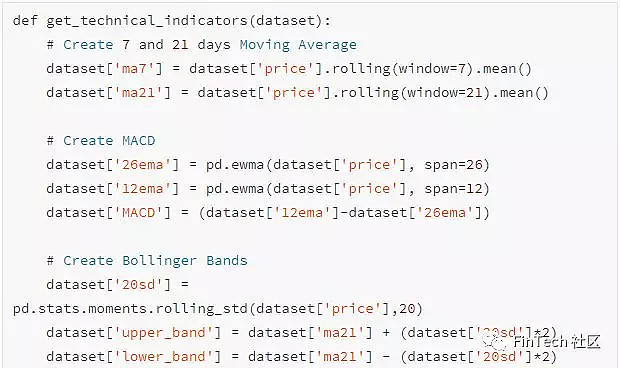




对于每个的交易日一共有12个技术指标,可视化这些指标最后400天的数据。

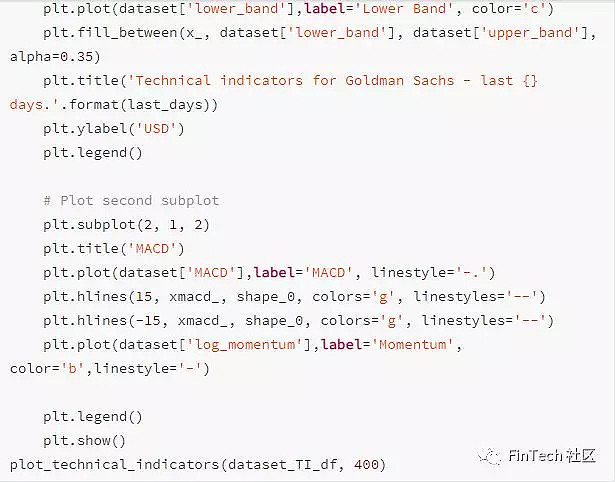
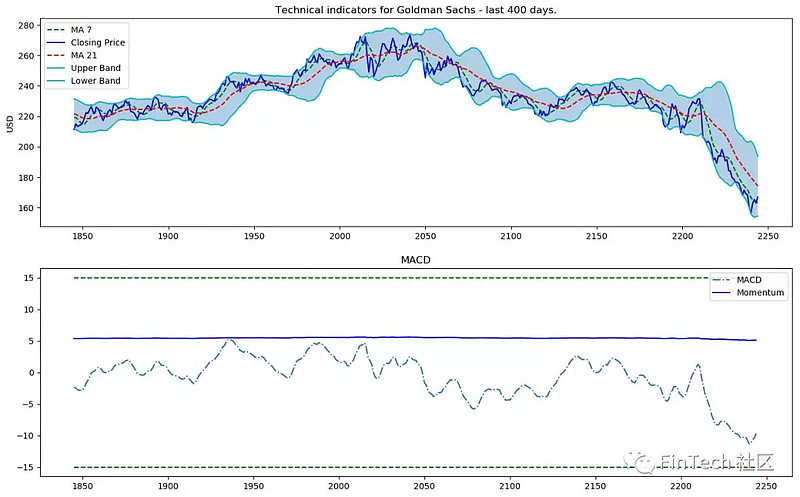
2.3 基本面分析
对于基本面分析,我们将对GS每天的新闻进行舆情分析。最后用sigmoid函数来得到一个0到1之间的结果。结果接近0表示为负面新闻报道,接近1表示正面新闻报道。对于每一天,我们将创建日平均分,并将其作为一个特征加入。
2.3.1.BERT
为了对新闻的正负面进行分类,我们将使用一种预先训练语言表示(pre-trained language representation)-BERT。
MXNet/Gluon中已经提供了预训练BERT模型。我们只需要实例化他们,并加上两个全连接层,通过softmax函数得到0~1之间的分数

这里不具体介绍BERT和NLP的细节,但如果有兴趣,请告诉我,我将专门介绍一下BERT,因为其在语言处理方面非常有用。
2.4. 对趋势分析进行傅里叶变换
傅里叶变换Fourier transforms通过一个函数并创建一系列有不同振幅和帧的正弦波。然后将正弦波结合在一起去接近原始的函数。数学上,傅里叶转换公式如下:
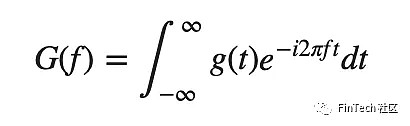
通过傅里叶变化可以提取GS股票的整体和局部趋势,并且降低一部分噪声。来看看它是如何工作的吧。

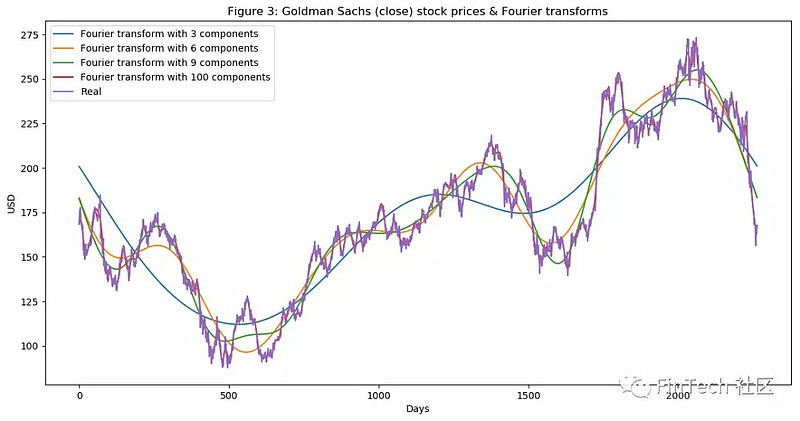
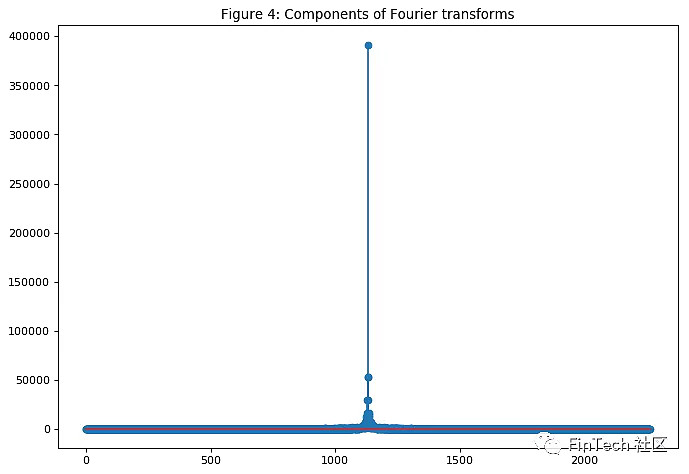
如图所示,傅里叶转换(Fourier transform)中使用的组成成分越多,就越接近真实股价的函数(用100个组成成分就几乎和原始函数一模一样了,红线和紫线已经重叠)。我们打算通过傅里叶变换(Fourier transform)获取长期和短期趋势,所以我们将分别使用3、6、9个组成成分。可以把使用3个组成成分的傅里叶转换(Fourier transform)看成是长期趋势。
另一种降噪技术称为小波(wavelets),两者结果差不多,所以只使用傅里叶变换(Fourier transform)。

2.5 将自回归移动平均作为一个特征
ARIMA是一种用来预测时序数据的技术。我们将展示如何使用它,尽管其不会作为最终预测值,我们将其作为一种用来降噪的技术并通过它提取一些新的特征和规则模式。



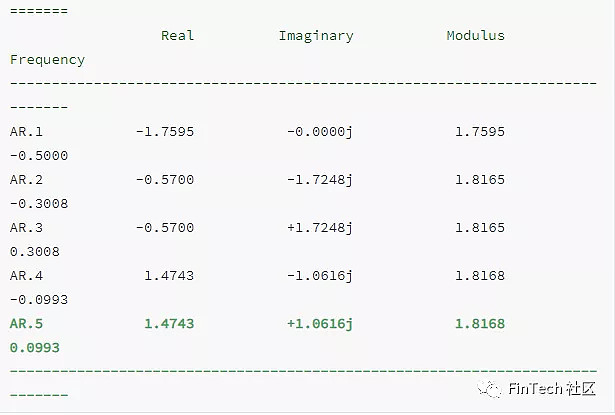

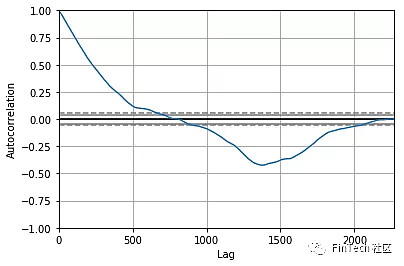

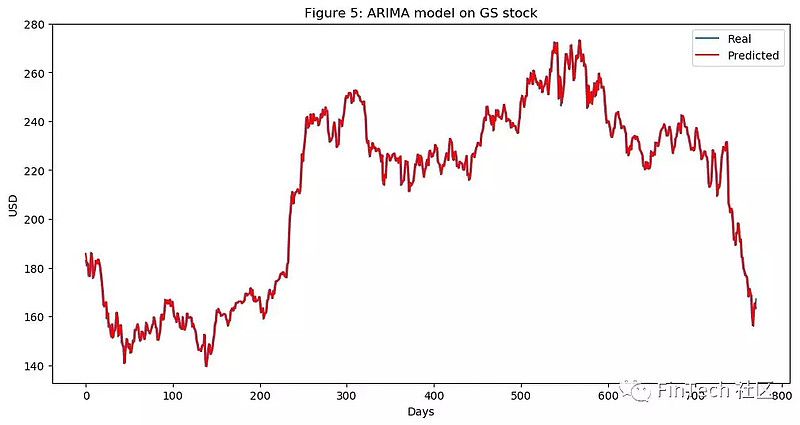
通过图5可以看到,ARIMA给出了非常接近真实股价的结果。我们将使用ARIMA的预测价格作为LSTM网络的一个输入特征,因为我们想捕获到尽可能多的GS公司股票的特征和规则模式。我们使用测试集得到10.151的均方差,考虑到我们有如此多的测试数据,这个结果还不算坏,但我们仍然只将其作为LSTM的一个输入。
2.6 统计检查
确保高质量的数据对于我们的模型非常重要。为了确保数据合适,我们将进行几个简单的检查来确保我们获取和观察的结果是真实的,而不是由分布带有基本错误的底层数据获得的。
2.6.1 异方差性、多重共线性、串行相关性
条件异方差性(Conditional Heteroskedasticity):当误差项依赖于数据时会发生,比如误差项随着数据点一起增长。
多重共线性(Multicollinearity):当误差项(也称残差)相互依赖时发生
串行相关性(Serial correlation):一个特征可以由其他特征得到,完全依赖于其他特征。
因为这里比较简单就不展示代码了,我们主要还是关注深度学习部分,不过数据还是很有决定性的。
2.7 特征设计

加入了所有类型的数据后,对于2265个交易日,我们总共有112个特征值。1585个交易日作为训练数据。我们还将获得更多特征值通过自编码器
2.7.1. 特征重要性
有了如此多的特征值,我们需要考虑他们是否全都对于GS的股票的涨跌有指示性。比如:在数据集中我们包含了用美元计价的LIBOR率,因为我们认为LIBOR的变化可能意味着经济上的变化,并且有可能会影响GS股票的变化。但是我们不用自己去测试。目前已经有许多方法能够测试出特征的重要性,我们将使用到的就是XGBoost,因为他在分类和回归问题上都给出了最好的结果。
因为特征数据集十分的大,为了在这里展示,我们只使用技术指标。通过真实的特征重要性检测后,所有被选择的特征都会被证明有一定的重要性,所以在训练GAN时都不会被排除在外。





将训练损失和验证损失画出来,观察训练过程并检查是否有过拟合问题。


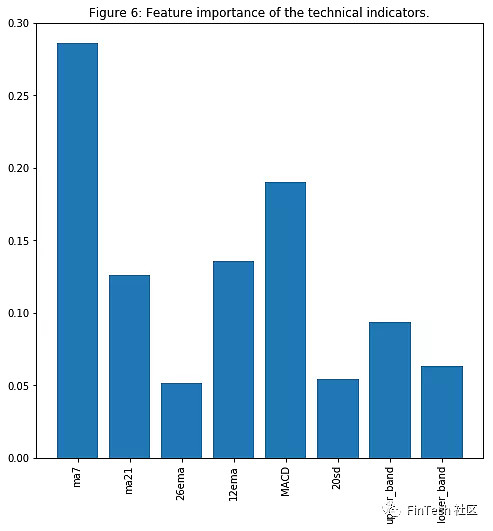
对于那些有股票交易经验的人来说,MA7,MACD,BB是重要的特征毫不惊讶。
我将同样的方法运用到整个数据集上-只不过训练过程更长,结果理解起来更复杂。
2.8 通过堆叠自编码器(Stacked Autoencoders)获得高级特征值
在我们开始自编码器之前,先研究一下一个可供选择的激励函数。
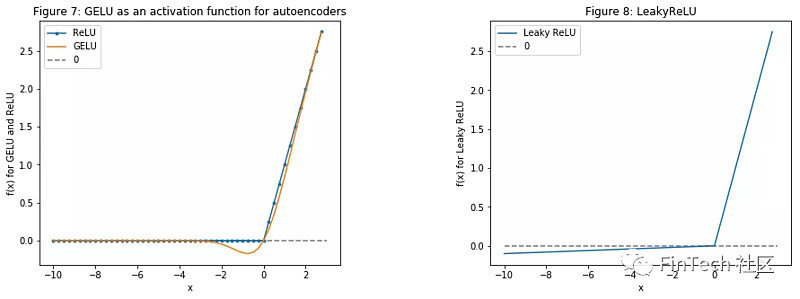
2.8.1 激励函数-GELU(Gaussian Error)
GELU-高斯误差线性单元是最近提出的-链接。在论文中,作者展示了几个在神经网络中用GELU比用ReLu好的实例。GELU也被用在我们之前新闻舆情分析的BERT中。
我们将在自编码器中使用GELU。
注意:下面展示了GELU的数学原理。因为GELU没有被作为激活函数来实现,所以我不得不在MXNet中自己编写。如果你按着代码将act_type='relu' 改为act_type='gelu' ,是不会工作的,除非你更改了MXNet中的实现。并为了访问GELU的MXNet实现,提交一个pull request。
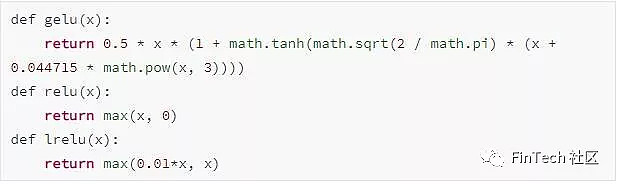
可视化GELU、ReLU、LeakyReLU(主要用于GAN,我们也会使用到)


注意:之后,我将尝试用U-Net(链接)来实现,尝试通过卷积层提取更多关于股票的涨跌规则模式的特征。目前只用一个由全连接层构成的自动编码器。
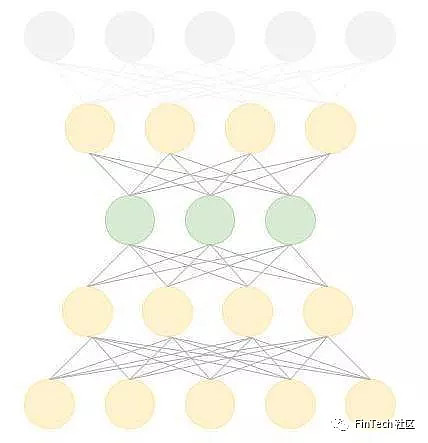
现在回到自编码器,如下面所描述的(这个图只是原理图,并不是实际的层数和单元数。)
注意: 在之后的版本中我将尝试移除解码器的最后一层。通常,自编码器中编码器个数等于解码器个数。然而我们想要更高阶的特征值,所以我们可以跳过解码器的最后一层。在训练期间,我们将构建相同层数的编码器和解码器。但在得到输出时,我们使用最后一层旁边的一层,因为它包含了更高阶的特征值。



编码器和解码器都有三层,每层400个神经单元。


我们通过自编码器得到了112个特征值。因为我们只想要高级特征值,我们将对这112个特征使用主成分分析(PCA)得到一个特征组合(Eigen portfolio)。这会减少数据的维度。特征组合的描述能力和原始的112个特征值是一样的。
注意:这是纯实验性质的,不能百分百保证逻辑成立。因为AI和深度学习是一门艺术并且需要实验。
2.8.2 用主成分分析进行特征组合

为了解释80%的方差我们需要84个特征值。这个数量依然很多。所以目前我们将不包含自编码器得到的特征值。我将创建一个可得到中间层输出并且能与其他全连接层连接起来的自编码器架构。这样,我们将:
获得更高级的特征;
得到更少更有意义的特征值。
2.9. 用于期权定价的异常检测的深度无监督学习
3. Generative Adversarial Network
生成对抗网络(GAN)
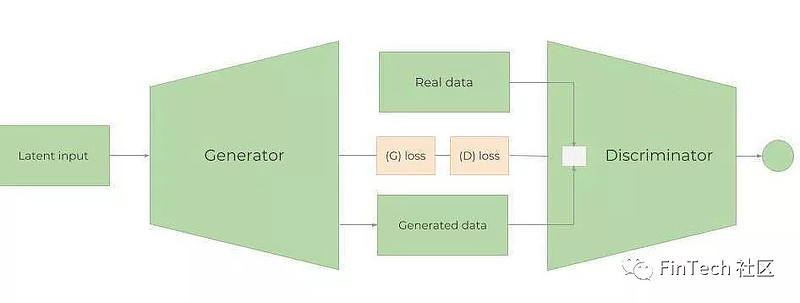
GAN是如何工作的?
如前所述,本文的目的不是为了解释深度学习里的具体数学细节,而是展示它的应用。当然,对于基本原理到极小的细节有非常透彻的理解是非常重要的。因此,为了让读者全面的了解GAN在预测股价走势方面的原理,我们将尝试对于GAN如何工作给出高层次的概括。如果已经了解并使用过GAN可以跳过这两节。
一个GAN网络由生成器(Generator)和判别器(Discriminator)组成。训练GAN的步骤如下:
1. 生成器(Generator)使用随机数据,生成难以区分的或者非常接近原始数据的数据。它的目的是为了学习实际数据的分布。
2. 随机的、实际的或者生成的数据被放进判别器,判别器像一个分类器一样尝试着对于来自生成器或者真实数据的数据进行分类,找出其来自哪里。判别器评估输入样本属于真实数据集的概率(4.2节有更多关于比较两个分布的信息)。
3. 然后生成器和判别器的损失将一起在生成器中向后传播。因此,生成器的损失来自于生成器和判别器。这样做可以帮助生成器学到真实数据的分布。如果生成器在生成一个逼真的数据时做的不好,那么判别器就会很容易分别出来。因此判别器的损失会非常小,判别器的损失小将导致生成器的损失大。这意味着创建一个判别器会有点棘手,因为判别器太好会导致生成器损失过大,使得生成器无法学习。
4. 持续整个过程直到判别器再也区分不出生成数据为止。
当把判别器和生成器组合在一起,判别器和生成器就像在做一种Minmax的游戏(生成器试图欺骗判别器,让判别器对于假样本的概率提高,例如,最小化z∼pz(z)[log(1−D(G(z)))]。判别器则想要通过最大化x∼pr(x)[logD(x)]来区分出来自判别器的数据,D(G(z))。虽然有不同的损失函数,然而,它不清楚两者如何收敛在一起(这是为什么我们使用一些改进过的GAN,例如Wasserstein GAN)。总的来说,这个合并在一起的损失如下:

注意:
1. 可以从这里了解一些训练GAN时有用的方法;
2. 本文中不会包含GAN和强化学习部分完整的代码-只会展示执行的结果。
3.1 为什么用GAN预测股市?
GAN最近主要用于获得逼真的图片,画作和视频片段。很少用在像我们这样的时序数据预测。然而,大体的思路是相同的-只不过我们想要预测未来股票走势。GS股票未来的规则模式和行为应该或多或少是相同的(除非它以完全不同的方式运作,或者经济环境发生剧烈变化)。因此,我们希望生成的将来的数据会和我们已经有的历史交易数据具有相同的分布(当然不是绝对的相同)。所以,理论上是行得通的。
我们将用LSTM作为时序生成器,CNN作为判别器。
3.2. GAN和Wasserstein GAN
注意:接下来的几节假设有GAN的经验
1. Metropolis-Hastings GAN
Metropolis-Hastings GAN(MHGAN)是Uber的研发团队最近提出来的对于传统GAN的一种改进。Uber提出的这个方法背后的思想和Google、加州大学伯克利分校提出的称为判别器舍选抽样Discriminator Rejection Sampling(DRS)的方法有点类似。基本上,当我们训练GAN时,我们使用的判别器的唯一目的是训练出更好的生成器。通常在训练完GAN后,我们就不再使用判别器。然而,MHGAN和DRS尝试使用判别器来选择出生成器生成的最接近真实数据分布的样本(两者不同在MHGAN用马尔科夫链蒙特卡洛法(MCMC)来抽样)
MHGAN抽取生成器生成的K个样本(由输入给生成器的独立的噪声(下图中的z0~zk)生成的)。然后它依次得到k个输出(x'0~x'k)并按照判别器中生成的规则决定是否接受当前的样本还是保留上一个接受的样本。最后保留的输出被作为生成器的一个真实输出。
注意:MHGAN原本由Uber在pytorch上实现了,这里只是将其转为MXNet/Gluon。
2. Wasserstein GAN
训练GAN非常的困难。模型可能永不收敛,模型崩溃也很容易出现。我们将使用一个被称为Wasserstein GAN-WGAN的改进的GAN。
我们不会深入细节,但有几点是非常值得注意的:
众所周知,GAN的主要目标是将随机噪音转换为一些给定的我们希望模仿的数据。因此,对两个分布的相似度进行比较的方法是非常关键的。两种被广泛使用的指标是:
KL差异(Kullback-Leibler)—— DKL(p‖q)=∫xp(x)logp(x)q(x)dx.当p(x)等于q(x)时,DKL为0
JS差异在0~1之间,不同于KL差异,它是对称平滑的。损失从KL变为JS是GAN的训练取得的重要成功。
WGAN使用Wasserstein距离(Wasserstein distance)(也被称为Earth-Mover距离,因为它通常被直观的理解用最少的能量将两个有不同分布的沙堆从一个移动到另一个)作为损失函数,W(pr,pg)=1Ksup‖f‖L≤Kx∼pr[f(x)]−x∼pg[f(x)] 。相较KL和JS差异,Wasserstein指标提供了一个平滑的度量(差异值不会突然跳跃)。这使得它在梯度下降时更适合构建一个稳定的学习过程。
另外,和KL、JS比较起来,Wasserstein 距离处处可微。在反向传播时,我们会对损失求导计算梯度,以此不断更新权重。因此有一个可微的损失函数十分重要。
3.3 生成器——一个RNN层
3.3.1. LSTM or GRU
正如前面所说的,生成器是一个LSTM网络(一种循环神经网络RNN)。因为他们会一直跟踪前面所有的数据点并捕获数据随时间变化的规律模式,RNN被用于时间序列数据。由于他们的自身结构,他们会很容易遇到梯度消失问题(在训练期间,权重的改变过小以至于没有变化,致使网络无法收敛到最小损失。对立的问题也会常常遇到-当梯度太大,称为梯度爆炸,但这个问题的解决方法比较简单,比如梯度裁剪,当他们超过某个常数就对梯度进行裁剪)。有两种修改方式解决这个问题-门控循环网络GRU和长短期记忆网络LSTM。两者最大的不同是:1.GRU有两个门(更新门和重置门),LSTM有三个(遗忘门、输入门、输出门);2.LSTM有神经单元内部状态,GRU没有;3.LSTM在输出门之前用非线性函数(sigmoid),GRU不用。
在大多数情况下,LSTM和GRU得到的结果在准确度上相似,但GRU的计算量更少,因为它需要训练的参数更少。然而LSTM使用的更多。
严格的说,LSTM神经单元内部的数学计算有:
⊙是一个元素级的乘法操作(点乘),对于所有的x=[x1,x2,…,xk]⊤∈R^k,两个激励函数为:
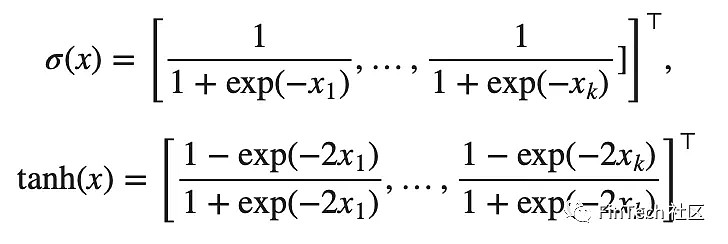
3.3.2 LSTM架构
LSTM架构非常简单,一个LSTM层有112个输入单元(因为数据集中有112个特征值)和500个隐藏单元,以及只有一个输出的全连接层-每天的价格。用Xavier初始化,用L1作为损失函数(即用L1正则化求平均绝对误差,4.4.5节会有更详细介绍。)
注意:通过代码可以看到,我们用Adam(0.1的学习率)作为优化器。不用太关注这里-会有一节专门解释使用到的超参数(由于在4.4.3节中有学习率调度算法,所以这里不包括学习率)以及我们如何优化这些超参数-4.6节


我们在LSTM层使用了500个神经元并用Xavier初始化。为了正则化,我们使用L1。让我们通过MXNet看看LSTM内部有什么。
正如我们看到的,LSTM的输入是将进入LSTM层的500个神经单元中的112个特征值,并转换为唯一的输出-股价。
LSTM背后的逻辑是:我们使用17天的数据(包括GS每天的股价和当天所有其他特征值)预测第18天的。
采用双向LSTM(bidirectional LSTM)层:理论上,反向数据(从数据集末尾到开始)可能会对LSTM寻找股票变化的规律有一定的帮助。
采用多层RNN(stacked RNN)架构-使用不止一层LSTM。不过这样做很危险,可能会由于数据样本不够多而导致过拟合。(我们只有1585天的数据)
研究GRU-像之前解释的那样,GRU的神经单元更简单。
向RNN中添加attention向量。
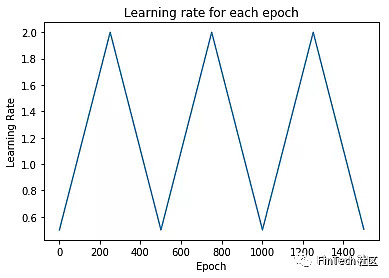
3.3.3 学习率调度算法
学习率是最重要的超参数之一。在训练时对任何优化器的学习率的设定都十分重要,因为学习率决定了收敛的速度和网络的使用性能。最简单的学习率策略是整个训练过程用一个固定的学习率。选择一个小的学习率可以让优化器找到一个好的解,不过却是以限制初始收敛速度为代价。采取随着时间改变学习率的方法可以解决这种权衡。

3.3.4. 如何预防过拟合和偏差方差间的权衡
有这么多的特征和神经网络,我们需要预防过拟合,并且注意整体损失。我们使用了好几种技术来预防过拟合(LSTM、CNN、自编码器中都用到了):
确保数据质量。我们已经进行了统计检查并确保了数据不会有多重共线性或者串行相关性。而且我们还对每个特征进行了特征重要性检查。此外,初始特征(比如:相关资产、技术指标等)的选择是根据对于股市背后的运作机制的相关知识来选择的。
正则化Regularization(惩罚权重weights penalty)。两种使用最广泛的正则化方法是LASSO(L1)和Ridge(L2)。L1向损失中添加平均绝对误差,L2则添加均方差。我们不会太深入具体数学细节,两者基本的不同在于:L1正则化会进行变量选择和参数收缩,而L2只会进行参数收缩,在结束时包含模型中所有系数。对于有相关变量的情况,L2会更好。而且,L2正则化在最小二乘估计(the least square estimates)较高的情况下效果最好。因此,这取决于我们的模型对象。两种正则化的影响是不同的。虽然他们都惩罚大的权重,但L1会将权重减小到零,并且是不可微函数,L2则只会获得较小的权重。因此,使用L1可以得到一个稀疏矩阵-有更少的参数。L1和L2正则化都会使得模型的参数收缩,但使用L1,会收缩到直接影响模型的复杂度(参数的数量)。准确地说,岭回归(L2)在最小化二乘估计有较小值时效果更好。L1在数据稀疏时使用,对极端值更强健,并会进行特征重要性筛选(不重要的特征的权重会降到零)。我们将使用L1。
Dropout:Dropout层会随机移除隐藏层中的部分节点。
使用DSD训练模式
提前停止
构建复杂神经网络时另一个需要考虑的是方差-偏差权衡。我们训练网络时获得的误差是函数的偏差bias、方差variance和不可约误差-σ (由于噪声和随机性导致的误差)。最简单的权衡公式是:Error=bias^2+variance+σ
偏差:偏差体现了通过一个训练集训练出的的算法对未见过的数据的泛化效果如何。高的偏差意味着模型对于未见过的数据效果不好。
方差:方差体现了模型对数据集变化的灵敏度。高的方差意味着过拟合现象。
3.4 CNN 判别器——一维CNN
3.4.1 为什么使用CNN作为判别器?
CNN通常用于图像相关的工作(分类,文本获取等)。他们非常擅长提取特征。比如,有一只狗的图片,第一层卷积会检查边,第二层卷积检查圆,第三层将检测鼻子。在我们的问题中,数据点组成小的趋势,小的趋势组成大的,再接着构成股票的规则模式。CNN检测特征值的能力可以用来提取GS股价波动的规则信息。
另一个使用CNN的原因是CNN擅长处理空间数据。相较散落各处的数据点,彼此邻近的数据点会有更强相关性。这一点对于时序数据也是如此。在我们的问题中,数据点都来自连续的每一天。那么很自然的可以假设越相邻的两天相关性会越强。另一个需要考虑的是季节性(虽然这里没有涉及)以及它是如何影响CNN工作的(如果有的话)。
注意:和本文其他部分一样,对时序数据使用CNN也是实验性的。我们会检测结果,不提供数学或其他证明。使用不同的数据,不同的激活函数,结果可能不同。
3.4.2 CNN架构
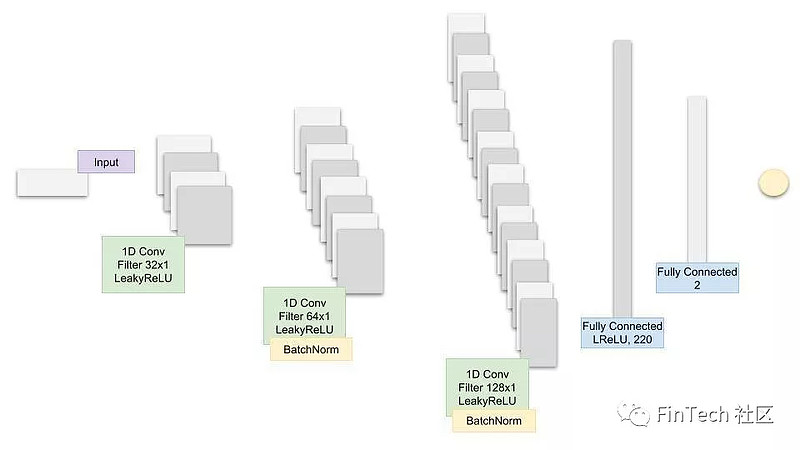
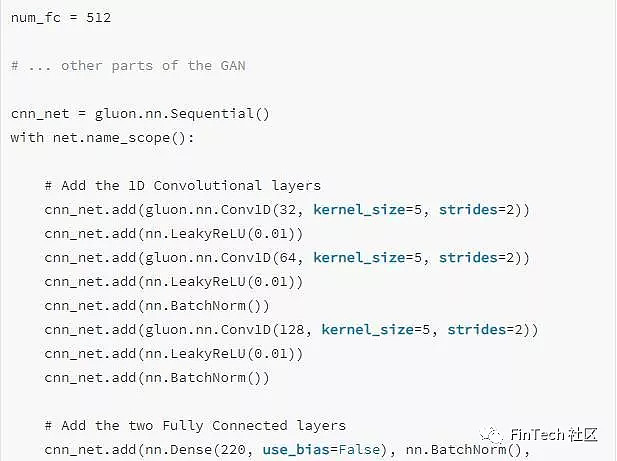
GAN中CNN部分的代码:
打印CNN看一看
3.5 超参数
我们将跟踪和优化的超参数有 :
batch_size : batch size of the LSTM and CNN
cnn_lr: the learningrate of the CNN
strides: the number of strides in the CNN
lrelu_alpha: the alpha for the LeakyReLU in the GAN
batchnorm_momentum: momentum for the batch normalisation in the CNN
padding: the padding in the CNN
kernel_size':1: kernel size in the CNN
dropout: dropout in the LSTM
filters: the initial number of filters
我们将训练200轮。
4. 超参数优化
GAN结束200轮训练后,会记录下MAE(LSTM中的损失函数,GG)并将其作为奖励信号传给决定是否改变超参数的强化学习模型RL。如稍后所述,该方法只用于实验强化学习模型RL。
如果RL决定更新超参数,它会调用贝叶斯优化给出接下来最好的超参数集合。
4.1 使用强化学习进行超参数优化
为什么我们要使用强化学习?股市一直在不断变化。即使我们将GAN和LSTM训练的能够得到非常准确的值,结果也可能只在一段时间内有效。意味着,我们需要不断优化整个程序。为了优化程序我们可以:
1. 增删一些特征值(比如添加可能相关的新股票或者货币)
2. 改进我们的深度学习模型。改进模型的一个最重要方法是通过调整超参数。一旦有了一组超参数,我们需要决定何时改变以及何时使用它(探索和使用)。此外,股市代表了一个依赖于大量参数的连续空间。
注意:本文中强化学习的部分更偏向研究,我们将探索对GAN使用不同的RL方法。虽然除了强化学习RL,还有许多方法可以用来对我们的深度学习模型优化超参数。但是为什么不尝试一下呢。
接下来几节,假设你已经有一定的RL方面的知识,尤其是策略方法policy methods和Q-learning。
4.1.1 强化学习理论
这里不再解释RL的基础原理了,我们将直接介绍使用的方法的具体细节。由于我们不了解整个环境,所以我们使用model-free RL算法,因此我们没有关于环境如何运作的模型-如果有的话,我们就不用预测股价走势了-它会按着模型运作。我们将使用model-free RL的两个分支-策略优化和Q-learning。
Q-learning:在Q-learning中,我们将学习在给定状态下采取一个行为得到的值。Q-value是采取行动后的回报。我们将使用结合了七种Q learning算法的Rainbow。
策略优化:在策略优化中,我们学习在一个特定状态下采取的行动。我们也学习处于特定状态的值(如果我们使用了像Actor/Critic的方法)。我们将使用近端策略优化算法Proximal Policy Optimization(PPO)。
构建强化学习RL算法的一个关键点是正确地设置奖励信号。它必须能捕获环境所有方面以及代理(agent)和环境交互的信息。我们将定义奖励信号,R,为:
Reward=2∗lossG+lossD+accuracyG,
lossG、accuracyG和lossD分别是生成器损失和准确度,以及判别器损失。环境是GAN,结果是LSTM的训练。不同的代理(agent)可以采取的行为是如何改变GAN中判别器和生成器网络中的超参数。
4.1.1.1 Rainbow
什么是Rainbow?Rainbow(链接)是一种结合了七种算法的基于off-policy深度强化学习的Q learning算法:
DQN:DQN是Q learning算法的一种扩展,其使用神经网络来代表Q value。类似监督学习,DQN中我们将训练一个神经网络并尝试最小化损失函数。我们通过随机抽样转换randomly sampling transitions(状态、行动、奖励)来训练网络。这层不仅可以是全连接,还可以是卷积层。
Double Q Learning:Double QL解决了Q learning中过估计的问题。
Prioritized replay:原始DQN中,所有的转换量transitions都存储在重放缓冲区replay buffer并从中均匀的抽取。然而,在学习阶段不是所有的转换量transitions都是同样有用的(也可能由于需要更多的事件场景(episodes)而使得学习效率更低)。Prioritized experience replay不再均匀抽样,而是按能在前几轮迭代中有更高几率获得更高Q loss的分布去抽样。
Dueling network:Dueling network稍微改变了Q learning架构,使用两个独立的流(即用两个不同的微神经网络)。一个流用于value,一个用于advantage。两者共享一个卷积编码器。困难的部分是使用一个特殊的聚合器将两个流合并。
Advantage:公式是: A(s,a)=Q(s,a)−V(s),,是将采用一个行为后的效果和对于某个特定状况下采取的行为的平均效果进行比较。Advantage有时被用于当一个"负面"行为不能被负奖励惩罚时的情况。所以Advantage将尝试从平均行为中进一步奖励正面的行为。
Multi-step learning:Multi-step learning中最大的不同是它使用N-步后的returns来计算Q-values(不只是使用下一步的返回return),自然会更精确。
Distributional RL:Q learning使用平均估计Q-value(average estimated Q-value)作为目标值。然而,许多时候,Q-values可能在不同情况下不同,Distributional RL直接学习Q-values的分布而不是采用他们的均值。这部分的数学比这里说的复杂得多,但对我们来说,好处是Q-vlaues的抽样更精确了。
Noisy Nets:基础的DQN实现了一个简单的-贪婪机制(-greedy mechanism)来进行探索。这个探索的方法有时不是很有效。Nosiy Nets通过添加一个噪声线性层(noisy linear layer)来解决这个问题。随着时间流动,这个网络将学会如何忽视噪声。但这种学习可以在不同的空间以不同的速度学习,能够进行状态探索。
4.1.1.2 PPO
近端策略优化算法(PPO)是一种策略优化Policy optimization的model-free型强化学习。它比较容易实现并且结果也比较好。
为什么使用PPO?一个优势是它直接学习策略policy而不是通过值间接的来学(Q Learning的方式)。它可以在连续的行为空间中效果很好,这很适合我们的情况,并且可以从均值和标准差中学习概率分布(如果softmax作为输出)。
策略梯度方法(policy gradient methods)的问题是他们对于步长选择非常敏感-如果比较小就会花很多时间(很可能是由于需要二阶导数矩阵),如果比较大则会有很多噪声明显地降低性能。因为策略的变化(以及奖励的分布、观察的改变),输入数据是不平稳的。比起监督学习,选择不当更可能会有毁灭性,因为它影响了下次访问的整个分布。PPO可以解决这些问题,除此以外,比起其他方法,PPO:
①不是那么复杂。比如,相较需要附加的代码来保持非策略相关性off-policy correlations和重放缓冲区replay buffer的ACER算法,或者需要对代理项目标函数surrogate objective function(新旧策略间的KL差异性)施加约束的TRPO算法。这个约束是用来控制变化过大的策略-因为可能会造成不稳定。PPO通过使用一个代理目标函数surrogate objective function片段([1- , 1+]之间)的方法和使用由于更新过大而惩罚目标函数的方法来减少计算
②比起TRPO,PPO与在值和策略函数之间或者辅助损失之间分享参数的算法有兼容性(虽然PPO在PO信任区域有增益)。
注意:我们不会太多去研究和优化RL方法、PPO和其他别的。我们将采用可使用的并尝试适用进我们的GAN、LSTM和CNN模型超参数优化问题。
4.1.2 对于强化学习的进一步工作
对于进一步探索强化学习的一些想法:
我下面会首先介绍Augmented Random Search (link)作为一个可选择算法。这个算法的作者已经设法获得了与其他最先进的算法相似的奖励结果,但快了15倍。
选择奖励函数非常重要,我解释了目前使用的奖励函数,但我将尝试不同的函数作为可选项。
使用Curiosity作为一种探索策略
创建一个Berkeley AI研究团队(BAIR)提出的多代理架构
4.2 贝叶斯优化
我们使用贝叶斯优化,而不是使用需要大量时间查找超参数最佳组合的网格搜索。我们用到的库已经被实现了-链接。
只展示初始化部分的代码:

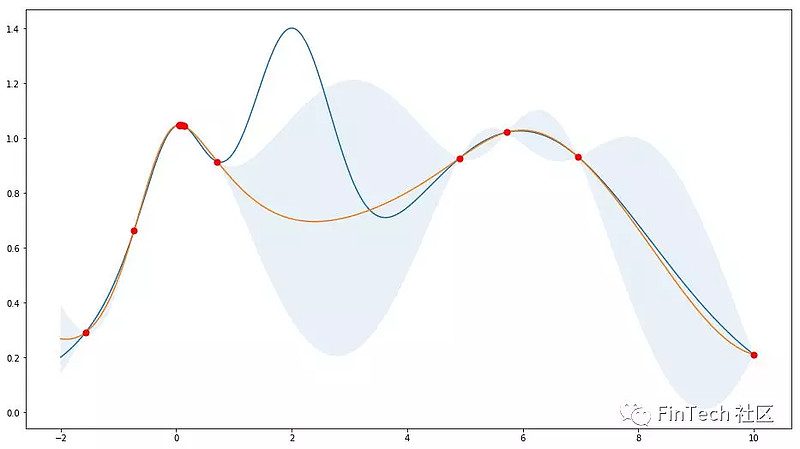
4.2.1 高斯过程
5. 结果

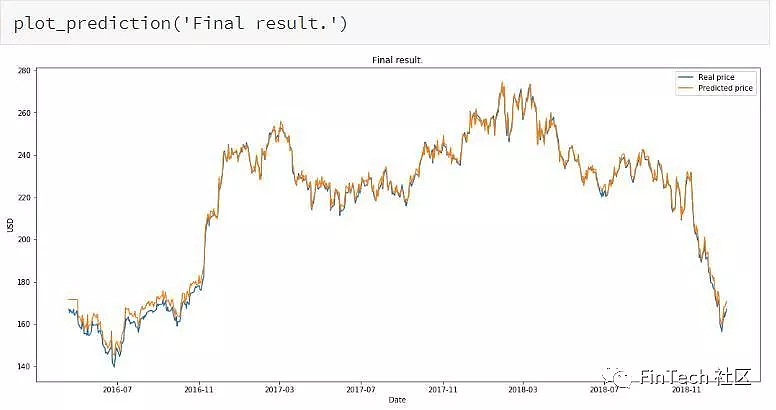
最后我们将比较LSTM在面对测试集里未见过的数据作为输入的效果
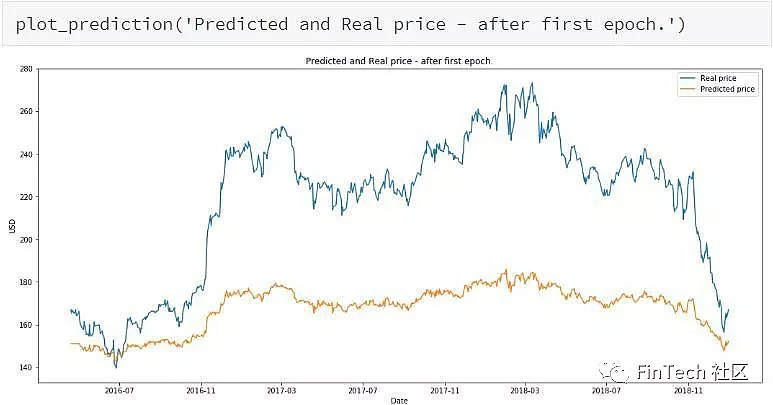
打印第一轮后的结果。
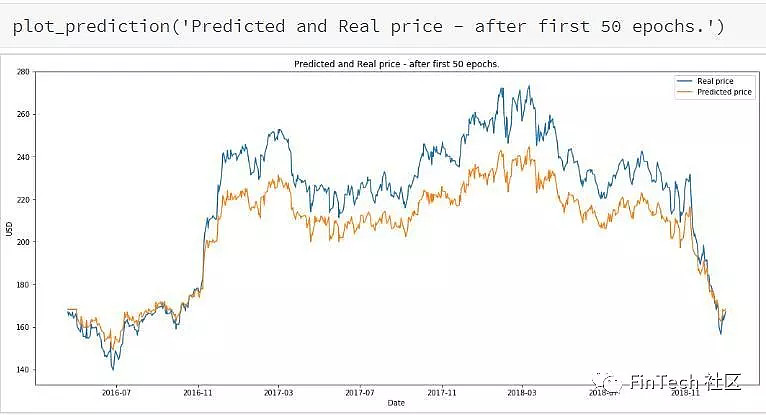
打印五十轮后的结果。
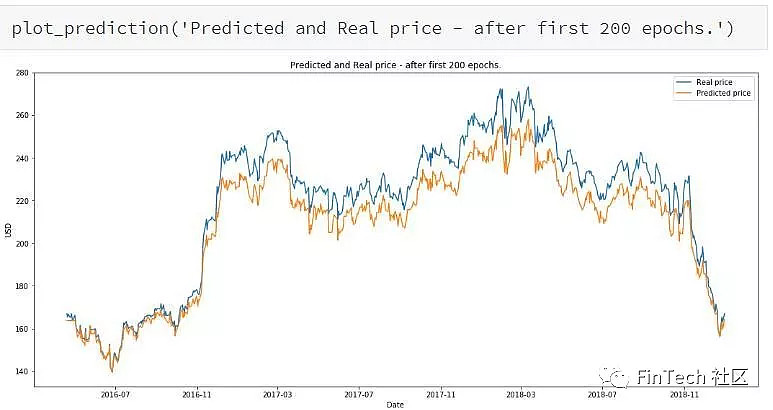
RL运行10episodes后(在1个episode,整个GAN训练200轮)
最终结果。