
日常生活中,我们常常从图文中获取知识。(比如,随手拍摄的PPT、笔记、书籍报刊,还有各种各样的手机截图)
拍下含有大量信息的照片之后,知识也只是停留在了手机里。
这时候,就需要进行信息提取、内容整理、知识获取等繁琐的工作。

那么有没有什么办法、可以更加高效地整理图文信息,提高知识获取的效率呢?
前段时间,我们发布了星火图文识别大模型,大模型的“眼睛”更厉害了。现在,用图文获取知识的效率已在「next level」。
图文识别大模型
能怎么帮我们获取信息?
说起图文识别,大家比较熟悉OCR。(全称:Optical Character Recognition 光学字符识别,比如扫描手写文件转成文字、接收图片之后提取图片上的文字等)
传统的OCR技术主是通过文本行检测与文本行识别的范式来完成图文识别任务,识别过程中并不会考虑文本行间的版面和语义关联性。
比如我们拍摄的PPT照片,PPT上的小标志、插图、表格、描述文字各种元素间杂排列,普通OCR技术提取文字可能把描述文字和图表中的文字混在一起分不清楚。
实际使用中,我们希望拍摄了一张PPT图片之后,系统能帮我们完整输出这张图上有哪些元素,精准识别所有描述性文字并整理成一段通顺的话,最好图表、流程图这些也能给出正确的解析和梳理呈现。
现在,大模型强大的语言理解能力,给传统OCR技术的这些问题带来了新的机遇。
星火图文识别大模型以讯飞星火大模型为基座,可以做到:
处理非常复杂的版面分析
结合篇章的语义和文字的理解能力进一步提升
覆盖更多专用领域的特殊的专业符号
总之,升级后的讯飞星火更懂图文识别的真实需求。
以下请看详细介绍——
31个场景18种版面
通通能够拿捏
目前,星火图文识别大模型覆盖31个常见的典型场景,(如:教育类书刊、学术论文、专利、海报、产品白皮书、PPT等),这些都来源于用户的实际需求。

图文识别覆盖的多种场景

精准识别学术论文对应内容
而实际生活中,图片识别还面临更多复杂的难题——
第一关:复杂的图片版面元素。
为了精准解析图片上复杂的版面元素,我们需要让模型能够表达各类要素的位置、内容、顺序、嵌套关系,并且能转换出各类的输出形式。
为此,讯飞研究院提出了改进版Markdown和精简版HTML两种序列表达方法,充分利用预训练语言特性,保证文本、公式、表格、编号、代码等核心内容的统一表达。
第二关:小字、模糊字、竖排文字、公式、表格的识别。
讯飞研究院提出动态分辨率和动态注意力采样的编码器架构,保障模型在各类复杂场景下的特征抽取能力;此外,还针对性研发了场景数据合成和增强系统,显著提升了模型在这些难例场景的识别率和鲁棒性。
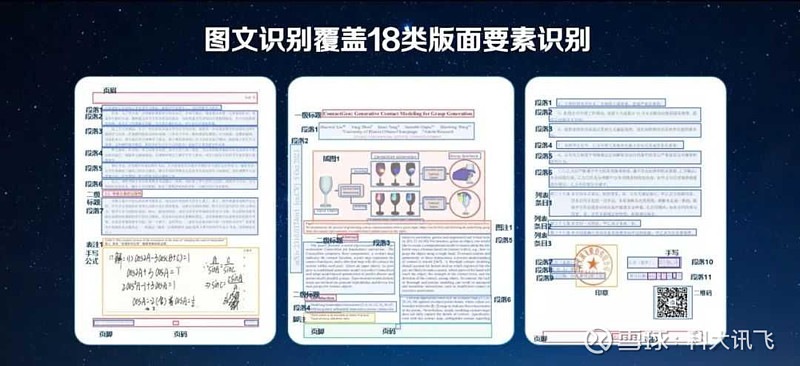
图文识别覆盖的多种版面要素
第三关:表格和插图附近的补充解释和说明文字。
虽然对于人类来说,说明性批注文字很好关联理解,图文识别模型却很容易“蒙圈”。
讯飞研究院通过精简版HTML序列表达方法和特有训练任务,让星火图文识别大模型不仅能给出图注表注的区域位置,还能分辨出这些内容属于哪个图表,以及对应的图表在哪个栏目下、哪个段落间。

论文版面中的表注、图注
星火大模型的底座能力,让图文识别大模型能够更好的关联文本行间的版面和语义关联性,通过端到端篇章级多任务建模,对整篇内容上下文理解,极大提升了模型难例字符上的识别效果,也使得模型能够按照阅读顺序完成对整张图像的格式化信息抽取。
图文识别的专业度
更强了
教育、金融、科研等专业领域中的图文,会出现大量领域专业符号。
星火图文识别大模型收集与合成了大量不同专业领域的数据,并且针对性设计了预训练任务,统一了各领域的专业符号表达方式,能够覆盖更多领域的专业符号识别,例如:
科研场景里各类复杂的公式
教育场景里的手写文字
拼音与文字组合
……
在科研、金融、产品文档等典型应用场景上,讯飞星火图文识别大模型的识别效果表现均超越了国内现有最优水平。
目前,讯飞星火图文识别大模型在权威英文文档信息抽取公开数据集FUNSD上取得识别率88.5%的好成绩,显著领先其他商用和开源模型。
此前,讯飞研究院屡次在国际图文识别相关的权威赛事和评测中收获头名,技术路径上已越过图文识别“千重山”。

有了星火图文识别大模型,我们就能针对图片直接提问想要的信息。
大模型会在识别、理解后帮你整理这些图片中的知识点,不仅让我们日常的知识学习和知识管理有了更便捷、更高效的处理方式,也为诸多专业领域带来了新的应用可能。
看到这里,你是否已经跃跃欲试了呢?
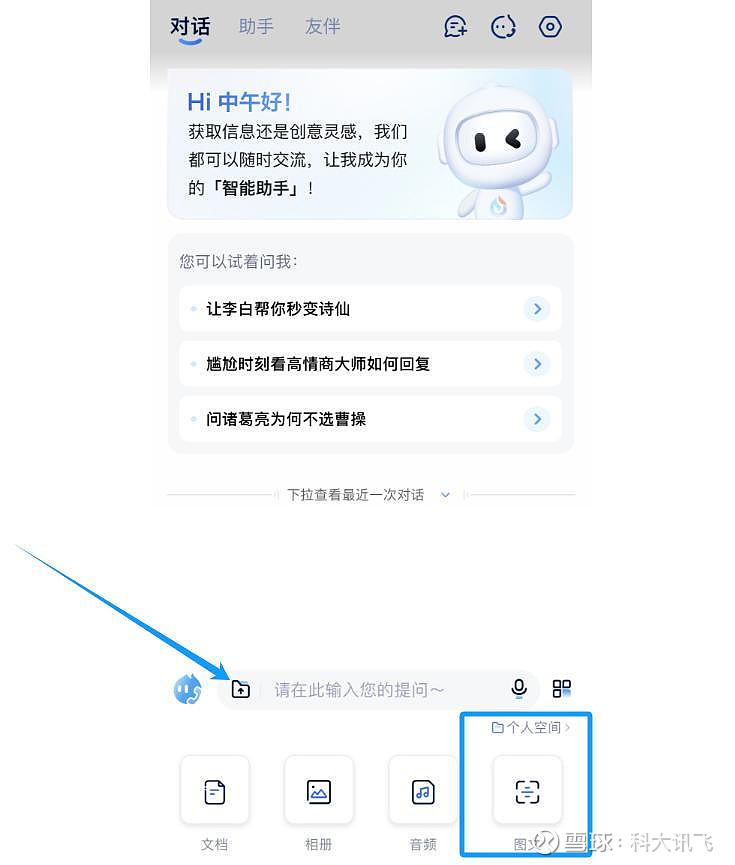
现在打开讯飞星火APP,选择文件夹中的“图文”,批量上传图片,就可以体验我们最新的图文识别功能了。