
作者 | Allyson Gale
译者 | Sambodhi
策划 | 钰莹
AI 前线导读: 在 Lyft,多个核心业务功能都引入了机器学习技术,包括路线算法、定价算法、司机匹配算法等,Lyft 计划在未来数月向业界开源这些人工智能算法的模拟器测试技术。在 Uber 最近发布了一款开源的人工智能调试工具 Manifold 后,Lyft 随即就发布了 Flyte。更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
日前,Lyft 宣布开源 Flyte,这是一个面向高并发、可扩展、可维护工作流的结构化编程和分布式处理平台。Flyte 已经在 Lyft 提供了三年多的生产模型训练和数据处理服务,成为团队事实上的平台,如定价、位置、预计到达时间(Estimated Time of Arrivals,ETA)、地图、自动驾驶(L5)等等。实际上,Flyte 在 Lyft 管理着超过 7000 个独特的工作流,每月执行总计超过 10 万次、100 万个任务和 1000 万个容器。在本文中,我们将介绍 Flyte,概述它解决的问题类型,并提供示例来说明如何利用它来满足你的机器学习和数据处理需求。
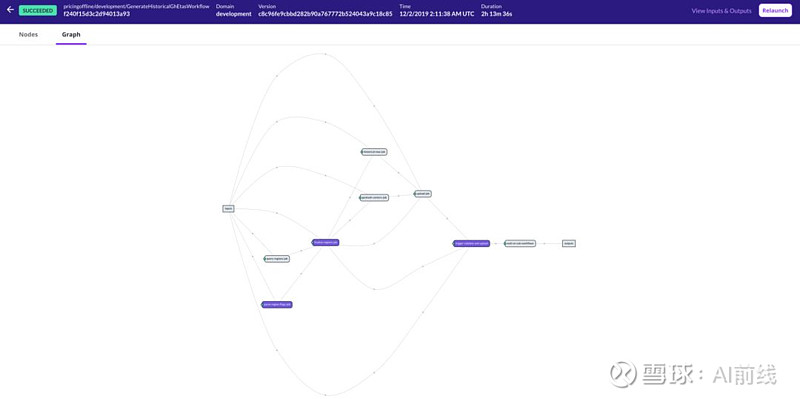
Lyft 众多定价工作流之一,在 Flyte UI 中以可视化方式显示
Flyte 解决的问题
由于现在数据已经成为公司的主要资产,执行大规模的计算作业对业务来说至关重要,但从运营角度来看是存在问题的。扩展、监视和管理计算集群成了每个产品团队的负担,由此拖慢了迭代,从而拖累了产品的创新。此外,这些工作流通常具有复杂的数据依赖关系。如果没有平台抽象的话,依赖管理将会变得难以维系,并使跨团队的协作和重用变得不可能。
Flyte 的任务是通过抽象这些开销来提高机器学习和数据处理的开发速度。我们通过可靠、可扩展、协调的计算解决了问题,使团队可以专注于业务逻辑而不是机器。此外,我们支持在租户之间共享和重用,因此,一个问题只需解决一次即可。随着数据和机器学习之间的的融合,包括从事这些工作的人员角色,这一点变得越来越重要。
为了让你更好地理解 Flyte 是如何让这一切变得简单,本文,我们将概述一些关键特性。
托管、多宿主和无服务器
有了 Flyte,你能从繁杂的基础设施中解脱出来,从而专注于业务问题而不是机器。作为一项多租户服务,你可以在自己的独立 Repo 中工作,并在不影响平台其余部分的情况下进行部署和扩展。你的代码已经版本化,使用其依赖项进行容器化,并且每次执行都是可重现的。
参数、数据沿袭和缓存
所有 Flyte 任务和工作流都具有强类型的输入和输出。这使得你可以将工作流进行参数化,拥有丰富的数据沿袭(data lineage),并使用预计算工件的缓存版本成为可能。例如,如果你正在进行超参数优化,那么你可以在每次运行时轻松调用不同的参数。此外,如果运行调用的任务是之前执行时已经计算过的,那么 Flyte 将会智能地使用缓存输出,从而达到既节省时间又节省金钱。
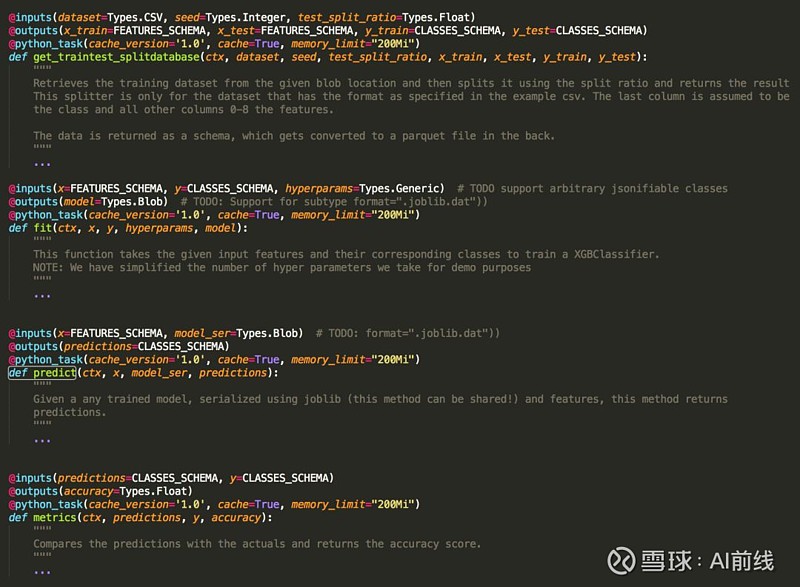
示例:使用 FlyteKit 声明任务
在上面的示例中,我们使用提供的数据集来训练 XGBoost 模型。机器学习管道使用 Python 构建,由以下四个任务组成,这四个任务与典型的机器学习过程相一致:
数据准备和测试验证拆分。
模型训练。
模型验证与评分。
计算指标。
数据集链接:网页链接
请注意,每个任务是如何参数化和强类型化的,这使得尝试不同的变体和与其他任务结合使用变得更加容易。此外,这些任务中的每一个都可以是任意复杂的。例如,对于大型数据集,Spark 更适合用于数据准备和验证。然而,模型训练可以在一个用 Python 编码的简单模型上完成。最后,请注意,我们是如何将任务标记为可缓存的,这可以极大地加快运行速度并节省成本。
下面,我们将这些任务组合起来创建一个工作流(或谓之“管道”)。工作流将任务链接在一起,并使用基于 Python 的领域特定语言(domain specific language,DSL)在任务之间传递数据。
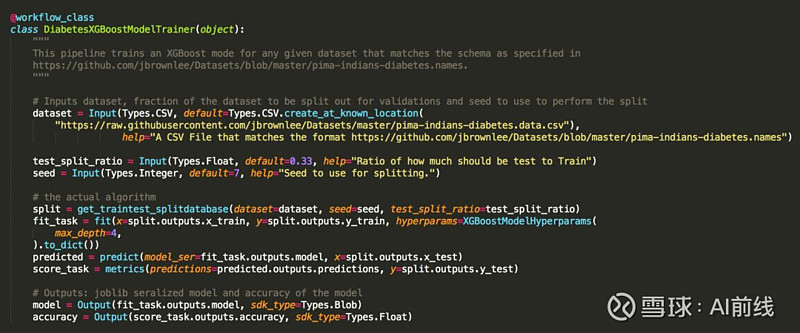
示例:在 FlyteKit 中声明工作流
译注: 数据沿袭(data lineage),根据维基百科的定义,它被定义为一个数据生命周期,包括数据的起源和随时间移动的位置。它描述了数据在经历不同过程时发生的情况。它有助于提供对分析管道的可见性,并简化对错误源的跟踪。
版本化、可复制性和可共享性
Flyte 中的每个实体都是不可变的,每个更改都显式地被捕获为一个新版本。这使得迭代、实验和回滚工作流变得简单高效。此外,Flyte 使你能够跨工作流共享这些版本化的任务,通过避免个人和团队之间的重复工作来加快开发周期。
可扩展性、模块化和灵活性
工作流通常由异构步骤组成。例如,一个步骤可能使用 Spark 来准备数据,而下一个步骤可能使用这些数据来训练深度学习模型。每个步骤都可以用不同的语言编写,并使用不同的框架。Flyte 通过将容器映像绑定到任务来支持异构性。
通过扩展,Flyte 任务可以是任意复杂的。它们可以是任何内容,从单个容器执行,到配置单元集群中的远程查询,再到分布式 Spark 执行。我们还认识到,该作业的最佳任务可能托管在其他地方,因此,可以利用任务可扩展性将单点解决方案与 Flyte 捆绑在一起,从而将其绑定到你的基础设施中。具体来说,我们有两种扩展任务的方法:
FlyteKit 扩展:允许贡献者提供与新服务或系统的快速集成。
后端插件:当需要对任务的执行语义进行细粒度控制时,Flyte 提供后端插件。这些可用于创建和管理 Kubernetes 资源,包括 Spark-on-k8s 之类的 CRD,或者 Amazon Sagemaker、Qubole、BigQuery 等任何远程系统。
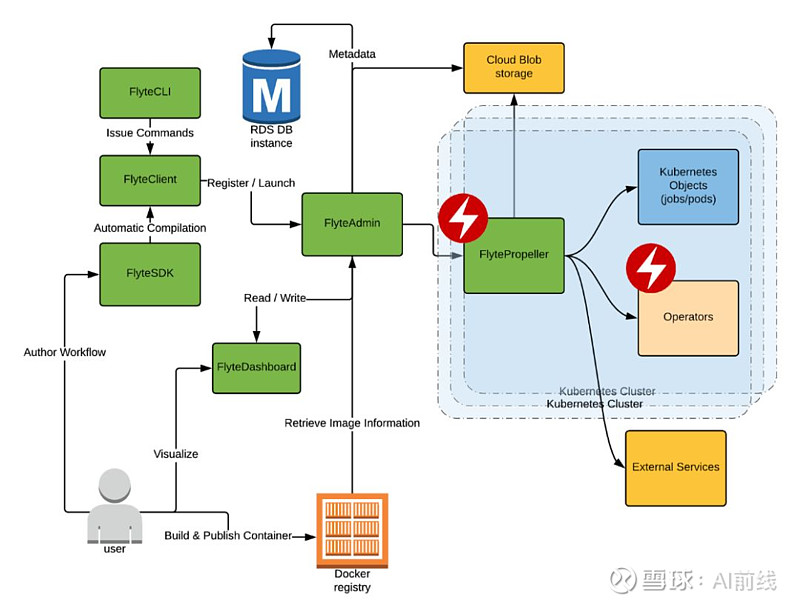
Flyte 架构的高级概述
结语
Flyte 的构建是为了在现代产品、公司和应用程序所需的规模上支持并加速机器学习和数据编排。Lyft 和 Flyte 共同发展,一起目睹现代处理平台所提供的巨大优势。
GitHub 地址:网页链接
作者简介:
Allyson Gale,Lyft 产品经理。曾在 Google Search 和 Android 部门工作。对道德和决策充满好奇。
原文链接:
你也「在看」吗?