
作者 | 赵明华
近日,斯坦福、UCSD、UC 伯克利和 Meta 的研究人员提出了一种全新架构,用机器学习模型取代 RNN 的隐藏状态。
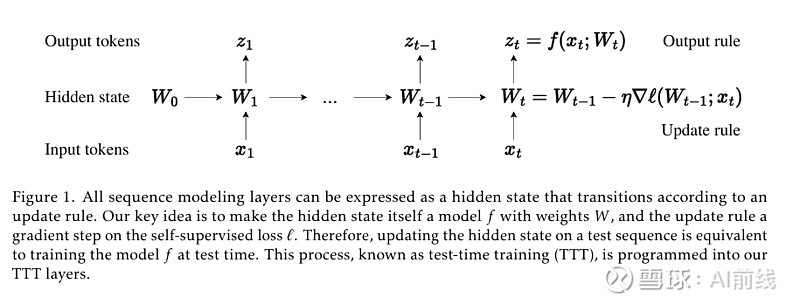
图 1 所有序列建模层都可以表示为一个根据更新规则转换的隐藏状态
这个模型通过对输入 token 进行梯度下降来压缩上下文,这种方法被称为「测试时间训练层(Test-Time-Training layers,TTT)」。该研究作者之一 Karan Dalal 表示,他相信这将根本性地改变语言模型方法。
自注意力机制在处理长上下文时表现良好,但其复杂度是二次的。现有的 RNN 层具有线性复杂度,但其在长上下文中的表现受限于其隐藏状态的表达能力。随着上下文长度的增加,成本也会越来越高。
作者提出了一种具有线性复杂度和表达能力强的隐藏状态的新型序列建模层。关键思路是让隐藏状态本身成为一个机器学习模型,并将更新规则设为自监督学习的一步。
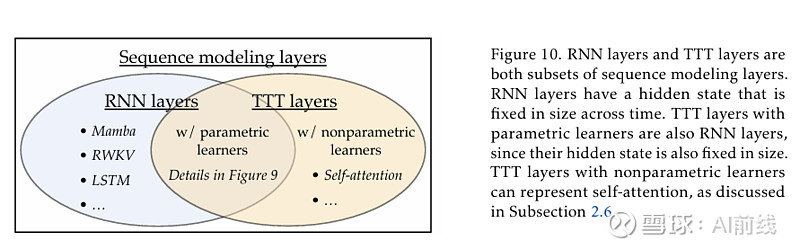
图 2,RNN 层与 TTT 层的关系
论文中提出了两种实例:TTT-Linear 和 TTT-MLP,它们的隐藏状态分别是线性模型和两层 MLP。团队在 125M 到 1.3B 参数规模上评估了实例,并与强大的 Transformer 和现代 RNN Mamba 进行了比较。结果显示,与 Mamba 相比,TTT-Linear 的困惑度更低,FLOP 更少(左),对长上下文的利用更好(右):
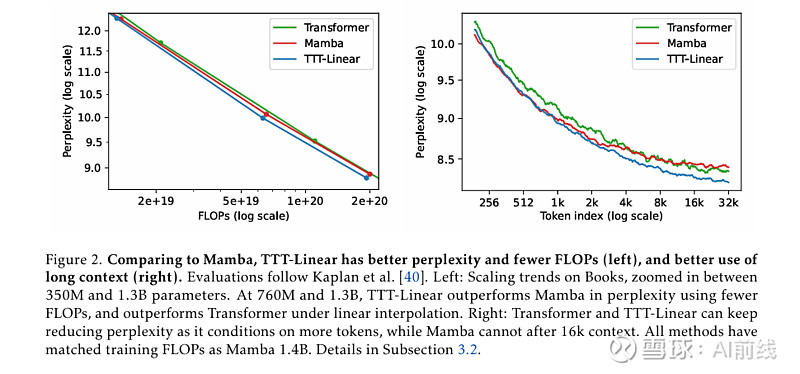
图 3 TTT-Linear 与 Mamba 对比
这个结果代表了现有 RNN 的尴尬现实。一方面,RNN(与 Transformer 相比)的主要优点是其线性(与二次型)复杂性。这种渐近优势只有在长上下文的实践中才能实现,根据下图,这个长度是 8k。另一方面,一旦上下文足够长,现有的 RNN(如 Mamba)就很难真正利用所依赖的额外信息。
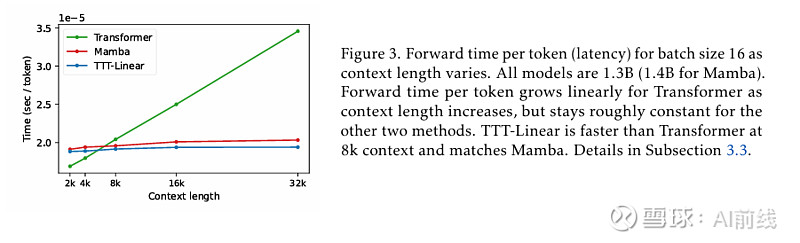
图 4 TT Linear 在 8k 环境下已经比 Transformer 更快
并且,大量的实验结果表明:TTT-Linear 和 TTT-MLP 都匹配或超过基线。与 Transformer 类似,它们可以通过限制更多的代币来不断减少困惑,而 Mamba 在 16k 上下文后则不能。经过初步的系统优化,TTT Linear 在 8k 环境下已经比 Transformer 更快,并且在 wall-clock 时间上与 Mamba 相匹配。
TTT 层在理论上和实验评估中表现出色,尤其是在长上下文处理和硬件效率方面。如果在实际应用中能够解决一些潜在的工程挑战,如大规模部署和集成问题,工业界对 TTT 层的接受度也将逐步提升。
论文链接:网页链接
内容推荐
AIGC技术正以惊人的速度重塑着创新的边界,InfoQ 首期《大模型领航者AIGC实践案例集锦》电子书,深度对话30位国内顶尖大模型专家,洞悉大模型技术前沿与未来趋势,精选10余个行业一线实践案例,全面展示大模型在多个垂直行业的应用成果,同时,揭秘全球热门大模型效果,为创业者、开发者提供决策支持和选型参考。关注「AI前线」,回复「领航者」免费获取电子书。
活动推荐
AICon 全球人工智能开发与应用大会,为资深工程师、产品经理、数据分析师等专业人群搭建深度交流平台。聚焦大模型训练与推理、AI Agent、RAG 技术、多模态等前沿议题,汇聚 AI 和大模型超全落地场景与最佳实践,期望帮助与会者在大模型时代把握先机,实现技术与业务的双重飞跃。
在主题演讲环节,我们已经邀请到了「蔚来创始人 李斌」,分享基于蔚来汽车 10 年来创新创业过程中的思考和实践,聚焦 SmartEV 和 AI 结合的关键问题和解决之道。大会火热报名中,7 月 31 日前可以享受 9 折优惠,单张门票节省 480 元(原价 4800 元),详情可联系票务经理 13269078023 咨询。
今日荐文
有赞取消 HRBP 岗位,员工拍手叫好!中国科技大厂的尴尬境地:既要富士康的效率,又要谷歌的创新
微软中国CTO韦青:亲身经历大模型落地的体会与思考
零就业保障、全天精神“酷刑”!ChatGPT类产品背后80%贡献者,时薪1.16美元,但也没得选
网易员工内部群怼丁磊:人人陪你演戏点赞;李彦宏:开源模型是智商税;小红书再裁员:人效比只能达到拼多多的一半 | AI周报
全员降薪60%、300亿市值几乎跌成零!这个曾剑指英伟达的国产芯片公司被曝造假,业内评其“老鼠屎”
你也「在看」吗?