AI全球视野 苹果发布了DCLM-7B 开源模型
建信新兴市场基金(539002 )AI 全球重要新闻总结
1. #据美国科技媒体The Information7月18日报道,随着Meta在人工智能上的支出增加,公司高管们对Reality Labs部门的限制越来越多。这个部门主要开发AR/VR产品,曾承载了扎克伯格的“元宇宙梦”。一位前部门经理表示,Reality Labs的硬件团队被要求在今明两年内削减近20%的开支,其中大部分削减将在今年进行。Meta首席财务官则告诉员工,鉴于公司已经做出的巨大投资,Meta应该将AR/VR定位为一个万亿美元的机会。Meta对该部门的巨额投资也尚未转化为预期成果。自2019年以来,Meta在Reality Labs上的累计亏损已超过550亿美元,年度亏损从2019年的45亿美元飙升至2023年的161亿美元。另外,在过去一年内,该部门经历了几轮裁员重组,主要针对中高层管理人员。据多位参与该项目的人士透露,Meta公司正在开发一系列新的Quest头显和AR眼镜,计划在未来三年发布。这些包括计划于明年发布的第一款增强现实眼镜。2026年,Meta公司计划发布Quest 4 VR头显,代号为Pismo Low和Pismo High。Meta还计划在2027年发布一款高端Quest头显,代号为La Jolla,目标是与苹果的Vision Pro竞争。然而,Meta在Reality Labs上的累计亏损不断增加,公司对部门的质疑声四起。随着AI大热,Meta开始节制对Reality Labs部门的开支,并不断精简团队成员。Meta于2022年底开始大规模裁员,最终削减了Meta约20%的员工。Reality Labs部门的裁员显得格外突出。在过去的一年里,该部门经历了几轮裁员,其中大部分计划旨在削减中高层管理人员。今年6月底,Meta在Reality Labs裁减了十几名高层管理人员,包括AR眼镜硬件的前负责人Caitlin Kalinowski和智能眼镜硬件的前负责人Steve McClure。#人工智能# $建信新兴市场(F539002)$ $建信新兴市场混合(QDII)C(F018147)$ $建信纳斯达克100指数(QDII)人民币C(F012752)$ @雪球基金
2. #奥特曼向7万亿美元打造芯片帝国的梦想又迈进了一步,据悉,OpenAI正与博通等芯片设计公司洽谈开发新款AI芯片的事宜。花旗认为,继Google、Meta和字节跳动之后,OpenAI将成为博通的第四大ASIC(定制芯片)客户,预计博通将在2025年下半年之后向OpenAI交付。目前,通用算力卡的主要厂商是英伟达,占AI算力市场近70%的份额;ASIC的主要厂商是博通和Marvell,两家占ASIC市场超60%的份额。ASIC是牺牲通用性,来换取特定场景的高性能;通用算力卡则具备通用性,但在特定场景下,性能不如ASIC。云厂商也许更看重弹性计算,企业也许更关注集群算力等。面对特定的需求,ASIC比标准算力卡更具备优势,更加贴合客户自身的使用场景。目前,Google、Meta、微软和亚马逊等云和超大规模公司正在引领ASIC这一潮流。比如,谷歌的TPU、Meta的MTIA、微软的Maia、亚马逊Trainium2等。
博通管理层预计,未来3-5年,公司每年AI业务的潜在市场将达到300亿美元至500亿美元之间,而公司2024财年的目标才110亿美元。博通的主要业务聚焦于大型消费AI平台客户(Google、Meta、ByteDance等)所需的ASIC芯片。管理层认为,这些大型消费AI客户在未来3-5年,将不会减缓投资xPU集群,规模将从今年的10万集群到100万集群。博通强调,最重要的是,在达到这个规模之前没有需求放缓的迹象。
3. # Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。Mistral NeMo由Mistral AI和英伟达联手打造,有12B参数,支持128K上下文。从整体性能上来看,Mistral NeMo在多项基准测试中,击败了Gemma 2 9B和Llama 3 8B。几天前,Mistral才发布了两款小模型,专为数学推理和科学发现设计的Mathstral 7B和代码模型Codestral Mamba,是首批采用Mamba 2架构的开源模型之一。最新发布的小模型Mistral NeMo 12B,瞄准企业用户的使用。开发人员可以轻松定制和部署支持聊天机器人、多语言任务、编码和摘要的企业应用程序。通过将Mistral AI在训练数据方面的专业知识,与英伟达优化的硬件和软件生态系统相结合,「最强爹妈」培养出的娃,Mistral NeMo模型性能极其优秀。Mistral NeMo在NVIDIA DGX Cloud AI平台完成了训练,该平台提供对最新英伟达架构的专用和可扩展访问。加速大语言模型推理性能的NVIDIA TensorRT-LLM,以及构建自定义生成AI模型的NVIDIA NeMo开发平台也用于推进和优化新模型的性能。此次合作也凸显了英伟达对支持模型构建器生态系统的承诺。Mistral NeMo支持128K上下文,能够更加连贯、准确地处理广泛且复杂的信息,确保输出与上下文相关。与同等参数规模模型相比,它的推理、世界知识和编码准确性都处于领先地位。由于Mistral NeMo使用标准架构,因此兼容性强,易于使用,并且可以直接替代任何使用Mistral 7B的系统。Mistral NeMo是一个拥有120亿参数的模型,根据Apache 2.0许可证发布,任何人皆可下载使用。此外,模型使用FP8数据格式进行模型推理,这可以减少内存大小并加快部署速度,而不会降低准确性。这意味着,模型可以流畅丝滑地学习任务,并更有效地处理不同的场景,使其成为企业的理想选择。这种格式可以在任何地方轻松部署,各种应用程序都能灵活使用。因此,模型可以在几分钟内,部署到任何地方,免去等待和设备限制的烦恼。Mistral NeMo瞄准企业用户的使用,采用属于NVIDIA AI Enterprise一部分的企业级软件,具有专用功能分支、严格的验证流程以及企业级安全性的支持。开放模型许可证也允许企业将Mistral NeMo无缝集成到商业应用程序中。Mistral NeMo NIM专为安装在单个NVIDIA L40S、NVIDIA GeForce RTX 4090或NVIDIA RTX 4500 GPU的内存上而设计,高效率低成本,并且保障安全性和隐私性。
4. #最近, 苹果公司 作为 DataComp-LM(DCLM)项目的研究机构之一,在 Hugging Face 上发布了 DCLM-7B 开源模型。该模型性能已经超越了 Mistral-7B,并且正在逼近其他领先的开源模型,包括 Llama 3 和 Gemma。苹果机器学习团队 Vaishaal Shankar 将 DCLM 模型描述为真正开源的最佳模型,因为 DCLM 不仅开源了模型权重,还开源了训练代码和预训练数据集。大型语言模型(LLM)目前面临的一个评估挑战是缺乏受控比较。LLM 研究通常会比较采用不同架构、计算或超参数的模型,因此难以理清影响语言模型质量的因素。基于此,研究团队提出了语言模型数据比较新基准 ——DCLM,这是语言模型训练数据整编(curation)的第一个基准,旨在让 LLM 通过设计高质量数据集来提高模型性能,特别是在多模态领域。研究团队发现基于模型的过滤,即由机器学习 (ML) 模型从较大的数据集中自动过滤和选择高质量数据,可能是构建高质量训练集的关键。DCLM 整体思路很简单:使用一个标准化的框架来进行实验,包括固定的模型架构、训练代码、超参数和评估,最终找出哪种数据整理策略最适合训练出高性能的模型。使用 DCLM,研究团队构建了一个高质量数据集 DCLM-BASELINE,并用该数据集从头开始训练了一个 7B 参数模型 —— DCLM-7B。DCLM-7B 使用基于 OpenLM 框架的预训练方案,在 MMLU 基准上 5-shot 准确率达到 64%,可与 Mistral-7B-v0.3(63%)和 Llama 3 8B(66%)相媲美,并且在 53 个自然语言理解任务上的平均表现也可与 Mistral-7B-v0.3、Llama 3 8B 相媲美,而所需计算量仅为 Llama 3 8B 的 1/6。值得注意的是,大部分其他模型虽然开放权重但封闭数据。这就是 Vaishaal Shankar 将 DCLM 模型描述为真正开源的原因。
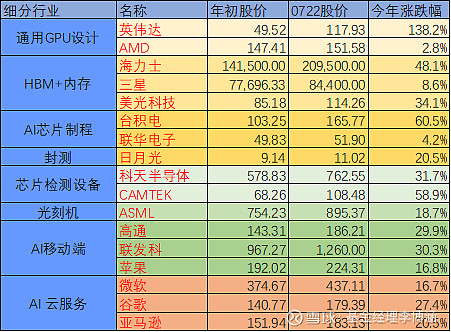
数据来源:万得,截至日期2024年7月22日
风险提示:部分个股讯息仅供参考,不作为任何投资建议或收益暗示。投资人应当认真阅读《基金合同》、《招募说明书》等基金法律文件,了解基金的风险收益特征,并根据自身的投资目的、投资期限、投资经验、资产状况等判断基金是否和投资人的风险承受能力相适应。基金的过往业绩并不预示其未来表现,基金管理人管理的其他基金的业绩并不构成基金业绩表现的保证。基金有风险,投资需谨慎。