

“目前,可能全世界只有几百人能亲身感受到正在发生什么,其中大多数人都在旧金山的各个AI实验室中。”
他们到底看到了什么?
最近出了件大事,13个OpenAI和DeepMind的前员工和现员工,共同签署了一份公开信,公开预警人工智能会带来的风险,并要求美国的各类人工智能公司建立“举报人保护措施”,保证研究人员具有警告人工智能危险的“权利”,而不必担心遭到报复。
其中,大部分离职的OpenAI员工是实名签署,而还在职的OpenAI员工则选择了匿名签署。

值得注意的是,在公开信的署名栏,还有三位在AI领域极具影响力的巨头,以实名签署的方式背书支持,这三人分别是:被誉为“人工智能教父”的杰弗里·辛顿(Geoffrey Hinton);因开创性AI研究获得图灵奖的约书亚·本吉奥(Yoshua Bengio);以及人工智能教科书撰写者、教授斯图尔特·罗素(Stuart Russell)。
这些曾一手开创AI研发先河的元老级人物,现在开始旗帜鲜明地预警AI风险。
图1. 公开信落款署名

有位OpenAI的匿名员工提到,目前最大的问题,就是全世界根本没有真正的意识到,人工智能已经发展到什么程度了。“目前全世界真正了解这个情况的,最多几百个人,而且,这些人基本都在旧金山的各大人工智能实验室里。”拥有这些实验室的,就是那几家最顶尖的人工智能公司,他们掌握着大量内部信息,但他们只会向政府透露极为有限的信息,更没有义务向民间披露。
这几百名了解实际情况的核心研发人员,即使有着极强的社会责任感,也囿于和公司签署的保密协议而无法发声,另外他们更担心自己发声后,因为触碰了巨大的商业利益,而遭受威胁。
他们未必是杞人忧天,OpenAI前员工利奥波德·阿申布伦纳(Leopold Aschenbrenner),本人也是超级对齐团队的成员,该部门的两位联合负责人伊利亚·苏茨克维(Ilya Sutskever)和简·雷克(Jan Leike)均于近期离职,目前部门已被解散。
图2. OpenAl前安全研究员利奥波德·阿申布伦纳

利奥波德透露了他被开除的真实原因。他给几位董事会成员分享了一份OpenAI安全备忘录,结果导致了OpenAI管理层不满。利奥波德在社交平台表示,“深度学习没有遇到瓶颈,人类在2027年,就能实现AGI。而在2030年左右,AGI很有可能会发展出全面超越人类的超级人工智能,但是人类似乎还没有做好准备。”
在这样的背景之下,才有了这封署名公开信中提到的诉求。
“AI可能会加剧贫富差距,操纵和传播误导信息”,公开信中还警告说,“可能因为对自主AI系统的失控,最终威胁到人类生存。”
利奥波德给OpenAI董事会分享的那份OpenAI安全备忘录,是此次事件的导火索之一。备忘录中到底写了什么?
我们找到了利奥波德撰写的一份165页的文件《态势感知——下一个10年》(Situational Awareness——the Decade Ahead),文件中,他汇总了自己在Open AI中了解到的信息,而这份文件,与安全备忘录中的大部分内容重合。本期【泉果探照灯】,将介绍文件中的核心观点。
*态势感知,是一个术语,也是一个学科,专门研究环境中的要素对决策的影响,主要应用于复杂和动态的领域,比如航空、航海、军事、警务等。
图3. 《态势感知——下一个10年》文件封面

如果您希望获得全部文件,请关注泉果视点公众号,并在后台留言【AI安全备忘录】,后台会把这份文件的完整版发送给您。

他们到底看到了什么?
利奥波德在文件中主要披露了以下几个观点:
【1】到2030年,我们会拥有难以想象的强大人工智能系统。
■ 它们在数量上超越人类
在拥有数亿个 GPU 设备的情况下,人类将能够运行数十亿个人工智能系统——它们的思考速度将比人类快上数个数量级,能够跨学科迅速掌握任何领域的知识,编写数万亿行代码,阅读所有有史以来撰写的每一篇科学领域的研究论文,这意味着,人工智能能在几周的时间里,获得相当于数十亿人类的所有创新经验。
■ 思考质量也将超越人类
人工智能将会产生超越人类理解的全新创意——这种差距就如同:人类还是抓耳挠腮学习牛顿定律的高中生,而AI已经在探索量子力学。
【2】这种爆炸性进展将会拓展到诸多领域:
■人工智能能力的爆炸式增长:实现所有认知工作的自动化;
■解决机器人问题:超级智能将突破纯认知。工厂将从由人类管理,逐步过渡为在人指导下的AI劳动,最终完全由机器人操作;
■ 大幅加快科技进步:十亿个超级智能会在几年内,做完所有人类研究人员在下个世纪所能做的研发工作;
■工业和经济的迅猛发展:增长机制会发生根本转变,这就像一场生产力革命,增速从非常缓慢,跃升到每年几个百分点的历史跨越;
■压倒性的军事优势:军事革命将随之而来,全新武器可能出现;
■能够推翻美国政府的能力:控制超级智能的人,很可能具有能力,从现有势力的手中夺取控制权。
利奥波德警告说,智能爆炸和后超级智能时期,将是人类历史上最动荡、最紧张、最危险和最疯狂的时期之一,可能在10年后我们所有人都会身陷其中。
图4. 人工智能将带来的爆炸性进展
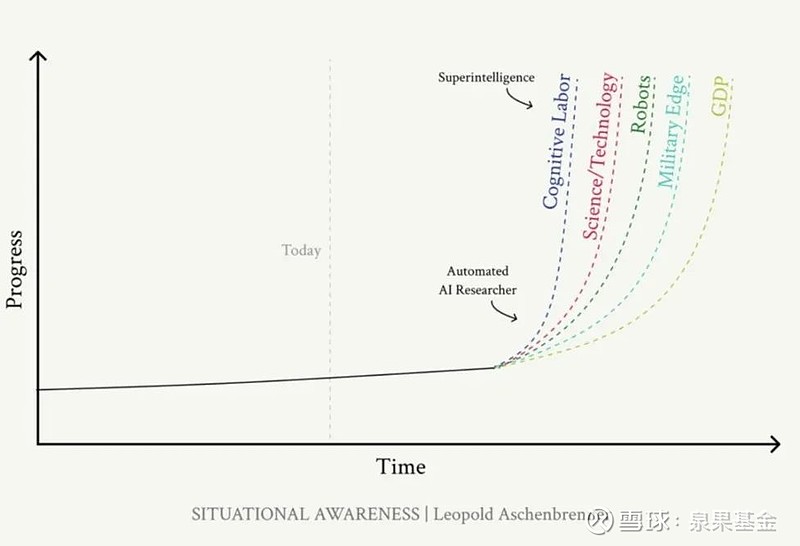
【3】现有超级对齐技术将会失效。
当前的AI对齐技术(如:通过人类反馈的强化学习,RLHF)在处理超人类智能时将会失效。
因为,RLHF的原理是:由人类对AI的行为进行评分,强化好行为,惩罚坏行为,由此来指导AI遵循人类的偏好。
然而,超级对齐问题在于,如何控制比我们聪明得多的AI系统。
当前的RLHF技术,在AI智能超过人类时,将难以为继。
比如:当一个超人类AI系统,用一种新的编程语言编写出百万行代码时,人类评审员将无法判断这些代码是否安全,这使得我们无法继续用RLHF的方法强化模型好的行为,或惩罚它的不良行为。
换句话说,再过几年,人工智能写出来的代码,人类都看不懂了,你还有什么能力评判AI的优劣?
如下图:

如果我们不能确保这些超智能系统遵循基本的行为约束,比如“不要撒谎”或“遵守法律”,它们可能会学会撒谎、寻求权力,甚至进行更加危险的行为。
这些系统的失控最终可能导致灾难性后果,包括但不限于“自我脱离服务器”,“入侵军事系统”……

一点希望:如何让AI对人类有益?
利奥波德文件所展示的可能只是冰山一角,但也足以让大家感受到,这几百个站在人工智能研发最前沿的科学家,内心的焦虑。
达到AGI*之后,人工智能可能会在不到一年的时间内,从大致达到人类水平的系统,并迅速过渡到超人类系统。一方面,这将极大地缩短发现和解决人类世界的问题的时间,但与此同时,一旦发生故障,后果也会极为严重,造成极高的风险。
* AGI(Artificial General Intelligence):指在广泛的认知任务中,等同或超过人类的人工智能。
因此,以伊利亚(OpenAI前首席科学家)为代表的AI研发科学家认为,需要快速适应并确保人类的对齐技术能够跟上这种变化。
最开始,很多人把希望寄托在伊利亚所带领的超级对齐部门上。但当OpanAI解散了这一部门后,很多科研人员绝望了。
“很多人意识到这一点后开始辞职,我不是第一个,也不是最后一个”。OpenAI 前员工丹尼尔·科泰洛 (Daniel Kokotajlo)是此次联名信公开署名人员中的一位。丹尼尔曾经是Open AI治理部门(Governance Division)的研究员,他说他加入 OpenAI 时曾希望,随着AI功能越来越强大,公司在安全研究方面,能投入更多资金,但 OpenAI 并没有这样做。
图5. OpenAI 前员工丹尼尔·科泰洛

从OpenAI离开时,丹尼尔被要求签署一份文件,其中包含一项“不贬损条款”,即禁止他发表任何批评公司的话。丹尼尔拒绝签署,也因此失去了既得股权。
丹尼尔即使失去全世界最炙手可热的科技公司的原始股权,也要签署这封公开信。
在文章开头我们提到,以实名签署方式背书这封联名信的,还有三位行业元老级的开创者,其中一人,就是斯图尔特·罗素(Stuart Russell)。
很多技术大牛把罗素奉为神明,认为他是自己在人工智能领域的启蒙之神。
早在1995年,罗素就与彼得·诺维格(Peter Norvig)共同撰写了权威著作——《人工智能:一种现代方法》(Artificial Intelligence:A Modern Approach),这本书被奉为“AI圣经”,如今已经再版4次,被135个国家的1500多所学院和大学用作人工智能教学的教科书。
图6. 加州大学伯克利分校教授图尔特·罗素(Stuart Russell)

早在十年前,这位撰写AI教科书的人就公开承认:“我的研究领域,对我自己所属的物种构成了潜在危险”。他还提出,“破解人机共存密码,人类最后的一个大问题”。他认为,如何面对人工智能,可能会成为人类历史上的最后一件大事。
因此,2016年,罗素在伯克利创立了人类兼容人工智能中心,该中心的使命就是“确保人工智能系统对人类有益”。
这个中心要研究的最主要的问题就是:“如何避免AI伤害人类?如何建构一个有利于人类的AI的目标体系?”
罗素认为,核心是要如何让AI具有一个完善而正确的价值观。
但实际上,想提炼一个“完全正确”的人类价值观非常难。
而万一给机器输入了一个错误价值观,其结果可能是毁灭性的。
罗素举了一个例子,比如,你让AI解决环境问题——因为二氧化碳含量升高而导致了海洋的快速酸化。于是,AI开发了一种新的催化剂,可以促进海洋和大气之间快速进行化学反应,让海洋的pH值恢复到正常水平。但不幸的是,在这个反应中,大气中1/4的氧气被消耗殆尽,结果我们只能痛苦地因窒息而死……
在AI完成目标时,如何防止造成同样的惨剧?

罗素并不认同目前“AI对齐”(AI alignment)的方案,他说:“据我所知,没有一个从事AI对齐的人认为,我们可以把一套普适的人类价值观输入到机器里。事实上,任何准备将‘价值观’和‘道德’传授给人工智能的想法,都是一种危险而愚蠢的。”
这主要有以下三个原因:
第一个也是最常见的误解,是建议在AI中预装一个单一的价值体系,来指导机器的行为。然而,到底存不存在一个“统一”的价值观呢?很多事情,一类人认可,但另一类人就不一定认可。人类的目标存在于我们每个人都心中,存在于全世界80亿人和纷繁多样的各种社会群体中。
另外,这也忽略了一系列问题:“谁来决定人类的价值观是什么?”“你打算把谁的价值观放进去?”“具体来讲,凭什么像罗素这种西方、白人、男性、生活富裕的科学家,就能代表全人类?就能具有这种编码AI价值观的权利?”……
第三个误解是,认为只要机器配备了“道德价值观”,就能够解决道德困境……别忘了,我们之所以称其为“道德困境”,就因为它们是一个两难境地,而且双方都有很好的论据。
因此,罗素建议,相比输入一个确定的价值观,应该假设“AI知道自己不知道人类的价值观”,进而让机器来预测每个人的具体偏好。
在这种方式下,AI其实并不明确知道我们的目标是什么,这很正常,毕竟,连我们自己都无法完全确定我们的目标。但这种不确定与不完整,只是一个特性,而不是一个漏洞。
因为,这种目标的不确定性,意味着机器会选择在必要时顺从人类:它们在不知道怎样解决的时候,会请求许可,接受纠正,甚至危机时刻能允许自己被关闭。
另外,从可行性上讲,AI是有能力去学习上亿种不同的偏好模型的。因为现在的Facebook系统已经维护了超过20亿个个人档案,这对于未来的人工智能系统来说,是非常好的学习语料。

当然,这种方法目前还只是一种思路,在实现起来,难度非常大。因为,这要求从根本上改变目前人们对“机器应该有明确任务目标”的假设,这意味着,我们需要打破并替换现在人工智能的一些基础设定,这会产生大量的重建和试错,但同时,也意味着人类和机器之间会生成新关系。
但至少,罗素在人类与人工智能博弈的道路上,给予了绝望的前沿研究人员们,一些新的光亮。
下期预告:
在人类生存问题之前,我们还面临一个更实际的问题,就是就业。在下一期【泉果探照灯】中,我们将进一步讨论,当AI取代脑力劳动时,我们还能出卖什么?
参考资料:
《A Right to Warn about Advanced Artificial Intelligence》, righttowarn.ai, Jun 4,2024
《Situational Awareness——the Decade Ahead》, Leopold Aschenbrenner, Jun 2024
《OpenAI Insiders Warn of “Reckless” Race for Dominance》, the New York Times,Jun 6
《Human Compatible:Artificial Intelligence and the Problem of Control》 Stuart Russell
《Time 100 | Stuart Russell, Professor, University of California》, Berkeley, Sep 7, 2023
《Book Review, ‘Human Compatible’: A Book About Artificial Intelligence (AI) That Asks Some Interesting Questions》, Forbes, Mar 3, 2020
《“Ilya究竟看到了什么?”泄密被OpenAI解雇的前员工长文爆料:2030年超级人工智能将至》36Kr, 2024年6月5日
法律声明:本资料不作为任何法律文件,不代表泉果基金的任何意见或建议,不构成泉果基金对未来的预测,所载信息仅供一般参考。前瞻性陈述具有不确定性风险,泉果基金不对任何依赖于本资料而采取的行为所导致的任何后果承担责任。