近期AI PC概念股持续走强,英力股份20cm三连板,隆扬电子、飞荣达等叠加屏蔽材料概念大涨。
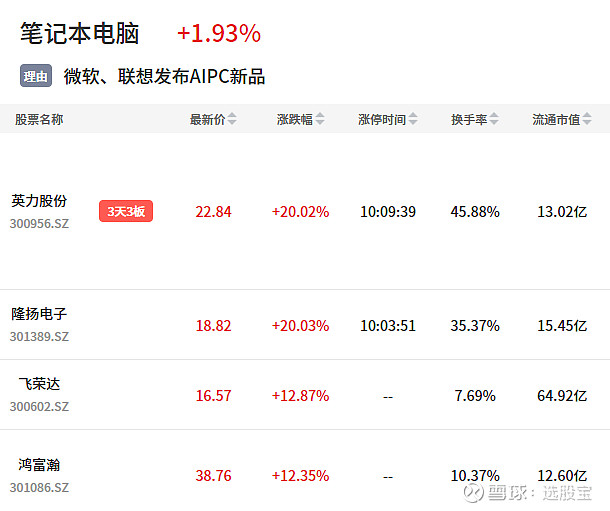
消息面上,微软、联想、戴尔等近期发布搭载骁龙X Elite的全新AI PC。
据高通官方给出的技术参数,在没有云端资源的情况下,骁龙X Elite能够支持130亿参数大模型的终端侧部署与运行,面向70亿参数大模型Meta Llama2-7B时,每秒可生成30个token,比近期发布的竞品AI处理器速度快了4-5倍,是现阶段最快的PC端AI处理速度。
分析认为,骁龙XElite芯片之所以这么强的原因,是因为其为AI引擎系统加入了一个独立的Hexagon NPU以应对AI与神经网络运算需求。
参数显示,Hexagon NPU算力可以达到45 TOPS,而包含CPU、GPU和NPU在内的整个高通AI引擎,可以让骁龙X Elite的AI性能达到75TOPS。
另据高通介绍,Hexagon张量加速器增加了独立的电源传输轨道,让需要不同标量、向量和张量处理规模的A1模型能够实现最高性能和效率。大共享内存的带宽也增加了一倍。基于以上提升和INT4硬件加速,Hexagon NPU成为面向终端侧生成式AI大模型推理的领先处理器。
英伟达、苹果纷纷入局除了高通和微软之外,英伟达、因特尔、苹果也都纷纷加入NPU的潮流之中。
据半导体行业观察报道,Nvidia最近泄露的一份内部演示,解释了该公司显然更喜欢使用独立GPU而非神经处理单元(NPU)来运行本地生成式AI应用程序。这家显卡巨头可能会将其他公司的NPU视为一种威胁,因为自从其处理器成为运行大型语言模型的组成部分以来,该公司的收入猛增。
另外,自去年年底推出Meteor Lake CPU以来,英特尔一直试图将配备该处理器及其嵌入式NPU的笔记本电脑推向新型“AI PC”,旨在执行生成式AI操作,而无需依赖云中的大规模数据中心
NPU,开启端侧生成式AI的关键NPU指的是神经网络处理器,是专为实现以低功耗加速AI推理而全新打造,其架构随着新AI算法、模型和用例的发展不断演进。在高通发布的报告中提到,AI终端面临两大共同的关键挑战。
在功耗和散热受限的终端上使用通用CPU和GPU服务平台的不同需求,难以满足这些AI用例严苛且多样化的计算需求。第二,这些AI用例在不断演进,在功能完全固定的硬件上部署这些用例不切实际。
因此,支持处理多样性的异构计算架构能够发挥每个处理器的优势。每个处理器擅长不同的任务。CPU擅长顺序控制和即时性,GPU适合并行数据流处理,NPU擅长标量、向量和张量数学运算,可用于核心AI工作负载。
天风证券表示,NPU采用数据驱动并行计算的架构,模拟人类神经元和突触,特别擅长处理视频、图像等海量多媒体数据。与遵循冯诺依曼架构的CPU和GPU不同,NPU通过突触权重实现存储计算一体化,运行效率更高,尤其擅长推理。
同时其指出,鉴于终端的功耗和散热限制,通用CPU和GPU难以满足生成式AI应用严苛且多样化的计算需求。这些应用不断演进和多样化,单一硬件部署并不合理。因此,NPU和异构计算成为硬件厂商应对终端侧生成式AI挑战的关键。
用于多个潜在爆发AI端侧除了电脑端外,手机端则更早开始搭载NPU,华为最早在Mate10采用寒武纪NPU,后在990系列上采用自研的达芬奇NPU。
另外,在5月7日苹果据悉的春季发布会上,苹果频繁地提到iPad Pro的AI属性,包括NPU(神经网络引擎)和混合架构下AI性能的领先,也包括在音频、图像创作中的AI体验,并直接对标AI PC。
不仅如此,在汽车、边缘侧如XR及各类物联网智能终端中,NPU也有应用。尤其是自动驾驶,特斯拉FSD的芯片就是以NPU为主。
据悉,特斯拉自研的FSD芯片采用14nm工艺制造,包含一个中央处理器、1个图像处理单元、2个神经网络处理器,其中中央处理器和图像处理器都采用了第三方设计授权,以保证其性能和稳定性,并易于开发,关键的神经网络处理器设计是特斯拉自主研发,是现阶段用于汽车自动驾驶领域最强大的芯片。
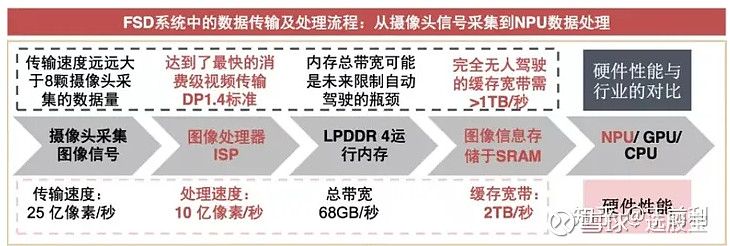
安谋科技产品总监杨磊表示,随着汽车中摄像头、毫米波雷达、激光雷达,以及超声波雷达等环境感知传感器的增多,自动驾驶系统收集的传感器数据将会更多,对自动驾驶计算芯片的算力要求将显著提升,这对NPU是一个大市场。
*免责声明:文章内容仅供参考,不构成投资建议
*风险提示:股市有风险,入市需谨慎