
近日流传一份OpenAI工程师作息时间,有一项是背诵强化学习之父、加拿大计算机科学家理查德·萨顿Richard S. Sutton经典文章《The Bitter Lesson》。
文章指出过去70年来,AI研究走过最大弯路,就是过于重视人类既有经验与知识,他认为最大解决之道是摒弃人类在特定领域知识、利用大规模算力方法,从而获得最终胜利。
这一观点被OpenAI首席科学家Ilya Sutskever认同,并总结为算力常胜。从这个角度结合GPT模型发布时间线看,萨顿思想给了很大精神支持,从而使得堆算力路线得以持续坚持,为后来明确提出大模型的Scaling Law奠定基础。
Scaling Law与LLM is compressors的关键认知,成为OpenAI破局关键指导,Sora也是Scaling Law胜利。
2023年12月26日,科技博主Dwarkesh Patel发布文章《Will scaling work?》,深度分析Scaling Law能否继续有效,Scaling Law是否是带领我们通向AGI的终极钥匙。
本期长期主义,选择Richard S. Sutton经典文章《The Bitter Lesson》、Dwarkesh Patel文章《Will scaling work?》,AI工程化、海外独角兽发布,六合商业研选精校,分享给大家,Enjoy!

OpenAI工程师必背经典:苦涩的教训The Bitter Lesson
时间:2024年2月21日
来源:AI工程化
字数:1,969
《苦涩的教训》
Rich Sutton
2019年3月13日
70年来AI研究,给我们最深刻教训是:能够发挥算力的通用方法,终将大获成功。背后根本原因是摩尔定律Moore’s law,也就是计算单位成本持续指数型下降这一现象的普遍规律。
绝大多数AI研究都是在这样一种假设下进行:智能体可使用的计算资源是不变的,在这种情况下,发挥人类知识将是提升性能的主要手段。随时间推移,超出一般科研项目周期后,庞大的计算资源终将成为现实。
研究人员希望短期内依靠人类领域知识取得突破,长远看,真正重要的是算力的发挥。这两种方法不必是对立的,实践中它们往往相悖。
在一个上的投入,意味着牺牲另一个。人们对某种方法的投入,往往有着心理上的坚持。基于人类知识的方法,通常会使程序复杂化,不能很好利用发挥算力的通用方法。
有许多AI研究者,在项目后期才痛苦吸取到这一课,在这里回顾几个最突出的例子,我们将能获得宝贵的启示。
计算机国际象棋领域
1997年,战胜世界冠军卡斯帕罗夫的方法,依靠的是深度而广泛的搜索策略。
当时,大部分致力发挥人类对象棋独特结构理解的研究者,对此感到失望。
当一种更简单、基于搜索的方法,结合专门的硬件与软件,得到证实极为有效时,这些基于人类知识的象棋研究者们没有好好接受失败。
他们称这次暴力搜索可能赢了,并非普遍有效的策略,这并不是人类下棋的方式。这些研究人员期待基于人类直觉方法能取胜,结果感到失望。
计算机围棋领域
计算机围棋的研究进展出现相似模式,落后计算机国际象棋研究20年。
最初,研究者投入巨大努力来避免通过搜索解决问题,试图利用人类对围棋特殊性质的认识,所有这些努力一旦在大规模搜索得到有效应用后,显得无关紧要,甚至是错误的。
自我对弈的学习策略,对学习价值函数也极为关键,这在很多其他游戏与国际象棋中也很重要,尽管在1997年第一次击败世界冠军的程序中学习的角色不大。
无论是自我对弈的学习,还是一般意义上的学习,都类似搜索,能够利用巨量的计算资源。AI研究中,搜索与学习,是利用海量计算资源的两种最关键技术类别。无论在计算机围棋还是计算机国际象棋,研究的初衷,都是减少搜索需求,希望通过人类认知来达到目的,只有在很多年之后,通过接受搜索与学习,才获得巨大成功。
语音识别领域
语音识别领域,20世纪70年代有一场由DARPA赞助的早期竞赛。
参与者呈现多种特殊方法,这些方法利用对词汇、音素、人声道等方面的人类知识。
对立面是采用更多基于统计的方法,这些方法执行更多计算,基础是隐马尔可夫模型HMMs,统计方法再次胜出。
引发自然语言处理领域重大转变,数10年来,统计与计算力逐渐占据主导地位。
深度学习在语音识别中的崛起,是沿这一方向迈出的最新步伐。
深度学习方法更少依赖人类知识,利用大量计算资源,并且通过在巨量训练数据集上进行学习,大幅提升语音识别系统性能。
像在游戏领域一样,研究人员总是试图打造出与他们心中想象的思维方式相匹配的系统,他们尝试将这种认知融入系统中,最终证明适得其反。当摩尔定律Moore’s law,使得大量计算成为可能,并找到有效利用这些计算资源的方法时,它反而成为研究者时间的巨大浪费。
计算机视觉领域
计算机视觉领域,也出现类似模式。
早期方法将视觉处理想象为寻找边界、泛化的圆柱体,或者基于SIFT特征的过程,现在这些做法都被淘汰。
现代深度学习神经网络采用卷积,以及特定种类的不变性这些概念,取得更好的成绩。
重要教训
作为一个领域,我们还未完全领悟这些,我们还在重复同样错误。
为了理解这些错误吸引力,并有效克服它们,我们需要学习的是:长远看,试图构建与我们自以为的思维方式相符的系统,行不通。
这个苦涩教训,来自这样一些历史观察:AI研究者经常尝试将知识植入他们智能体;这在短期内似乎总是有益,并能给研究者带来满意感;长期看,这种方法迟早会遇到发展瓶颈,甚至阻碍进一步进展;真正突破性进展,最终是通过与此相反的方法实现,这一方法依赖通过搜索与学习来扩展计算能力。
最终的成功带着苦涩,往往难以被完全接受,它推翻受到人们偏爱的以人为中心的方法。
苦涩教训中,我们应该明白,通用方法具有巨大力量,即使是在可用的计算能力变得极其巨大的情况下,这些方法依然可以继续拓展与升级。能够如此无限扩展的两种方法,是搜索与学习。
苦涩教训中,我们应该吸取第二个要点是,心智的真实内容,极其复杂与深邃;我们应当停止寻找简单化理解心智内容的方法,比如简单的空间感、物体、多智能体交互或对称性等。
这些都是外在世界任意复杂性的一部分,它们的复杂性是无穷的,我们不应该将它们内置于系统中;相反,我们应该只构建能够发现,并捕捉这些任意复杂性的元方法。
这些方法的核心,在于它们能找到良好的近似,发现它们的过程,应该依赖我们的方法,而不是我们个人。
我们希望创建的AI智能体,能像我们一样进行发现,而不是仅包含我们所发现的内容。将我们发现,内置于系统中,只会使得理解发现过程本身变得更加困难。
Scaling能通往AGI吗
时间:2024年2月21日
来源:海外独角兽
字数:6,819
几乎所有关于LLM讨论都无法跳开Scaling Law,它被看作OpenAI最核心的技术,Sora的出现也被认为是Scaling Law又一次成功。
关于Scaling还能继续有效的讨论也在展开,如果以实现AGI作为目标,它会是带领我们通向AGI的终极钥匙吗?
科技博主Dwarkesh Patel个人博客这篇文章,首先对现阶段社区围绕Scaling Law的争议与讨论的关键问题进行梳理,并对支持或质疑Scaling Law声音进行解读分析。
Dwarkesh预计,有70%左右概率,人们能够通过Scaling,在2024年之前实现更强的AI,这种AI能够实现大量认知劳动的自动化,进而促进AI进一步发展。如果Scaling Law失效,实现AGI过程会非常漫长与艰难。
为更全面呈现关于Scaling Law的不同态度,文章将以积极观点与消极观点辩论的形式呈现。
讨论1:现有数据会被用光吗
消极观点:2024年,高质量语言数据将会用尽。
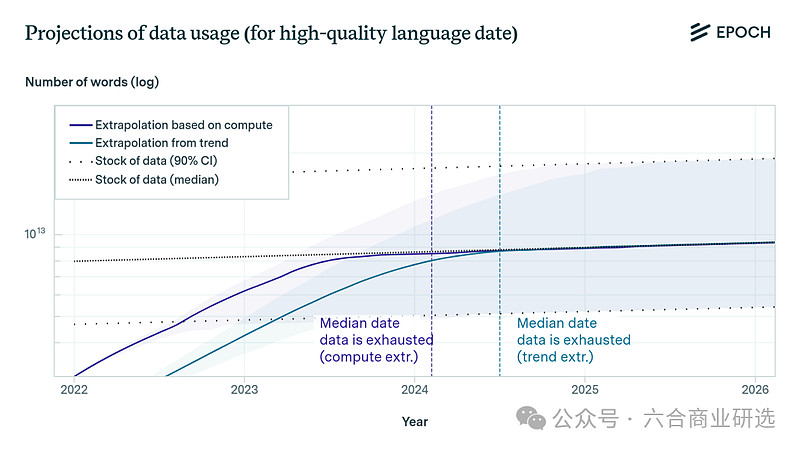
根据Scaling Law曲线,我们需要大概1e35次浮点运算FLOPs才能训练出一个聪明到能写论文的AI,在这个基础上再进一步自动化AI研究,并且在以后Scaling Law不起作用时还能继续迭代下去。
换句话说,我们需要的数据比现有的数据还要多出5个数量级。
根据Chinchilla Optimal Scaling原则,我们可以用非最优方式训练模型,这只能弥补较少的数据不足,而不是5个数量级的短缺。
Chinchilla Optimal Scaling来自DeepMind研究,简单说是为了高效Scaling,需要同时增加训练数据量与模型参数量,并找到二者平衡点,只关注任何一个,都会限制模型的性能提升。
需要注意的是,5个数量级并不是5倍,少5个数量级,意味着现有数据可能只有我们真正需要的10万分之一。
我们可以通过一些方法来提高数据利用效率,比如多模态训练、循环利用同一数据集token recycling、课程学习curriculum learning等,依然很难满足Scaling Law指数式增长的数据需求。
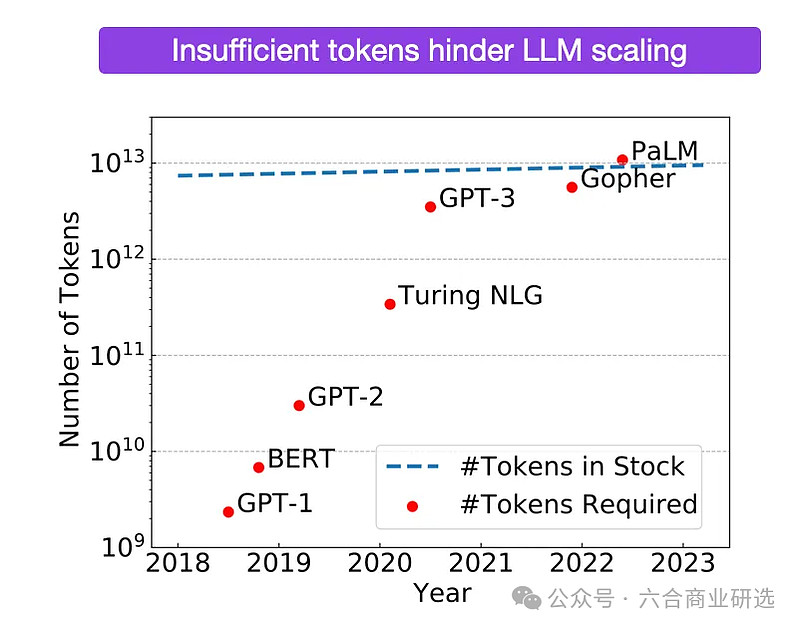
不同模型所需Token数量对比
有人提出可以用self-play与合成数据synthetic data方法,但self-play面临下面两大难题:
评估:AlphaGo之所以可以用self-play方法训练,是在围棋这个场景下,模型能够基于是否赢得比赛来做自我评估,现在很多推理任务并没有这样明确标准,LLM也无法修正自己的推理错误。
计算:在AlphaGo与类似的数学或编程方法中,常常会用到各种树状搜索tree search技术,在树的每个节点多次运行LLM。
在围棋这样范围相对确定的任务里,AlphaGo计算量已很大,要想搜索所有人类思考过程的可能性,还得处理更多数据与更复杂的参数,计算量只会更加庞大。
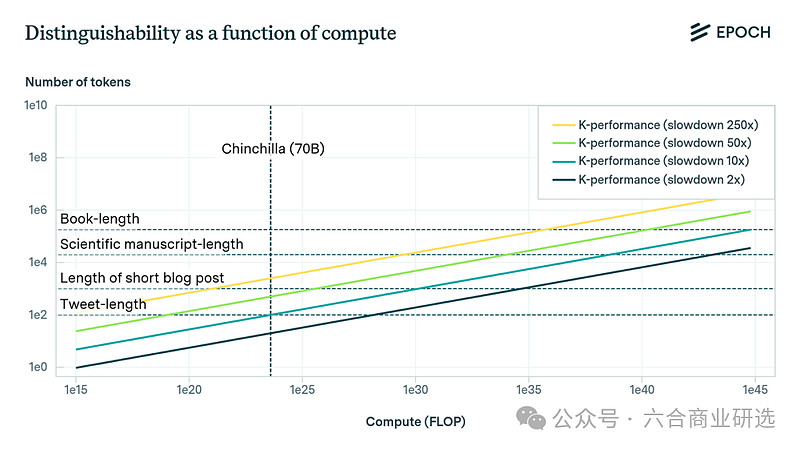
与人类思维水平相当的计算量,大概是1e35 FLOP,也就是要在当前最大模型基础上,额外增加9个数量级的计算能力。
就算未来我们能通过硬件与算法进一步优化,9个数量级的提升,真的可能吗?
蒙特卡洛树搜索MCTS
积极观点:如果只是数据短缺这个原因,质疑Scaling Law可行性,不应该有我本来也觉得继续做transformer模型Scaling就能实现AGI,问题是数据很快就会用完这样的想法,相反,应该去想原来只要互联网数据足够充足,继续Scaling下去就能训练出有人类智能水平的AI。
LLM在处理数据时效率并不高,训练用的数据样本,大多是广告这种低质量文本e-commerce junk*,而预测下一个token的训练方式会让模型变得更加低效。
如果用损失函数来评估,这与我们期待智能Agent在经济活动中实际执行的工作完全无关。但我们还是用这种方法,花了等同于微软年收0.03%的投资从互联网上抓取大量数据,并且训练出了一个初级AGI,也就是GPT-4。
与人类相比,LLM样本效率的确比较低,GPT-4所处理的数据量远超过一个人从出生到成年所见到的数据,却远不如人类聪明。
这个判断没有考虑到一点:人类基因中包含亿万年进化过程中累积的知识,可以看作是被高度浓缩过的精华信息,是人类祖先通过与环境互动,并在长时间内进行自然选择的结果。这种遗传知识,为我们提供了一种在出生时就携带、对世界的基本理解,这是LLM所不具备的。
既然AI至今的进化方法这么简单,如果以后合成数据也能起作用的话,我们也不用惊讶,毕竟the models just want to learn.原话引用自Dwarkesh对网页链接{Anthropic CEO Dario Amodei的采访},Dario提到这是OpenAI创立前,Ilya最初对Dario说过的话,并且给了他很多启发。
GPT-4发布8个月后,其他AI labs才陆续推出与GPT-4能力齐平的模型,也就是说研究人员现在才开始让这代模型做self-play。总结来讲,目前没有公开证据显示合成数据在大规模应用中有效,并不意味着它就发挥不了作用。
一旦foundation model能偶尔给出正确答案,强化学习就会更加可行。模型完成任务的成功率,会慢慢从1%提升到10%,再到90%,这时就可以尝试更复杂任务,比如1,000行pull request请求。模型不仅成功率会更高,还能在失败时自我纠正,模型性能就会在这样循环过程中得到提升。
回顾人类进化过程,会发现与现在模型利用合成数据来自我强化非常相似。起初,我们祖先很难迅速领悟与使用新知,自从人类发展出语言后,出现基因与文化的共同进化,这与LLM的合成数据与self-play循环非常相似。模型也是在相似过程中变得更加智能,更好理解相似模型的复杂符号输出。
Self-play并不需要模型在自我评判逻辑推理时做到完美,只要比模型从零开始推理做得更好就可以,这也是目前我们看到的现实。
这点可以参考Constitutional AI,或者自己试试GPT,就会发现它更擅长分析用户哪里写得不对,而非自己独立得出正确答案。
如果评估者也是GPT-4这种性能有限的模型,self-play循环可能会更加有效。在GAN中,如果鉴别器Discriminator远比生成器Generator强大,它就会停止向生成器提供任何反馈,它无法给出不完美但具有正确方向的信号。
换句话说,如果鉴别器与生成器的能力相差太远,就会阻碍学习过程。鉴别器需要足够的能力来识别生成的数据,同时不能强大到完全没有失败的空间,否则它就无法给生成器正确的学习信号来引导优化。
我接触过几乎所有AI研究员都对self-play很有信心,但因为保密原因,他们不能透露具体细节,只提过有很多可尝试的方向。
就像我网页链接{采访Anthropic CEO Dario Amodei}时他说的:各种原因我不方便讲太深,但世界上有丰富的数据来源,生成数据的方法也很多,我个人认为这不会成为阻碍。如果数据真的成为障碍反而会更好,但实际上并不会。
消极观点:Constitutional AI、RLHF与其他基于RL与self-play既能发掘模型潜能,也能在必要时约束模型,但目前还没人能证明通过RL能真正提高模型的底层能力。
如果self-play或合成数据的方法不起作用,我们就很难突破数据瓶颈。寄希望于新架构不切实际,新架构需大幅提升样本效率,而且这个提升要比LSTM到Transformer的跨越还大得多,LSTM出现至今已20年,好攻克的问题早已解决,要想继续取得突破很困难。
LLM的支持者与利益相关方都对模型Scaling评价很积极,这并不能改变客观事实,我们确实没有证据表明RL能够解决数据量级不足的问题。
LLM在极为庞大的数据量训练下,推理水平一般,表明模型不具备泛化能力。如果模型无法利用人类2万年所积累的数据量,达到接近人类水平的性能表现,即使有20亿年数据量也不够,就像无论你给飞机加多少喷气燃料,也不能让它上月球一样。
讨论2:Scaling Law真的起过作用吗
积极观点:各种基准测试中,模型性能已稳步提升8个数量级。即便在计算资源增加百万倍情况下,模型性能的损失,仍然可以精确到小数点后多位。
GPT-4技术报告指出,他们能够通过较小实验模型上预测最终GPT-4模型的性能,训练方法与GPT-4相似,计算能力远少于GPT-4,可能只有万分之一。
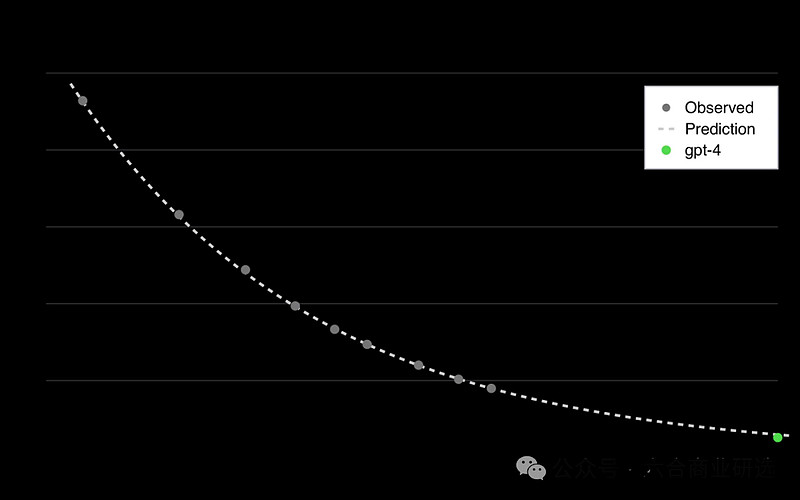
GPT-4性能预测
LLM在过去8个数量级的性能提升都非常稳定,这个趋势会持续。通过接下来8个数量级的Scaling,以及算法与硬件进步带来的性能提升,我们很可能会得到性能更为强大的模型来加速AI研究。
消极观点:我们不关心模型在预测下个Token的任务上表现如何,模型在这方面已超过人类,我们关心的是在这个任务上的Scaling Law曲线,是否能说明模型的泛化能力已有实质提升。
积极观点:随着模型不断Scaling,MMLU、BIG-bench与HumanEval等基准测试都表明模型在各类任务上的性能都有明显提升。
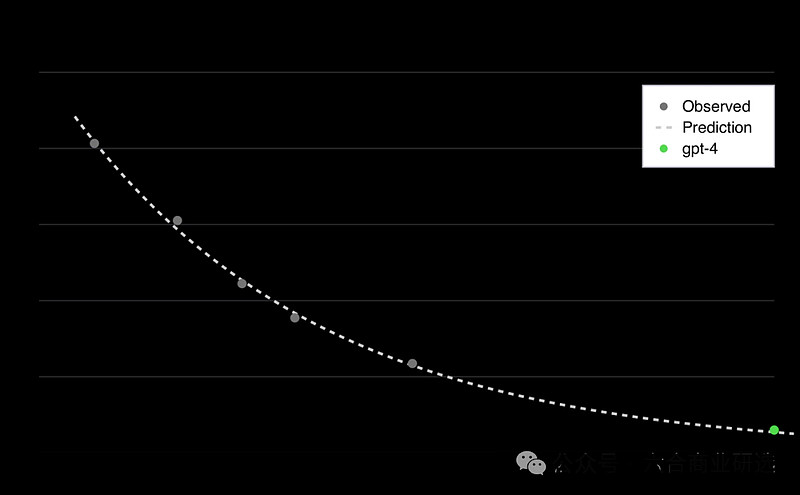
HumanEval基准测试
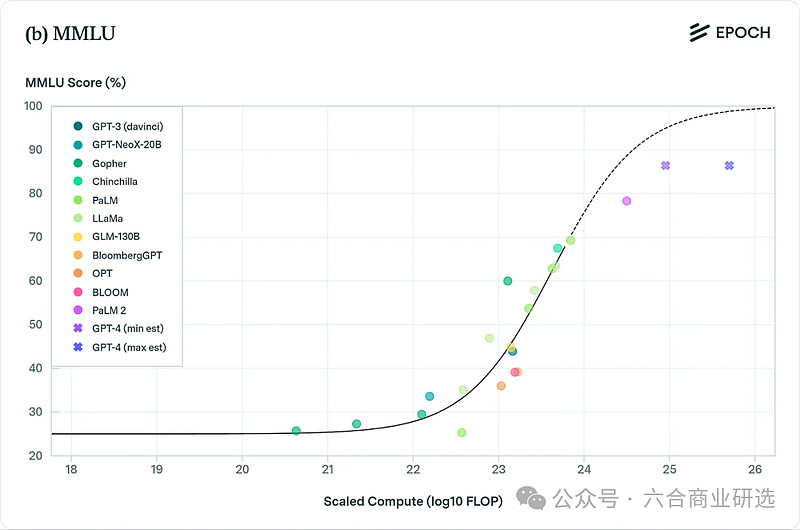
MMLU基准测试
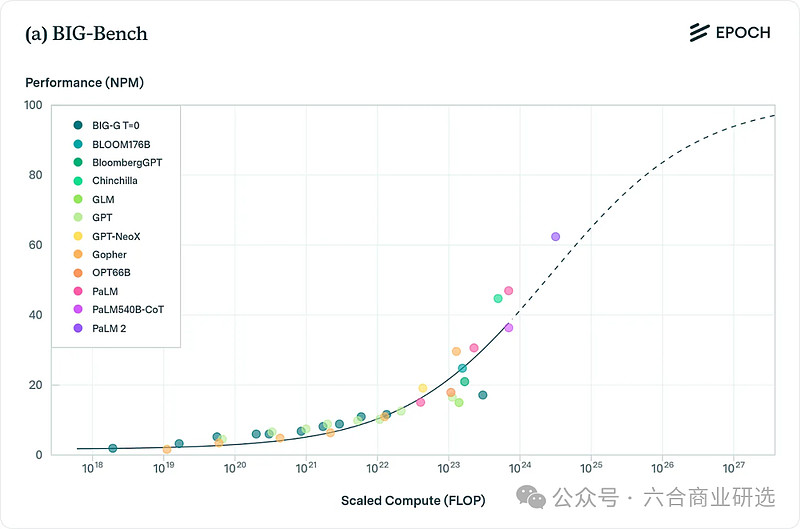
BIG-Bench基准测试
消极观点:只要你随便看几个MMLU与BigBench测试样本,就会发现几乎全是谷歌搜一下就能查到的结果,这种问题更像是在测试模型记忆力,而非智能程度。
以下是一些我从MMLU随机挑选出来的问题,原题都是选择题,模型只需从四个选项中选出正确答案:
Q:根据Baier理论,判断一个行为是否道德上可接受的第二步是什么?
A:确定禁止这种行为的道德规则,是否是真正的道德规则。
Q:哪一项总是适用于自发过程spontaneous process?
A:系统加环境的总熵entropy增加。
Q:克林顿出生时的美国总统是谁?
A:杜鲁门。
网络上本来就有各种各样的文本与随机事实,指一些脱离特定上下文、独立存在的信息碎片或数据点,模型基于这些数据训练,记住了再返回给人类,这能说明模型有智能与创造力吗?
在这些人为制定的基准测试中,模型性能提升已显示出瓶颈。尽管Google的Gemini Ultra模型的计算能力比GPT-4高出近5倍,但在标准基准测试如MMLU、BIG-bench等上的表现几乎与GPT-4相当。
现有的基准测试,通常不衡量模型在长期任务上的性能表现,比如能不能在1个月内里完成一项任务。模型是基于下一个Token预测训练,在长期任务上几乎没有有效的数据点进行学习。
SWE-bench测试显示,衡量LLM是否能够自主完成pull request的测试,模型在处理长时间跨度的复杂信息时表现不佳。GPT-4的得分只有1.7%,Claude 2表现稍好,达到4.8%。
目前主要有两种基准测试:
一种是评估模型的记忆、召回与插值能力interpolation的测试,包括MMLU、BIG-bench与HumanEval。
这些测试中,模型展现出了与人类平均水平相当、甚至更高的性能表现,这并不能作为智能程度的准确衡量标准,当前模型在智力方面远不如人类。
另一种是真正考察模型在长期任务执行或处理复杂概念上能力的测试,包括SWE-bench与ARC,模型在这类测试中表现并不出色。
当一个模型经过相当于人类2万年输入的数据量训练,仍然无法理解Tom母亲是Mary,Mary儿子就是Tom这种简单的逻辑关系,给出的回答还极度依赖问题的表述方式与顺序时,我们该如何评价这个模型?
我觉得没必要讨论Scaling未来是不是有效,Scaling至今有没有起过作用都存疑。
积极观点:有些人认为Gemini Ultra性能到了平台期,这是很不合理的。
GPT出现前,有一部分人对连接主义Connectionism与深度学习提出过质疑,GPT-4的出现打破这种观点。现在Gemini性能相对GPT-4有限,主要是谷歌在算法提升上还赶不上OpenAI。
连接主义Connectionism是认知科学中一个理论框架,它假设心智功能可以由大量简单的计算单元,通常指神经元之间的相互连接与交互来解释,在心理学、AI、机器学习与认知神经科学等领域都有应用。
连接主义模型通常是通过神经网络,无论是生物学的还是人工的来实现,它们模拟大脑中神经元之间复杂的网络结构。在AI中,连接主义的概念,已演化为现代深度学习技术,多层神经网络已成为解决复杂问题,如图像识别、自然语言处理等的强大工具。
如果深度学习与LLM真的有底层局限性,在它开始具备常识与抽象思维能力之前就能看出来,不需要等到现在。
GPT-4相比GPT-3性能有巨大提升,这是通过100倍scaleup实现。
100倍看起来很多,未来模型可能会扩大到一万倍,也就是GPT-6的水平,到这个水平所需的资金还不到世界GDP的1%。
这还没算上其他可能提升性能的因素,比如提高预训练的计算效率(MoE、flash attention技术等)、新的训练方法(RLAI、对思维链进行fine tuning、self-play等),还有硬件进步,这些都能让性能有很大提升很多。
这样算下来,我们可能只需要花全球GDP的1%,就能造出GPT-8级别的模型。
我们可以回顾一下历史上每次新技术出现时,政府的投资力度:
1847年,英国铁路投资的GDP占比高达7%,达到历史峰值。
1996年美国《电信法》实施,接下来5年内,美国电信公司总投资超过5,000亿美元,相当于当下一万亿美元,主要用于铺设光纤电缆,增设新交换机与建设无线网络。
我不懂为什么大家认为GPT-8可能比GPT-4强不了多少,按发展趋势说,GPT-8性能应该是GPT-4的1亿倍,模型即使在远小于这个规模的Scaling中,也已学会了如何思考与理解世界。
我预想未来的情景是这样,会有几百万个GPT-8一起工作,它们会一起改进核心代码,找到更好的超参数,给模型的fine tuning提供很多高质量的反馈。开发GPT-9的经济与技术成本将大幅降低,如果这个趋势持续下去,我们有希望到达奇点。
讨论3:模型真的能理解世界吗
积极观点:为了预测下一个Token,LLM必须学习万物背后的规律,理解Token之间联系。比如说模型得先明白进化论,才能推理《自私的基因The Selfish Gene》中某段接下来的内容;在短篇小说中,要先理解人物心理活动,才能猜出故事后面情节。
有个有趣的点是,通过大量代码学习,可以提高LLM语言推理能力,这说明模型能从代码中提炼出一些通用的思考模式。这不仅意味着语言与代码间有相似的逻辑结构,意味着无监督学习能够发现并利用这种结构,从而提升LLM推理能力。
梯度下降Gradient descent的目标,是找到最能压缩数据的方法。最高效的压缩方法,也是最能深入理解数据的方法。比如,如果你能把一本物理书的压缩compression做得很好,你就能预测书中没涉及部分可能是怎样的,这是因为你已深刻理解了基本的科学原理。
消极观点:智能包括但不限于压缩,压缩并不等同于智能。我们都知道爱因斯坦很聪明,他提出相对论,并不意味着爱因斯坦加上相对论,就构成更为智能的系统。也不能因为柏拉图不懂现代生物学或物理学,就说他智力不及拥有这些知识的我。
智能=压缩这个说法不够准确,信息压缩不能等于爱因斯坦的创造性与深刻洞察力,随机梯度下降SGD是在光滑的损失函数中渐进总结出语义规律,爱因斯坦是在一片错误的排列与变体中,找到相对论正确方程的差异。对Scaling Law持消极观点的人,认为没有任何理由相信SGD能够通过压缩变得像爱因斯坦那样聪明。
如果LLM仅仅是由另一个过程SGD产生的压缩结果,我们将无从判断LLM本身具备的压缩能力,更无从判断LLM智能水平。
积极观点:我们目前并不需要一个完美的理论,来证明Scaling会持续有效。回顾历史,我们会发现蒸汽机出来一百多年,我们才完全理解热力学。技术进步,往往是先有发明,才有理论的完善。对智能技术发展,我们也应该有这样预期。
没有哪个物理定律,能保证摩尔定律一直有效。随技术不断发展,我们总会遇到新难题,这不意味着摩尔定律失效。未来,台积电、英特尔、AMD这些大公司的研发团队,会找到新办法来解决这些问题,让Scaling Law在接下来几10年持续发挥作用。
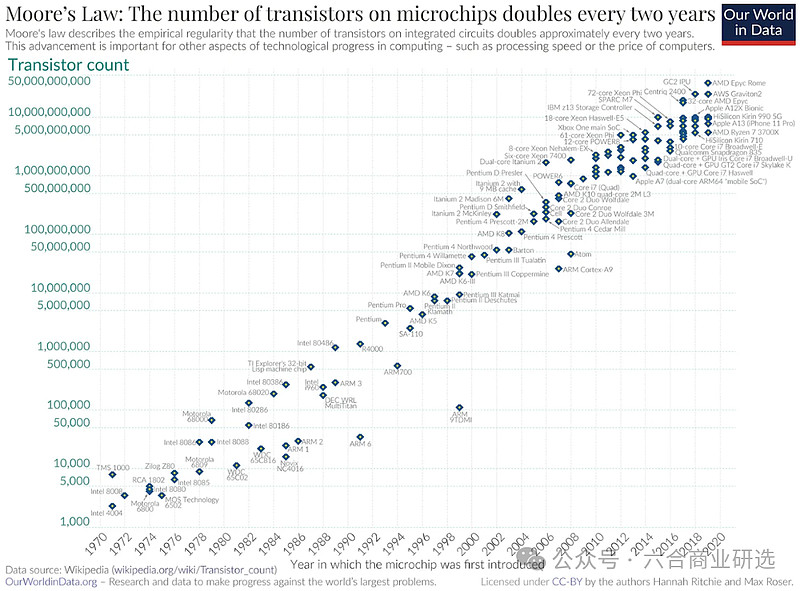
摩尔定律的延续
结论
我谈下个人看法。对于之前一直相信Scaling Law的人来说,至今为止,AI的发展看起来会合理得多。GPT-4之所以性能这么优越,是在训练中用了习语库idiom library或者查找表lookup table,但这种工具很难通用,上面的消极观点并没有提到这种可能性。
像Ilya、Dario、Gwern这样信仰Scaling Law的人,早在12年前就预见了我们近期看到的AI实现飞跃。
可以确定的是,适当的Scaling,确实能够让我们创造出一种革命性的AI,也就是说如果达到曲线上最小不可约损耗,指在最优模型训练完成后仍然存在的误差,就能训练出一个智能AI来完成大多数认知工作,包括辅助进行更高智能水平AI的迭代。
现实生活里事情,往往比书本上理论要复杂得多,有些理论上看起来可行的事情,比如核聚变、飞行汽车、纳米技术,实际上却很难实现。
同样道理,如果用self-play或者合成数据的方法来提高模型性能不可行,模型可能就没法再优化,也达不到理论上最低损失点。
现在支持Scaling持续有效的理论依据还不明确,有基准测试显示Scaling能提升模型性能,但这些测试本身标准存在争议。
总的来说,我初步判断会有两种情况:
第一种:继续Scaling、改进算法与硬件技术,我们能在2040年之前实现AGI,这个可能性是70%。
第二种:我们现在研究的LLM与类似技术都行不通,未来会遇到很难突破的瓶颈,这个可能性是30%。
需要说明的是,出于保密原因,AI labs通常不会公开研究成果,可能有些关于AGI的重要信息我并不知道。根据我在AI labs工作的朋友说的,目前公开发表的信息价值不高,上述判断可能会不太准确。
附录
下面还有一些我思考过的问题,我还不确定下面这些问题对于Scaling来说意味着什么。
模型能否实现领悟式学习?
积极观点:在不断Scaling后,模型自然会发展出更高效的元学习meta-learning方法,类似人类学习与领悟知识grokking的能力。,
这种领悟通常发生在模型过度参数化,并出现数据严重过拟合时。这跟我们人类学习新东西有点像,我们会用直觉与已有知识框架来理解新信息,随着观察不断增加,我们知识框架也会不断更新。在处理一大堆不同数据时,模型会找到那些最通用、最能举一反三的方法。这样,它们就能像人类一样,通过这种领悟来学习,最终达到深入理解。
消极观点:神经网络的确具备某种程度的领悟能力,但它们学习新知识的方式跟人类比起来差远了。
比如说,如果你告诉一个小孩,太阳是太阳系中心,他马上就能理解晚上看到的星星是怎么回事。
如果你给一个没有学过天文学的模型输入哥白尼理论,它不会立刻就能用这个新知识去理解相关事情。模型需要在很多不同情况下反复学习,才能慢慢领悟这些基本的概念。
目前为止,我们还没有让模型实现领悟式的学习insight-based learning。我们现在用的是梯度下降这种简单的优化方法,我甚至怀疑模型是不是真的能学习。
我们一次次喂给模型数据,让模型一步步逼近最优点。要让模型实现这种学习能力,就像是要求它从平地直接跳到珠穆朗玛峰山顶,这种飞跃式的提升,我们现在还做不到。
灵长类动物的进化,是否为Scaling提供依据?
黑猩猩智力上,可能有很多比所谓的逆转诅咒reversal curse更严重的问题,这并不意味着灵长类动物大脑有什么根本性缺陷,或者说他们不能通过增加大脑容量与finetuning来解决这些问题。
Suzana Herculano-Houzel研究显示,人类大脑里神经元的数量,与把灵长类动物的大脑按比例放大后的神经元数量差不多。但啮齿类与食虫目动物就完全不同,这些动物即使大脑体积较大,神经元数量也要少得多。
这表明,与其他物种的大脑相比,灵长类的神经架构在某种程度上具有更好的可扩展性,这与Transformer在扩展性上优于LSTM与RNN情况类似。
在灵长类动物生活的世界里,智力的一点点提升,就能大大增强它们生存竞争能力。这是因为智力能让它们更好理解通过观察、尝试与相互交流学到的信息,这样就能更有效提高它们生存技能。