上周,Marvell召开了一场分析师见面会,主要谈的就是AI。Marvell高级副总裁兼投关总监牵头,邀请了公司董事会主席兼CEO以及四个部门( Cloud Optics、 Connectivity、Network Switching、 Products and Technology)负责人出来交流。
CEO和四个部门负责人共5人,每人都做了一场主题演讲,后面分析师提问。整场会议内容非常饱满丰富,信息量极大,笔者单看会议纪就花了整整一个上午三个小时时间。
说实话,一般的人哪怕是非常专业的人士,看下来也是很累的。为了更好地帮助读者了解到关键信息,笔者‘消化’之后highlight了一些关键点,希望帮助各位发现未来的投资机会。

先看一下2023年数据中心市场规模:
2023年数据中心的总资本支出约为2600亿美元。其中一些是在建筑和基础配套设施中。因此,硬件设备大约1970亿美元,其中半导体这块支出规模约为1200亿美元;
将1200亿美元进一步细分为核心半导体(不包括模拟和存储器),去年核心半导体数据中心支出约为820亿美元,也就是说模拟和存储这块大约380亿美元;
820亿美元进一步细分为 :计算半导体为最大的部分,为680亿美元;互联半导体40亿美元;交换半导体60亿美元;存储控制半导体40亿美元。
680亿的计算半导体部分:420亿美元为加速计算;260亿为通用控制计算。
以上是数据中心半导体现状分布。我们再来看看对未来的预测(2023-2028年5年预测):计算相关半导体从2023年的680亿美元增长至2028年的2020亿美元,年均复合增速为24%;其中加速计算半导体从2023年的420亿美元增长至2028年的1720亿美元,年复合增速为32%;(你可以理解为GPU、XPU这些)
其中定制加速计算ASIC在2023年约66亿美元,份额占比加速计算16%;
预计2028年定制加速计算ASIC份额达到25%,即429亿美元;
预计定制加速计算ASIC未来5年复合增长率为45%,比加速计算总体复合增速32%要高10个多点。
需要注意的是加速计算部分也仅25%为定制ASIC即XPU(博通和marvell等),75%的大部分依然还是英伟达和AMD的GPU。
其中通用控制计算半导体从2023年的260亿美元增长至2028年的300亿美元,年复合增速为4%(可以理解为CPU);
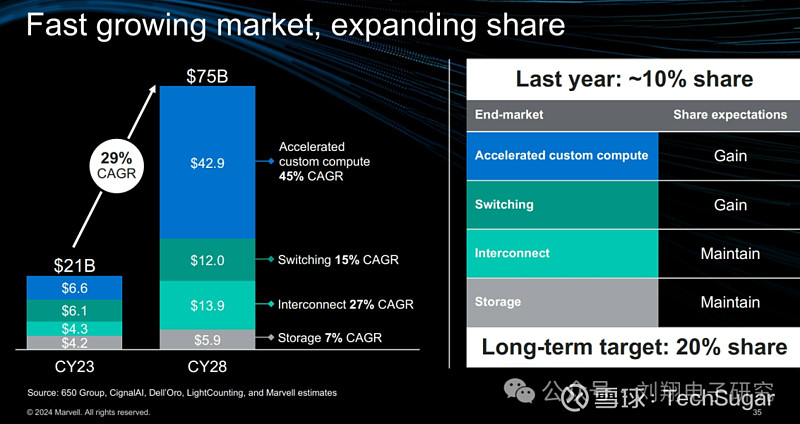
Marvell把其涉足的半导体部分(不包含GPU)按照结构分类,未来5年的复合增速总体情况如下图:
我们可以看到:
未来5年加速计算半导体的复合增速最快,达到45%;而且规模也最大,到2028年达到429亿美元;
未来5年互联半导体的年复合增速处于第二位,达到27%;规模在2028年达到139亿美元;
未来5年交换半导体的年复合增速为15%,2028年这块规模达到120亿美元;
未来5年的存储控制半导体年复合增速为7%,增速较低,不过比通用服务器CPU的4%还是要高一点。
从Marvell自身来看,他们的目标是把市场份额从2023年的10%增长到2028年的20%。为了达到这个目标,需要在互联和存储这块份额保持的条件下,扩大定制计算ASIC和交换芯片的市场份额。
互联是Marvell的核心技能,也是AI从起步发展到今天最大的变数。


因为AI的出现,互联迭代出现了加速趋势,包括速率和数量:过去4年互联速率翻一倍,现在已经出现每2年翻一倍,典型迭代加速;
AI训练是大集群,但是用量不多;未来AI推理会是小集群,但是数量会很多;
AI数据中心未来几年全球要投入2万亿美元,建6000个数据中心点。
短距离内是用铜,协议是NVlink、PCIe、InfiniBand,所以只要看到是NVlink那就是用铜缆链接的。如上图:
AI集群内部,即后端网络,采取infiniband或者超以太网协议,用铜缆或者光纤;
前端网络(看到CPU的地方)采用以太网协议,采用光纤方式传输
在AI训练方面的光模块数量发展趋势:
2023年GPT-3在1000个GPU集群上使用大约2,000个光互连进行了训练。
2024年GPT-4在2.5万个GPU集群上进行训练,GPU量扩大了25倍;同时需要大约75,000个光互连,光互连扩大了37倍
可以看到十万卡集群很快推出,需要五层交换,需要500,000个光互连
正在谈论的一百万卡集群,可能需要100万个光互连。

在连接技术方面,不同网络层次使用的技术不相同:数据中心内部,包括前端网路和后端网络,连接距离不超过2公里,采用PAM调制方式;数据中心之间,距离一般较长,几百公里甚至数千公里,使用相干调制;
光模块构成:DSP、TIA(跨阻放大器)、激光驱动器、激光发射器、激光检测器。其中Marvell做的是电相关的DSP、TIA、激光驱动器。
大模型不单需要大集群AI训练更需要花费数月时间,如果其中一个链接故障会影响整个训练崩溃;
DSP在这里面很关键,可以起到智能、诊断、遥测、系统级智能、检查链路的质量等功能;
TIA和激光驱动器,因为是高频模拟电路,所以要用锗硅BiCMOS工艺来生产;
包括传统数据和AI服务器,3到4米的距离内,还是使用铜,要么电路板要么用铜缆。
随着速率越来愈高,越来越多使用铜缆,之前很多都是被动铜;
随着数据中心密度增长,客户希望在机架中安装越来越多的互连器件,从而显著提高机架的面板密度,所以需要使用更细的铜缆;
但电缆越来越细,损耗也越来越大;所以这时候被动铜缆要变成主动铜缆,也就是有源铜缆;

互联半导体的全球市场在2028年达到111亿美元,年均复合增长率为27%。其中到2028年,数据中心间互联半导体市场规模达到30亿美元,年复合增长率为25%;数据中心内部采用有源电缆连接的半导体市场规模为10亿美元,年复合增长率59%;数据中心内部采用光纤方式的半导体市场规模为71亿美元,年复合增长率为25%。

对于光这块又可以分为传统光模块和硅光模块两种方式。


传统光模块和硅光模块的最大差别之处在于:DSP、Driver和TIA(跨阻放大器)差异不大;硅光模块使用硅光芯片把电光芯片做互相转化,而传统光模块在接收端采用光检测器来检测接受光信号。
硅光芯片是高速调制器、激光器、高速探测器等耦合而成;
硅光芯片可在8寸或12寸晶圆生产线上批量制造,因而成本可以做到很低;
传统光模块采用EML(电子吸收调制器激光器)发射器;而硅光模块采用CW(连续波)激光发射器;
在传统光模块中,如果速率达到200G就必须使用EML,1.6T方案使用EML会非常昂贵;
CW激光就像一个灯泡,发出恒定的光。更容易制造,供应商多并且成本低廉;
传统光模块是分立方案需要一大堆元器件:
使用EML激光器,每个1.6T的传统光模块需要8组200G的配置(每组包含激光器,光电探测器,一堆不同的零件)。
需要一个透镜将8组激光聚焦到光纤上。
还需要隔离器、电容、电阻等分立元件
硅光模块是集成方案,成本更低、可靠性更高,甚至可以采用3D方式:
共享激光器。4个通道共享一个激光器,因而只需要两个激光器即可实现1.6T模块,意味着更低的成本。同时更少的激光器、更高的集成度意味着更高的可靠性和更好的扩展性
3D硅光是高度集成的光学、硅光子电路。可以将32个200G通道集成在一起,做成6.4T硅光模块

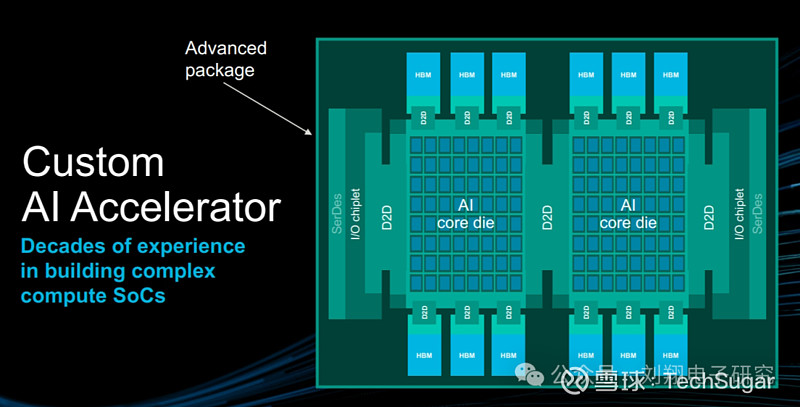
其实内容还很多,比如以下:




END