$雅克科技(SZ002409)$ 雅克科技基本面研究。
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
报告出品方/作者:国盛证券,郑震湘,杨义韬,王席鑫)
1.雅克科技:具备全球竞争力的电子材料平台型厂商
1.1.雅克科技是具备全球竞争力的电子材料厂商
公司是具备优质客户资源的电子材料平台型厂商,前驱体业务具有全球领先的竞争力。 近年来,公司通过一系列并购陆续进军了半导体材料硅微粉、电子特气、前驱体以及 TFT 光刻胶、彩色光刻胶,证明了自身全球化外延能力,对标默克路径持续以平台型逻辑成 长。公司半导体材料前驱体业务具备全球竞争力,海外客户包括 SK 海力士、美光、三 星、铠侠和英特尔等,国内客户包括中芯国际、合肥长鑫、长江存储等,海内外客户资 源优质,为中长期业绩放量打下了坚实的客户资源基础。
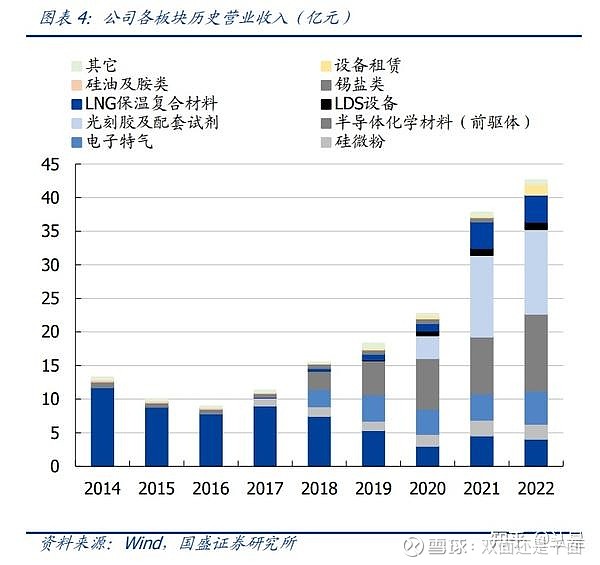
1.2.对标默克,电材龙头持续平台型扩张
2017年以来业绩持续高增长。2022 年,公司实现营业收入 42.59亿元,同比增长 12.61%; 实现归母净利润 5.24 亿元,同比大幅增长 56.61%。自 2017 年开始进军电子材料业务 以来,公司实现了高速成长。2017 年至 2022 年,公司营业收入、归母净利润分别实现 复合增速 30.3%、71.8%。2023Q1,公司实现营业收入 10.71 亿元,同比增长 10.98%; 实现归母净利润 1.73 亿元,同比增长 16.39%。
半导体化学材料(前驱体)是盈利能力最强的业务。随着磷系阻燃剂业务增长放缓,公 司 2014 至 2016 年收入增长乏力。2016 年,公司开始进军电子材料业务,收入结构开 始迅速发生变化。2022 年,电子材料相关业务已占公司收入达 75.8%,占公司利润达 82.0%,并在 2018 年以来贡献了公司主要的业绩成长。在公司电子材料业务中,前驱体 和电子特气是已披露毛利率板块中,盈利能力最强的业务板块,2022 年分别实现毛利率 50.26%、36.87%;成长性方面,前驱体是公司增长最快的业务,受核心客户 SK 海力士 订单增长拉动,前驱体业务 2017 年以来实现 43.0%的复合增速,营收由 2018 年的 2.74 亿元增长至 2022 年 11.43 亿元。
盈利能力随业务结构的变化而抬升,趋势持续。公司 2021/2022/2023Q1 分别实现毛利 率 25.8%/31.2%/32.5%。受益于良好的费用控制能力,公司销售费用率 2019 年开始明 显下降,公司 2021/2022/2023Q1 分别实现净利率 9.0%/12.8%/16.3%。后续受益于前 驱体、高性能硅微粉等业务的强势增长,预计盈利能力将持续抬升。

2.AI驱动HBM放量,前驱体龙头迎崭新机遇
2.1.AI对计算量需求呈指数级增长
AI 模型需要处理的计算量呈指数级增长,对 GPU 的数据吞吐能力提出更高要求。AI 模 型的计算量与参数量和需要处理的数据量有关,现行模型的参数量增长极快,2019 年 2 月发布的 gpt-2 参数量仅 15 亿,2020 年 5 月发布的 gpt-3 参数量高达 1750 亿。根据 OpenAI 报告,全球 AI 训练所用的计算量呈现指数增长,平均每 3.43 个月便会翻一倍, 目前计算量已扩大 30 万倍,更大的计算量意味着需要显卡提供更强的数据吞吐能力。
处理 AI 大模型的海量数据需要宽广的传输“高速公路”来吞吐数据,也即 GPU 的带宽 需要得到拓展,对高带宽存储芯片(HBM)的需求激增。图形处理器 GPU 是专于并行 处理数据的处理器,为 GPU 核配置的存储芯片起到创建并行处理通道的作用,存储芯片 的带宽决定了多核架构 GPU 的性能,用 GPU 持续对输入输出的数据进行处理时的单次 数据吞吐量来衡量。单枚 GPU 的带宽与显存位宽、显存数据频率成正比,而显存频率虽 高,但其面临着提升上限的问题,拓展显存位宽是满足 GPU 高带宽要求的更佳路径。显 存的位宽又由显存类型直接决定,HBM(高带宽存储器)的位宽是 GDDR5 的 32 倍之高, 即使数据频率相对略小,但总带宽显著高于 GDDR,更适合与 GPU 合封用于 AI 大模型 的训练和推理。
HBM 能提供高带宽,需求有望随 AI 服务器增长。深度学习训练要求 GPU 之间、CPU 与 GPU、内存与存储之间的通信采用更高效率数据传输方式。在 AI 大模型涌现提高对 HBM 需求之前,AI 服务器多采用图形双倍数据速率存储器 GDDR 来满足 GPU 带宽要求。HBM 虽有灵活性欠佳、访问延迟高的不足之处,但其优异的带宽表现使得其尤其适配于 GPU 计算这种延迟性要求低、带宽要求高的并发工作。相对于 GDDR6,HBM2E 的芯片密度 达到其 7 倍,芯片面积节省 87.5%,而海力士新推出的 HBM3 产品带宽在上一代 HBM2E 产品的基础上又翻一倍,无疑是 AI 服务器的更佳选择。
自 2014 年初代 HBM1 首次问世以来,HBM 产品已经历三次迭代,以 SK 海力士为首的 海外头部存储企业是引领 HBM 产品迭代的主力军。 HBM1:首次使用 TSV 技术,由 SK 海力士联合 AMD 于 2014 年最早推出: 2014 年,SK 海力士与 AMD 联合开发了全球首款硅通孔 HBM 产品。HBM1 的工作 频率约为 1600Mbps,漏极电源电压为 1.2V,芯片密度为 2GB(4-hi)。HBM1 不仅 带宽显著高于同时期的 DDR4 和 GDDR5 产品,还具备外形尺寸小、消耗功率低的 多重优势,更能满足图形处理单元 GPU 等带宽需求较高的处理器。凭借 HBM 初代 产品,海力士在高带宽存储市场上夺得先机。

HBM2E:SK 海力士率先将堆叠芯片数目翻倍,成为同期最快的存储器解决方案: SK 海力士最早于 2020 年抢先发布 HBM2E 产品,通过对 8 枚 DRAM 芯片的堆叠, HBM2E 的容量拓展至 16Gb,是 HBM2 的两倍。HBM2E 的数据处理速度达 3.6Gbps, 每秒可处理 460GB 的数据,是当时业界最快的存储器解决方案,散热性能也提高了 36%。
HBM3:增加 ECC 校验功能提高可靠性,是目前高性能 AI 训练用 GPU 的标配: SK 海力士在 2021 年 10 月开发出全球首款 HBM3,并于 2022 年正式向市场发布, HBM3 产品最高可堆叠芯片数目增至 12 枚,HBM3 采用 16 通道架构,运行速度再 次翻倍达 6.4Gbps,尤其适用于 AI、HPC 等容量密集型应用。HBM3 中新增了 ECC 校验(On Die-Error Correcting Code)功能,可使用预分配的奇偶校验位来检测和 纠正接收数据中的错误。凭借该功能,DRAM 可完成数据自我纠错,从而提高设备 的可靠性。2023 年 4 月,海力士宣布发布最新款 12 片堆叠的 HBM3 产品,容量拓 展至 24GB,性能再次提升。
得益于 TSV 技术,信号传输路径更短、物理接口更少的 HBM 在提升带宽的同时具备更 低的功耗、更小的封装面积。HBM 通过硅通孔(TSV)技术将数个 DRAM 裸片垂直堆叠 在芯片 Z 轴进行电气连接和物理延伸,相比于传统的倒装焊和引线键合,TSV 无需布线、 多层堆叠。一方面,在晶圆上直接打孔的方式通过去耦 I/O 负载提升了引脚速率,并通 过消除堆叠芯片上不必要的重复电路组件实现了数据吞吐量的增加,显著提升带宽。另 一方面,TSV 同时缩短了电传导通路,减少信号延迟、互联密度更高。TSV 技术核心在 于通孔制作,在芯片上打下数千个孔道,需要依次完成硬掩膜图形化后深硅刻蚀孔内清 洗、PEALD 沉积、电镀、退火等多个步骤,孔的成型、填孔电镀、减薄和键合都是 TSV 的难点所在,因而目前能够掌握 TSV 技术并将其应用于 HBM 领域的企业并不多见。
英伟达、AMD 多款产品率先使用 HBM 显存,NVIDIA H 系列作为最早搭配有 HBM3 的 GPU 产品能大幅提升 AI 大模型的训练速度。HBM 的早期产品 HBM1、HBM2、HBM2E 在英伟达 A 系列、AMD Radeon 系列中有广泛应用,目前最早搭配有 HBM3 的产品是英 伟达推出的 H100,这款为大型语言模型所准备的产品由两张 H100 计算卡通过 PCIe 桥 接组成,单个 H100 可支持 40Tb/s 的 IO 带宽,共能提供 188GB HBM 3 显存。基于四对 H100 以及双 NVLINK 的服务器可以将大模型计算处理速度提升 10 倍,软硬件的优化后 训练速度最高可以提升 30 倍。

2.2.AI服务器拉动下,HBM有望在2027年增长至超过6000万片
AI 服务器可划分为推理服务器、训练服务器两种类型。训练过程即利用大量数据进行学 习的过程,从而使得训练后得到的模型具有一定通用性。而推理则是指使用已经训练好 的模型参数对新输入进行处理,无需再计算梯度或更新参数。 训练服务器:大模型持续发布,叠加参数量等驱动 AI 训练服务器需求增长。 参数量:模型的训练过程对算力的需求极为庞大,以 ChatGPT3 为例,单个模型的 参数量从 GPT-2 的 15 亿快速增长至 1750 亿,两个模型发布间隔仅 15 个月。而根 据 OpenAI 报告,全球 AI 训练所用的计算量已扩大 30 万倍,更大的计算量意味着 需要更多显卡提供更强的数据处理和吞吐能力。然而,在新一代 GPT5 模型发布前, 我们假设现有模型参数量的增长速度或适度放缓;
模型数量:ChatGPT 推动了国内外头部互联网企业加速布局大模型,根据 Data Learner,2022 年初以来发布的参数量在 1000 亿以上的大模型多达两位数水平,然 而大模型训练投入成本极高,根据《财经》报道,一个完整的模型训练成本超过 1200 万美元。不具备规模体量的公司更有可能直接利用头部企业已训练好的大模型延伸 出在特定场景下应用的定制化模型,从而大幅节省训练成本。据此,我们假设全球 新增大模型数量在 2025 年前快速增长,2025 年后增量维持。
训练词数:语料库在模型训练中起到帮助模型掌握特殊术语和语言规则的作用。根 据 OpenAI,ChatGPT-3 广泛吸纳了来自 CommonCrawl,Wikipedia 等的开源语料 和 WebText2,Books1,Books2 等非开源的语料,用于训练的语料库增加至 3000 亿 token(word piece),预训练数据量从 5GB 增加到 45TB,渠道来源涵盖有书籍、 网页、社交媒体平台、百科、代码等形式。考虑到现有模型语料库构成已非常全面, 我们假设在 ChatGPT-5 问世以前,训练词数的年增长量将保持在 400-500 亿左右 的较小区间,2027 年训练词数规模约达到 5000 亿。
推理服务器:峰值访问量增长等因素驱动 AI 推理服务器需求增长。训练完毕后的模型 会面向互联网用户开放使用。我们认为未来 AI 服务器的日访问量上限可以朝全球最大的 搜索引擎谷歌看齐。目前谷歌旗下多个产品的日活达到 10 亿以上。由于使用热潮真正席 卷全球的大模型 ChatGPT 是在 2022 年底才开放测试,虽然日活用户增速极快,但用户 基数仍尚不及头部互联网巨擘,故我们假定全球所有新大模型的单日访问人数为 6 亿人, 在此后年份内增长至 20 亿人,平均访问次数保持为 12 次,在此基础上计算得到的 2023 年、2027 年峰值访问量分别为 72 亿人次和 243 亿人次。考虑到访问峰值可能是一天均 值的数倍,截至 2023 年 2 月,ChatGPT 日访问量已超 2500 万,搭载有 GhatGPT 的 Bing 日活也快速突破一亿。
经我们测算,HBM 需求有望在 2027 年增长至超过 6000 万片。根据半导体行业观察, 单颗英伟达 H100 GPU 配备有 6 个 HBM 内存堆栈,每个堆栈的容量为 16GB。但出于良 率原因,H100 部件中实际只有 5 个 HBM 堆栈,即 DRAM 总容量标称为 96GB,但产品 实际容量为 80GB。我们认为单 GPU 内 HBM 数目将存在小幅提升可能性,主要系英伟达 提供了 NVLink 图灵显卡架构,该架构下显卡可以实现双通道互联,即一张计算卡内共有 2 个 GPU,各自能提供 6 个 HBM 堆栈,合计单卡 HBM 需求量约为 12 枚。但考虑到该 架构目前仅英伟达采用,全部客户可能仅有小部分有意向朝此架构转型,故我们认为 1 颗 GPU 实际上大致对应 5 枚 HBM 的情景有望在预测期内维持。
HBM 持续迭代,对材料的单位消耗量有望持续增长。自 2013 年海力士首次应用 TSV 技 术首次研发出 HBM1 至今,HBM 技术已经历四次更替(HBM2、HBM2E 同为第二代产 品),从 4 层堆叠向 8 层、12 层堆叠持续迭代,带宽上限不断突破。海力士于 2021 年 10 月开发、2022 年 6 月实现量产的全球首款 HBM3 通过堆叠多达 8 个 DRAM 裸片和可 选的基础裸片可提供高达 819GB/s 的带宽,数据传输速率由上一代主流产品 HBM2E 的 3.6Gbps 提升至 6.4Gbps,单引脚的性能提高 100%,性能进一步升级。HBM 迭代升级 尚未终止,2023 年 4 月海力士已经宣布推出堆叠层数多达 12 层容量为 24GB 的下一代产品,我们认为堆叠层数达 12 层的新一代产品或在 1-2 年内集中放量,对 DRAM 裸片 及前驱体的消耗价值将进一步增长。
HBM 格局集中,SK 海力士为全球龙头,领跑高端 HBM 份额,根据 Statista,2022 年 前三季度三星、SK 海力士、美光 DRAM 市占率分别为 42.7%、27.7%、24.7%,CR3 高 达 95.1%。HBM 是传统 DRAM 的一次技术性升级,SK 海力士依托 2013 年 HBM1 以来 10 余年的生产研发经验,成功卡位全球最大供应商,市占率高达 50%。根据 CINNO Research,SK 海力士在全球高附加值 HBM 市场占 70%-80%份额。目前 SK 海力士正在 开发 HBM4,预计新一代产品将在高性能数据中心、超级计算机和人工智能领域得到更 广泛的应用。

2.2.雅克前驱体业务具备全球竞争力,将受益HBM放量
随着晶体管体积持续缩小,传统 SiO2栅极电介质受介电性能达到极限,在 45nm 内先进 制程芯片中会产生隧穿现象从而导致漏电,从而造成晶体管可靠性下降。High-K 前驱体 相比传统 SiO2 具有更强介电常数,SiO2、High-k 前驱体介电常数分别为 3.9、10-60。相 比传统工艺,High-K 前驱体可使栅极漏电流减少 10 倍左右,同时降低工作电压,使得 材料理论性能提升 20%。High-k 前驱体的 k 值应大于 12,最好在 25-35 之间。并且前 驱体的 k 值与禁带宽度(Band Gap)之间需要有一个协调平衡,一般要求禁带宽度大于 5eV。满足上述 k 值以及禁带宽度要求的主要包括 Al2O3、ZrO2、HfO2、Y2O3、La2O3、镧 系元素以及它们的硅酸盐、铝酸盐。
NAND 堆叠层数增加拉动前驱体用量成倍提升,ALD 沉积适用于 3D NAND 的三维结 构,拉动 High-k 前驱体需求。3D NAND 类似于盖楼房,在 2D NAND 的基础上进行堆 叠,从而在面积不变的情况下成倍提升存储容量。由于每一层 NAND 都要进行薄膜沉积, 因此对于前驱体的需求将同步成倍增长。3D NAND 储存设备中的三维结构需要高度的工 艺可变性控制,ALD 非常适用在储存器孔的侧壁上形成介电薄膜。金属 ALD 也用于替换 栅极方案中的字线填充,这需要横向沉积来完全填充狭窄的水平特征。
DRAM 深宽比提升,拉动 High-k 前驱体需求。同样,DRAM 存储器容量也处于持续提 升中。传感器信号的传递速度、工作效率通过减少栅的宽度(L)来提升。根据 Omidia, 目前全球主流 DRAM 容量为 8Gb,占比约 70%,预计 2025 年 16Gb 占比将超过 50%。 根据 ASML,目前 DRAM 主流产品制程为 1Z(12-14nm),预计 2022-2023 年将达到 1A (10nm 以内)。伴随器件尺寸的缩小,DRAM 深宽比持续提升,所需前驱体介电常数更 高。因此 DRAM 制程的进步,将持续打开 High-K 前驱体的需求空间。
前驱体是半导体薄膜沉积工艺的核心制造材料,随着逻辑、存储芯片制程的演进产品用 量及附加值持续提升。根据 GlobaI Info Research,预计 2028 年全球半导体前驱体市 场规模将由 2021 年的 19.4 亿美元提升至 36.6 亿美元,中国市场规模将由 5.9 亿美元 提升至 11.6 亿美元。前驱体在半导体中应用环节包括薄膜沉积、外延生长、刻蚀环节, 其中薄膜沉积需求占比约 84%。薄膜沉积环节本质上是将晶圆上各层功能性材料附着在 衬底表面的技术,是下一步光刻、刻蚀工艺的前提。目前主流的半导体薄膜沉积技术包 括 PVD(物理气相沉积)、CVD(化学气相沉积)、ALD(原子层沉积)等技术路线。

逻辑制程节点升级、先进制程产能提升带来新前驱体材料需求和规模增长。半导体制造 行业始终在追求提高性能的同时降低成本,新的器件结构、新的沉积材料对 CVD 特别是 ALD 环节带来新的机遇。举例来说,铪(HfO2)仍然是栅极 High-K 主要材料,同时氧化 镧(La2O3)作为掺杂材料也将有所贡献,此外由于更多金属化层的需求,钴前驱体在 20nm 及以下逻辑节点需求增长迅速。雅克核心子公司 UP Chemical 是韩国存储芯片龙 头 SK 海力士核心供应商,同时进入合肥长鑫、长江存储核心供应链,将充分受益于行业 成长。随着 HBM 堆叠 DRAM 裸片数量逐步增长到 8 层、12 层,HBM 对 DRAM 材料用量将 呈倍数级增长。同时,前驱体单位价值量也将呈倍数级增长,前驱体有望迎来崭新发展 机遇。
3.海外供给遇不可抗力,LNG板材高景气持续
3.1.复合板材是LNG船关键材料,竞争格局极佳
LNG 运输船危险系数高、制造难度大,被称为“沉睡的氢弹”,对核心材料 LNG 板材要 求极高。液化天然气的密度约 430-470kg/m3,常温下气化体积迅速膨胀,是液态的 625 倍。若产生泄漏,急剧膨胀会产生物理爆炸。同时,液化天然气沸点是-162℃,LNG 运 输船要长时间维持-163℃的低温。因此,LNG 运输船被人们称为“沉睡的氢弹”。LNG 船 需要在-163℃的极低温下运输液化天然气,对运输系统、材料要求极高,是世界造船工 业“皇冠上的明珠”。为了满足我国对 LNG 能源需求的不断增长,保证国家的能源供应 安全,近年来沪东中华造船、江南造船和大连重工等国有大型船厂都重点发展大型 LNG 海运船。
复合板材是 LNG 薄膜型储罐关键材料,雅克是国内唯一得到法国 GTT 认证的供应商。 无论是在 Mark Ⅲ还是在 NO96 Super+系统中,LNG 板材都是核心材料。LNG 储罐运用 的增强型绝缘保温复合材料能承受的极限温度可达-170℃(天然气的凝点为-161.5℃)。 从结构上看,薄膜型储罐的主要部件包括主层薄膜、次层薄膜和预制泡沫板。
复合板材原料 RSB、FSB 国产化有望带来成本大幅下降。目前以金属材料、玻纤布、三种树脂(按一定配方)制成的次层薄膜是 MARK Ⅲ型系统复合板材的核心原材料,包括 了用于平面型板材的 RSB 以及用于边角板材 FSB,目前依赖从韩国供应商进口。RSB、 FSB 占复合板材成本比重高,公司突破自产工艺,LNG 板材业务成本将实现大幅下降。LNG 储罐需求水涨船高,进一步拉动板材需求。根据沪东造船厂,LNG 接收站中的储罐 与 LNG 船运输环节紧密配套,船运来的 LNG 经卸船装置输送到 LNG 接收站中的储罐内 进行储存,并加以气化后通过管道输送给下游用户,或通过槽车直接运输给卫星站、调 峰站。当前日本、美国及韩国等发达国家的 LNG 接收站建设技术已非常成熟,而我国尚 处于高速成长期,增长空间大。

3.2.LNG板材订单旺盛,海外供应受限,进入高景气
很长时间内,LNG 运输船生产能力主要由三星重工、大宇重工、现代重工等韩国造船厂 垄断。我国沪东造船厂、江南造船厂已于近年突破大型 LNG 运输船生产能力,订单于 2021 年开始出现可观增长。2021 年,全球共有大型 LNG 运输船订单 75 艘、中型 LNG 运输船订单 3 艘、小型 LNG 运输船订单 12 艘,预计将于 2023 年至 2025 年集中交货,其中 7 艘大型、3 艘中型、5 艘小型 LNG 船来自于沪东造船厂、江南造船厂、中集太平 洋海工、招商局重工等国内造船厂。2022 年订单井喷式增长,我国造船厂承接订单份额进一步提升。根据 Clarksons,2022 年全年全球船东订购了 184 艘液化天然气运输船,同比 2021 年全年总数翻倍增长,几 乎是过去十年平均 49 艘的四倍。中国造船厂共承接 59 艘船订单,占全球总量达 32%。
LNG 板材在手订单十分可观。公司作为国内唯一通过法国 GTT 认证的 LNG 保温绝热板 材的供应商,目前已经取得了 LNG 保温绝热材料的全系列标准认证,并且拥有完整的自 有技术、先进的生产工艺和高度智能化的生产线。公司通过了法国 GTT 公司、挪威船级 社、英国劳氏船级社和美国船级社等所有的造船业国际权威机构的认证,取得了国际船 东和大型造船公司的信任。目前,公司已经建立了与沪东中华造船厂、江南造船厂和大 连重工等大型船厂的战略合作业务关系,并于 2022 年 9 月 15 日公告获得沪东造船厂 20.66 亿元订单。
2023 年 4 月 21 日早上 4:57 分,公司 LNG 板材主要对手韩国 Hankuk Carbon 着火,火 势已蔓延至密阳工厂 80%厂区。在 2018 年 3 月雅克科技获得沪东造船厂订单前,韩国 Hankuk Carbon 和 Dongsung FINETEC 占据 LNG 板材全球 90%份额。公司 LNG 板材主 要对手韩国 Hankuk 遭遇不可抗力,有望使得公司在未来获得更大市场份额。
4.硅微粉:剑指半导体高端填料国内龙头,替代日系厂商
EMC 封装占比达 97%,硅微粉占 EMC 成分 70%-90%。塑料封装成本低、适合大规 模生产、效率高。2019 年全球集成电路封装中的 97%采用 EMC(环氧塑料封装)作为 外壳材料,而其中的 70%-90%为硅微粉。EMC 组成成分主要包括环氧树脂及其他聚合 物、添加剂、填料,为达到无限接近于芯片的线性膨胀系数,硅微粉在集成电路封装材 料的填充量通常在 75%以上,成为了最主要的封装填料。
球形硅微粉更适用于芯片封装。硅微粉分为球形硅微粉、角形硅微粉,球形硅微粉是以 精选的角形硅微粉作为原料,通过火焰法加工成球形的二氧化硅粉体材料,具有流动性 好、应力低、比表面积小和堆积密度高等优良特性。球形硅微粉填充率高于角形硅微粉, 能够显著降低覆铜板和环氧塑封料的线性膨胀系数,使其更加接近于单晶硅的线性膨胀 系数,从而显著提高电子产品的可靠性;用球形硅微粉制成的环氧塑封料应力集中小、 强度高,相较于角形硅微粉更适合用于集成电路芯片封装,同时球形硅微粉可以减少相 关产品制造时对设备和模具的磨损。球形硅微粉的优势包括:
球形流动性好,填充量高:球形硅微粉主要应用 Horsfield 的紧密堆积模型,通过不 同粒径的球形硅微粉进行组合,从而使填充空间的空隙率达到最小。在环氧塑封料 行业,角形二氧化硅填充量一般低于总量的 70%(重量比),采用球形二氧化硅后, 填充量最高可达 94%;在覆铜板行业,角形二氧化硅填充量一般低于总量的 40%, 采用球形二氧化硅后,填充量最高可达 60%。 应力小、强度高:与角形硅微粉制成的塑封料相比,球形的塑封料应力集中最小、 强度最高,当角形粉的塑封料应力集中为 1 时,球形粉的应力仅为 0.6。由此制成 的微电子器件成品率高,便于运输、安装,并且在使用过程中不易产生机械损伤。
对模具磨损小:相比于角形硅微粉,球形粉摩擦系数小,对模具的磨损小,使得模 具的使用寿命可提高一倍。 比表面积和吸油值更低。硅微粉粒度越细,比表面积越大,相同填料添加量条件下 胶水粘度越大,分散越困难。对低 cut 点产品为了改善胶水粘度、提高填料在胶水 中的分散性,除表面改性外,还可以对其进行球形化。球形硅微粉产品与角形硅微 粉产品相比比表面积和吸油值会有大幅降低。

雅克科技子公司华飞电子产品为球形硅微粉,相比对手产品均价高,主要应用于芯片封 装。并且当集成电路的集成度为 1M-4M 时,环氧塑封料应部分使用球形硅微粉,集成度 8M-16M 时,则必须全部使用球形硅微粉。硅微粉用于电子封装是不可替代,集成电路 产业使用球形硅微粉代替普通角形硅微粉已是大势所趋。2021 年全球 EMC 用硅微粉需求约 9.7 万吨。2018 年国内环氧塑封料年产能力约为 10 万吨。行业实践中,硅微粉在环氧塑封料的填充比例为 70%-90%之间,取填充比例的平 均值 80%进行测算,硅微粉在国内环氧塑封料行业的市场容量为 8 万吨。假设 EMC 封装份额维持稳定,全球环氧塑封料需求与全球封测材料需求匹配同步增长,则 2021 年 全球环氧塑封料用硅微粉需求约 9.7 万吨。
全球球形硅微粉约 70%被日系厂商垄断。根据中国粉体技术网于 2018 年 3 月发布的 数据,电化株式会社、日本龙森公司和日本新日铁公司三家企业合计占据了全球球形硅 微粉 70%的市场份额,日本雅都玛公司则垄断了 1 微米以下的球形硅微粉市场。 Underfiller、low-α等高端硅微粉价值量远高于普通 EMC 球形硅微粉,国产化空间大。 Underfill 硅微粉主要用于倒装芯片的底部填充,用于减少由于芯片与基板热膨胀系数不 同带来的应力。由于 Underfill 材料的应用,芯片焊接点的使用寿命得以大幅提升;用于 存储芯片封装需要用到低α射线的硅微粉,避免因α粒子放射带来存储芯片的数据错误, 价格可达普通 EMC 用球形硅微粉的数倍。总体而言,硅微粉等集成电路领域有许多高端 品类,目前被日系厂商垄断,国产化空间巨大。
华飞电子在建高端材料 3.9 万吨,剑指替代日系厂商份额。华飞电子主要产品是球型硅 微粉,用于集成电路封装材料(塑封料)、高压电气件的绝缘浇注及分立器件。华飞电子 产品主要销售给住友电木、台湾义典、日立化成、德国汉高、松下电工等国际知名环氧 塑封料的生产商,另有部分产品销售给国内从事电气设备制造等行业的客户。产品与日 本的同业者日本电气化学工业株式会社、新日铁 Micron 公司等产品已处于同一水平。公 司现有硅微粉产能 2 万吨,在建产能 3.9 万吨,新增产品产能囊括目前主要被日系厂商 垄断的品种,剑指我国硅微粉国产化先锋。

5.电子特气:在半导体制程中应用场景广,国产化空间大
5.1.电子特气在半导体制程中应用场景广阔
蚀刻、沉积、清洗是电子特气应用的核心制程。蚀刻工艺主要是有选择性地去除不需要 的材料,从而得到想要的图案纹路。蚀刻可分为干法蚀刻和湿法蚀刻,即用电子特气或 湿电子化学品与被腐蚀物质发生化学反应形成挥发性物质,主要利用了蚀刻材料分子中 的活性基团(如氟原子活性基);CVD 是一种薄膜沉积方式。即把一种或多种蒸汽源原子 或分子引入腔室中,在外部能量作用下发生化学反应,并在衬底表面形成所需要的薄膜; 清洗工艺主要是去除硅片上的粒子、金属污染物、有机物等杂质,从而减少集成电路在 制造过程中遭到尘粒、金属的污染形成短路。
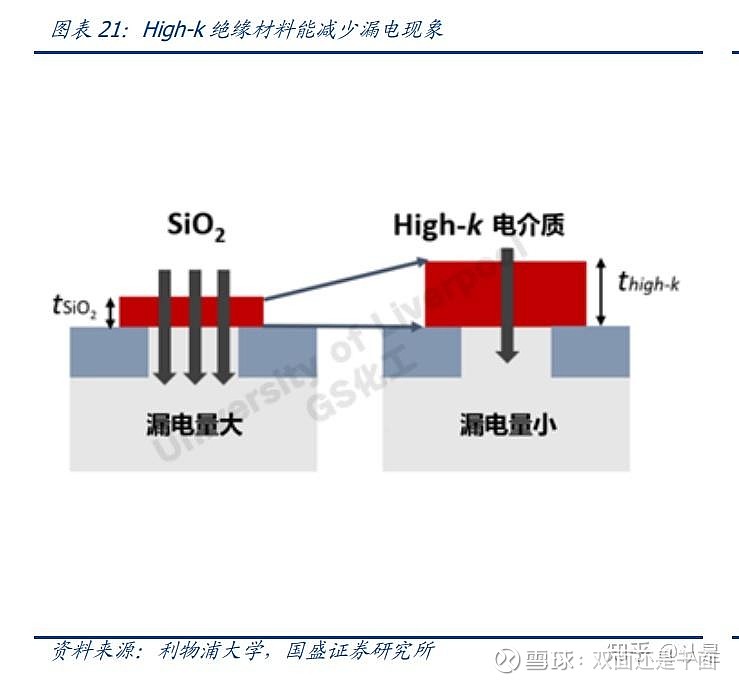
一个八寸的晶圆厂每年气体的使用金额约为 5000 万元。一方面,中国内资晶圆厂,例 如长江存储、合肥长鑫等均在扩产,产能的扩张将会带来更大的材料需求;另一方面, 制程升级提升气体用量,中国大陆经原产扩产带来更大的气体需求。无论是逻辑电路还 是存储电路,更先进的工艺都需要在晶圆制造过程中消耗更大量气体。含氟气体由于性 能稳定被广泛应用于电力设备制造领域及平板显示、光伏新能源和集成电路等半导体电 子产业的清洗、蚀刻、成膜、配线、离子注入等,是电子特气家族的重要成员。科美特 的核心产品六氟化硫、四氟化碳在一个典型的 8 寸晶圆厂年用量均超过 60 瓶。
电子特气主要被外企垄断,国产替代空间巨大。在全球及我国,电子气体市场被几大海 外巨头高度垄断。2018 年,林德集团、美国空气化工集团、法国液化空气集团、日本太 阳日酸株式会社占我国电子气体市场 88%份额。国内主要企业包括中巨芯、中船 718 所、 昊华黎明院、华特气体等。目前我国电子特气企业产品供应仍较为单一,但在政策扶持 及下游需求的拉动下,我国电子特气企业体量、产品品种迅速发展,国产替代已拉开序 幕。电子气体具有非常可观的市场空间,2021 年,全球四大气体工业巨头林德、法液空、 空气产品、大阳日酸均实现可观电子板块营收。
6.光刻胶:整合优质资产,卡位OLED光刻胶
光刻胶是图形化工艺的材料。光刻胶是利用光化学反应经光刻工艺将所需要的微细图形 从掩模版转移到待加工基片上的图形转移介质。在光刻工艺中,光刻胶被均匀涂布在硅 片、玻璃和金属等不同的衬底上,经曝光、显影和蚀刻等工序将掩膜版上的图形转移到 薄膜上,形成与掩膜版完全对应的几何图形。光刻胶按显示的效果,可分为正性光刻胶 和负性光刻胶,如果显影时未曝光部分溶解于显影液,形成的图形与掩膜版相反,称为 负性光刻胶;如果显影时曝光部分溶解于显影液,形成的图形与掩膜版相同,称为正性 光刻胶。
全球光刻胶市场规模 91.8 亿美元,面板光刻胶占近三分之一。光刻胶分为用于 LCD、 OLED 显示成像的面板光刻胶、用于半导体集成电路晶圆图形工艺的半导体用光刻胶、 以及用于 PCB 光成像的 PCB 光刻胶三大类。根据 Data Bridge,2021 年全球光刻胶市场 规模达 91.8 亿美元,其中我国光刻胶销售额占全球总量 14.6%。根据法国知名调研机 构 Reportlinke,2020 年全球光刻胶在面板显示的应用占比最大,约 28%,约占全球光 刻胶市场规模三分之一。
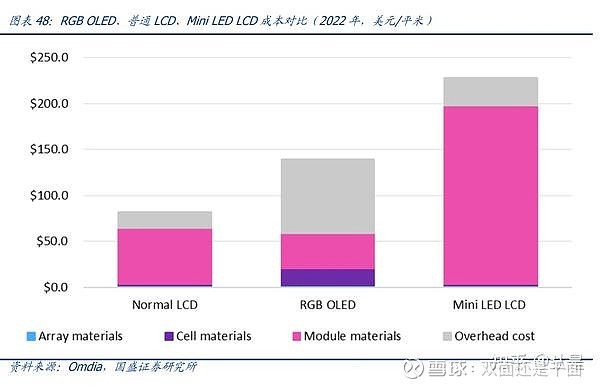
OLED 面板成本有持续下降空间,未来渗透潜力巨大。目前处于竞争的显示技术路线主 要包括 LCD、RGB OLED、Mini LED LCD、wOLED 等。从目前成本构成看,在 LCD、RGB OLED、Mini LED LCD 三种路线中,Mini LED 成本最为高昂,OLED 其次,普通 LCD 成 本最低。OLED 在过去成本持续下降,2016 年成本约 1100 美元/平米,我们预计随着单 位折旧成本的下行,有机发光材料等化学材料的持续国产化,2025 年 OLED 面板成本有望下降至 100 美元/平米以下。然而,LCD 的折旧占成本比重约 11%,且如背光模组、 偏光板等 LCD 主要原材料,目前国产化程度已经较高,后续成本下降空间有限。未来 RGB OLED 行业规模进一步增长、有机发光材料等关键原材料进一步国产化后,将有望具有 和普通 LCD 匹敌的成本优势。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
精选报告来源:【未来智库】