

01 挖矿、训练大模型为什么要用GPU
抛开游戏不谈,GPU在挖矿时代和AI时代迎来了两次需求大爆发,为什么挖矿/训练大模型需要GPU?而不是CPU。
一个常常被提及的例子是,GPU就像100个善于计算加法、乘法的小学生,而CPU就像1个数学系的博士生。当需要同时、大量计算简单加法和乘法运算的时候100个小学生显然比1个博士生好用多了,这便是GPU并行计算的特点。
挖矿和训练大模型需要的正好就是这样简单、大量的简单计算。
挖比特币简单来说就是计算一个名叫SHA256的函数,我们没必要了解SHA256具体是怎么工作的,只需要知道它需要非常大量简单的计算。AI大模型训练,以ChatGPT为例,其模型训练的原理是根据不同参数的权重去寻找一个概率最大的结果,归根结底是矩阵转换,本质上还是加法、乘法运算。
这就是为什么挖矿和训练大模型要用GPU的原因。
02 AI芯片
GPU中文名是图形处理器,设计之初目的是图形计算,我们在玩3D游戏的时候,画面的实时渲染,除了物体顶点坐标计算这种矩阵转换计算外,还有着色、贴图等步骤,这些步骤在AI的应用中就显得有些多余,AI芯片可以看做是继续在GPU设计上做减法,使之更好适合AI训练,因此AI芯片也称为AI加速卡,例如英伟达的A100、H100、H200芯片。
最早最有名的AI芯片可以追溯到谷歌的TPU,这个TPU,非常适合矩阵计算,非常适用于卷积神经网络模型。但随后Transformer(ChatGPT中的T)替代了卷积神经网络,谷歌的TPU就明显不如GPU好用了,可以简单理解为GPU的通用性更好,而各种AI芯片的对特定场景的AI训练适配性更好。
03 CUDA
CUDA是英伟达研发的一个编程模型,其核心思想是将硬件分为主机—CPU和协处理器—GPU,通过主机函数控制CPU,核函数控制GPU。
还是100个小学生的例子,如果要算100个加法问题,那么核函数的作用就是将这100个问题分给100个小学生。在这个模型中,开发人员可以用C语言来编写程序,并在支持CUDA的GPU上运行。如果将CUDA类比成IOS,将英伟达显卡类比成苹果手机,那么开发人员就像基于IOS系统开发各种APP一样,在CUDA中开发各种程序来调用GPU超强的计算能力,并应用于各个领域中。
04 NVLink和多卡集群
大模型训练,数据量都是非常大,一个GPU和AI加速芯片肯定不够,因此需要把这些数据分给多个GPU来训练,如何分数据在软件层面被称为分布式训练。
硬件层面的数据传输,英伟达的解决方案是NVlink,NVlink和PCle可以理解为数据传输的通道,但NVlink这条马路比PCle大多了,能实现更快的数据传输。以英伟达的GB200为例,最近市场爆火的铜缆连接方案就是在NVlink上用了5000根NVLink电缆,总长度达2英里。如果使用光传输,就必须使用光模块和retimer,这两个器件仅仅驱动NVLink就耗电20kw,而铜缆连接方案整个机架耗电120kw。
此外,一个服务器跑动辄上百亿数据的模型也不够,需要上千上万张显卡一起训练,这就需要将多个服务器连接起来,这便是下游客户需要的大规模集群解决方案,即多卡集群。要把那么多显卡统一规划管理,使其高效工作,并且稳定运行这可不是一件容易的事情。
05 主要国产GPU厂商
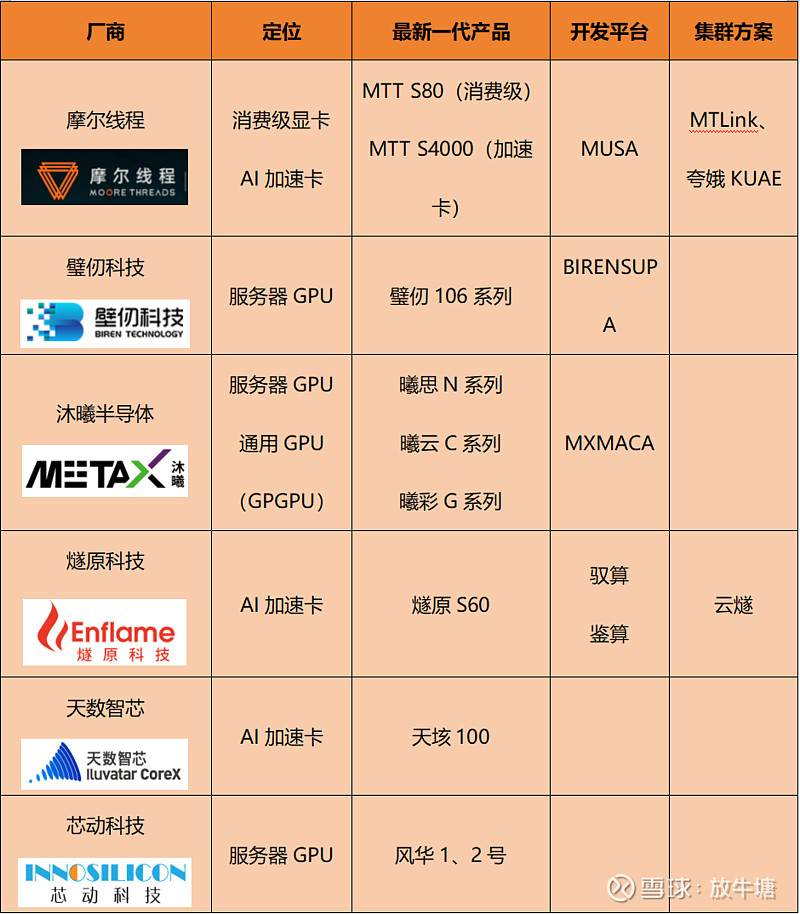
06 摩尔线程
摩尔线程是国内少数选择走全功能GPU路线的企业,其全功能GPU芯片采用自研的MUSA架构,集成AI计算加速、图形渲染、视频编解码、物理仿真和科学计算等四大引擎,是国内仅有的可从功能上对标英伟达的全国产GPU芯片。
作为国内AI芯片企业代表,摩尔线程已经建立了从芯片、板卡、集群到软件的全栈AI智算产品线。2023年,基于MTT S4000大模型智算加速卡,摩尔线程推出了以夸娥智算集群为核心的智算中心产品组合。
夸娥智算集群以其高兼容性、高稳定性、高扩展性及高算力利用率等优势,目前已经可以扩展至千卡和万卡,可以为千亿甚至万亿参数级别的大模型训练提供持续高效稳定的高性能算力支持。
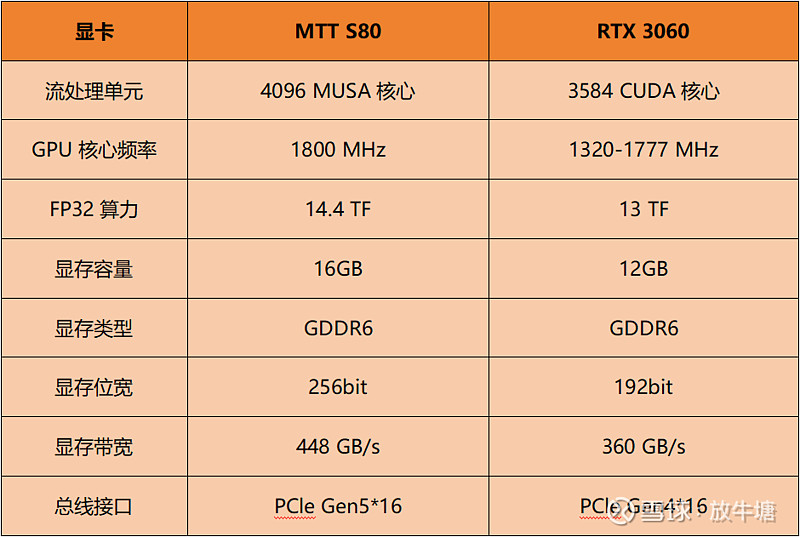
在消费领域,2022年摩尔线程发布MTT S80,MTT S80游戏显卡搭载了完整的“春晓”芯片核心,内置4096个MUSA流处理单元,在1.8GHz的主频下,能够提供14.4TFLOPS的单精度浮点算力。同时,MTT S80还配备有PCIe Gen5 x16接口以及16GB GDDR6大容量高速显存,再辅以8K超高清与1080P 360Hz高刷新率显示输出能力。
MTT S80参数对标英伟达RTX 3060系列,两者主要参数对比:
07 国产GPU发展痛点
简单来说英伟达的护城河就是国产GPU领域的发展痛点。硬件和软件方面,国产GPU厂商与英伟达相比虽有差距,但其实都在不断缩小,让人感到比较绝望的是生态上的差距。
CUDA是2006年推出的,距今接近二十年了,无数开发者基于CUDA开发了无数工具、框架、模型,想在这个圈子玩,CUDA就是个很难绕过的东西,这种生态上的壁垒类似苹果IOS的生态壁垒,这种生态是一个典型的双边市场,消费者越多,软硬件开发者越多,软硬件开发者越多,消费者越多,我们国产GPU厂商要从0开始建立自己生态,难如登天。
但这并不代表我们没有机会,美国的禁令加之下游巨大的需求缺口,让国产厂商有了撕开口子的机会,期待国产厂商能抓住这个机会突围吧。
