整理 | 傅宇琪
只需轻轻一点,静态的皮卡丘就会露出灿烂笑容:


咖啡会源源不断地冒出热气:


漂亮姐姐会朝你眨眼:


以上这些效果,均来自一个新的图生视频模型 Follow-Your-Click,由腾讯混元、清华大学和香港科技大学联合推出。
这个模型使用起来也非常简单:
把任意一张照片输入模型点击想选中的区域加上少量简单的提示词(如:动作、神态等)图片中原本静态的区域就能动起来。
相关研究论文已经在 arXiv 上公开,GitHub 上也放出代码,目前已经揽星 440+。
论文链接:网页链接
代码链接:网页链接

哪里要动点哪里
通过进一步测试,可以发现 Follow-Your-Click 能够精准控制画面的动态区域。
点击画面主体,它就能够控制火箭发射和汽车行驶:


也能够生成“大笑”、“生气”、“震惊”的表情:



同样是鸟图,点击小鸟,输入“摇头”、“扇翅膀”、“跳舞”,都能得到相应更精确的动作:



总之,就是想要哪里动,就点哪里。
研究团队还将 Follow-Your-Click 和其他视频生成模型进行了同题对比,以下是实验效果:


那么,这是怎么做到的呢?
“一键点、万物动”如何实现?
当前的图生视频大模型中,一般的生成方法不仅需要用户在提示词中描述运动区域,还需要提供运动指令的详细描述,过程较为复杂。
另外,从生成的效果来看,现有图像生成视频技术在移动图像的指定部分上缺乏控制,生成的视频往往需要移动整个场景,而不是图像上的某一个区域,精准度和灵活性上有所欠缺。
Follow-Your-Click,尝试着解决这些问题。
在实现方式上,Follow-Your-Click 首先采纳了图像语义分割工具 Segment-Anything,将用户的点击操作转化为二进制区域 Mask,并将其作为网络运行的条件之一。
为了更有效地捕捉时间相关性并提升学习效果,团队引入了一种高效的首帧掩模策略。这一策略提高了模型生成视频的质量,而且有助于处理畸变和首帧重构。
为赋予模型更强的文字驱动能力,特别是在响应简短提示词方面,研究团队构建了一个名为WebVid-Motion 的数据集。该数据集通过大模型筛选和标注视频标题,着重强调人类情感、动作以及常见物体的运动,从而提升了模型对动词的响应和识别能力。
联合研究团队还打造了一个运动增强模块,这一模块不仅与数据集融合,更能够强化模型对运动相关词语的响应能力,使其理解并响应简短的提示指令。
为了实现对运动速度的准确学习,研究团队还提出了一种基于光流的运动幅度控制,使用光流模长作为新的视频运动幅度控制参数。
通过以上这些新提出的方法,加上各模块的组合,Follow-Your-Click 大大提升了可控图生视频的效率和可控性,最终实现了用简单文本指令来实现图像局部动画。
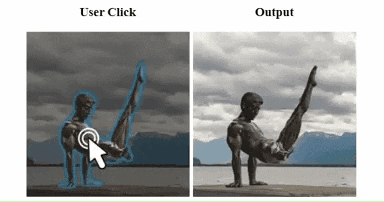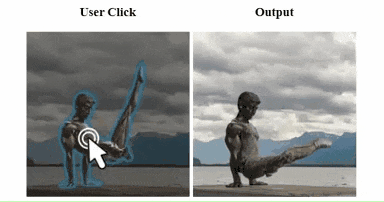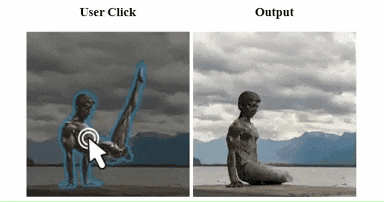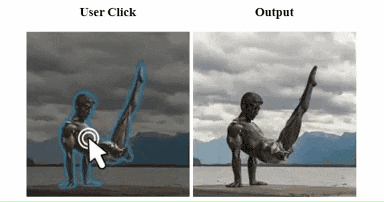
不过,由于动作的复杂性和相关训练样本的稀缺,目前,模型对于“生成大型复杂人体动作”仍然存在局限性:当想让保持体操动作的雕塑“休息休息”时,哥们放下的腿直接无痛“截肢”了。
Follow-Your-Click 联合项目组中的腾讯混元大模型团队,已经作为技术合作伙伴,支持了《人民日报》的原创视频《江山如此多娇》。
不得不说,2024 年的多模态领域是真卷啊……
参考链接:网页链接
内容推荐
InfoQ 独家邀请了潞晨科技创始人兼董事长尤洋,从技术原理、复现路径和实际应用成本考量三方面深入解读 Sora 技术和应用可行性。本次技术解读共包含Sora 的技术原理和关键组成、快速复现和集成 Sora 的指南、成本效益和实际应用考量三个核心要点,帮助大家理解 Sora 的核心技术、快速实现和集成 Sora 到自己的项目中,并提供考虑成本效益和实际应用的指导。关注「AI前线」,回复「Sora解读」获取解读视频及文字资料。
今日荐文
刚刚!马斯克履约开源Grok,超越Llama成全球最大开源模型,却被怀疑是作秀?!
零一万物刷榜遭怒怼:面向投资人编程;315锤AI诈骗:假老板骗走员工186万;知识星球屏蔽 ChatGPT、Sora| AI周报
身价7亿的周受资也没辙了?TikTok 弹窗1.7 亿用户强势反击,国会一分钟20个电话被打爆
苹果终于入局大模型了:300亿参数、MoE 架构,手机要迎来全面的大变革了?
OpenAI Sora发布时间定档,可能允许“裸体”内容出现
你也「在看」吗?