作者:沧笙踏歌
转载自AI部落联盟(id:AI_Tribe)
今天更新关于常见深度学习模型适合练手的项目。这些项目大部分是我之前整理的,基本上都看过,大概俩特点:代码不长,一般50-200行代码,建议先看懂然后再实现和优化,我看基本上所有的实现都有明显可优化的地方;五脏俱全,虽然代码不长,但是该有的功能都有,该包含的部分也基本都有。所以很适合练手,而且实现后还可保存好,以后很多任务可能就会用到。
本文包括简介、练手项目和我的建议(建议最好看看这部分)。
简介
本篇是深度学习最常见的 26 个模型汇总的姐妹篇,建议先看那篇再看本篇。本篇新增了 26 个模型的练手项目。
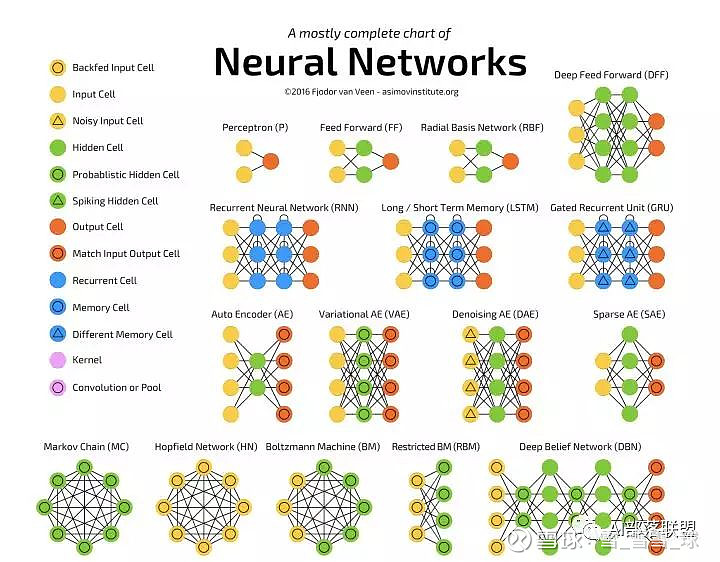
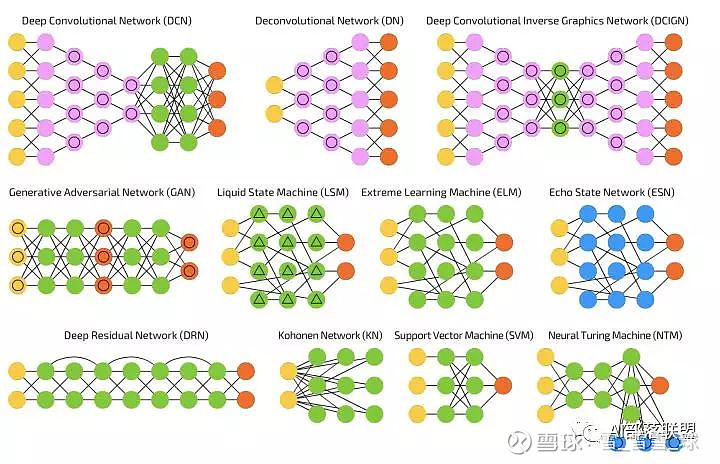
练手项目
2.1 Feed forward neural networks (FF or FFNN) and perceptrons (P)
前馈神经网络和感知机,信息从前(输入)往后(输出)流动,一般用反向传播(BP)来训练。算是一种监督学习。
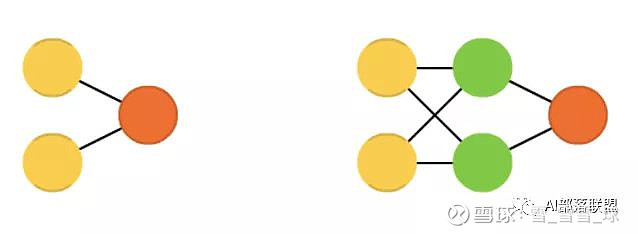
对应的代码:
2.2 Radial basis function (RBF)
径向基函数网络,是一种径向基函数作为激活函数的FFNNs(前馈神经网络)。
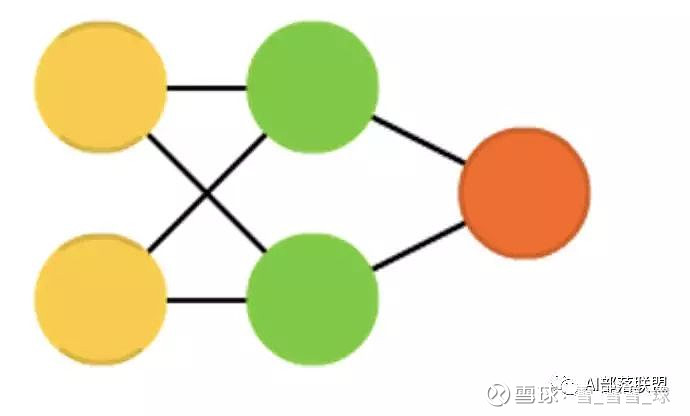
对应的代码:
2.3 Hopfield network (HN)
Hopfield网络,是一种每个神经元都跟其它神经元相连接的神经网络。
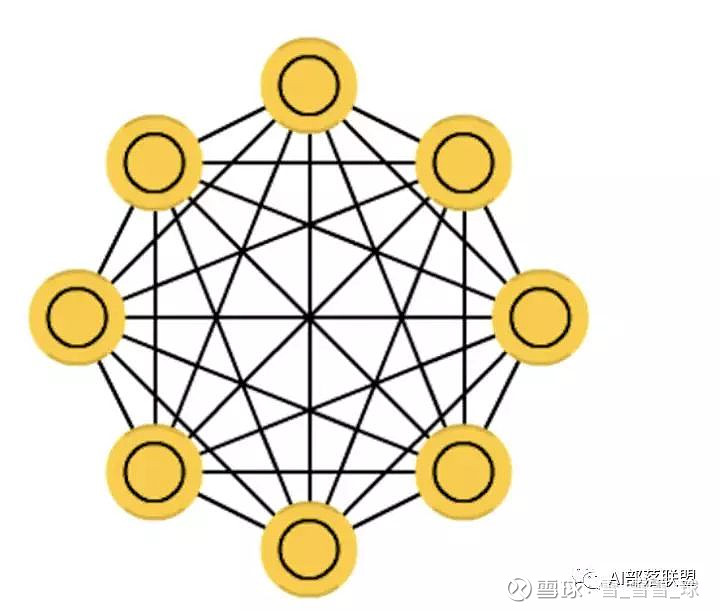
对应的代码:
2.4 Markov chains (MC or discrete time Markov Chain, DTMC)
马尔可夫链 或离散时间马尔可夫链,算是BMs和HNs的雏形。
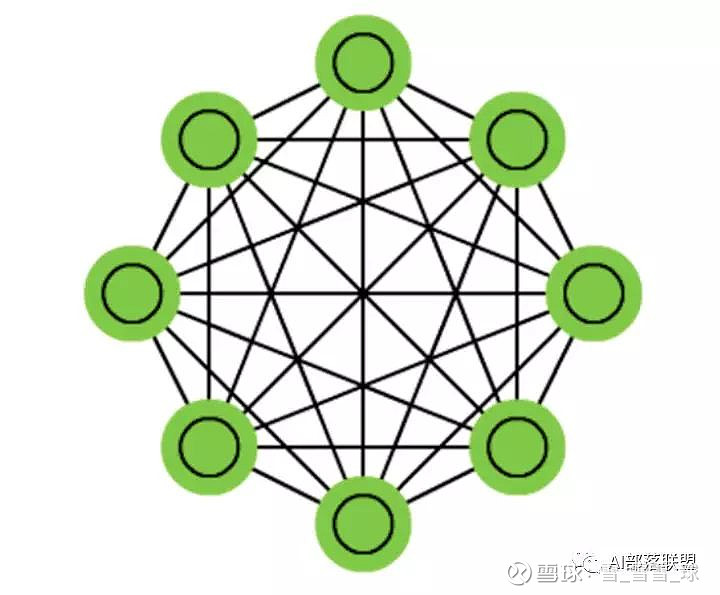
对应的代码:
Markov chains:网页链接
DTMC:网页链接
2.5 Boltzmann machines (BM)
玻尔兹曼机,和Hopfield网络很类似,但是:一些神经元作为输入神经元,剩余的是隐藏层。
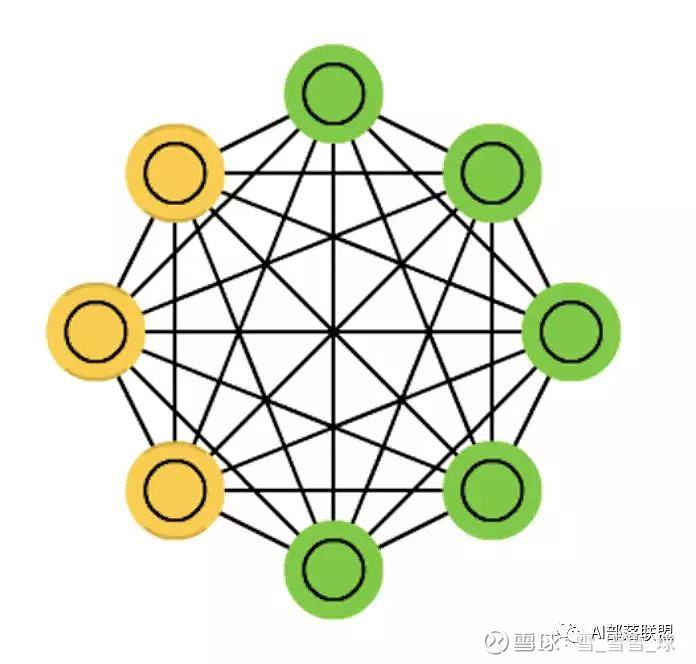
对应的代码:
2.6 Restricted Boltzmann machines (RBM)
受限玻尔兹曼机,和玻尔兹曼机 以及 Hopfield网络 都比较类似。
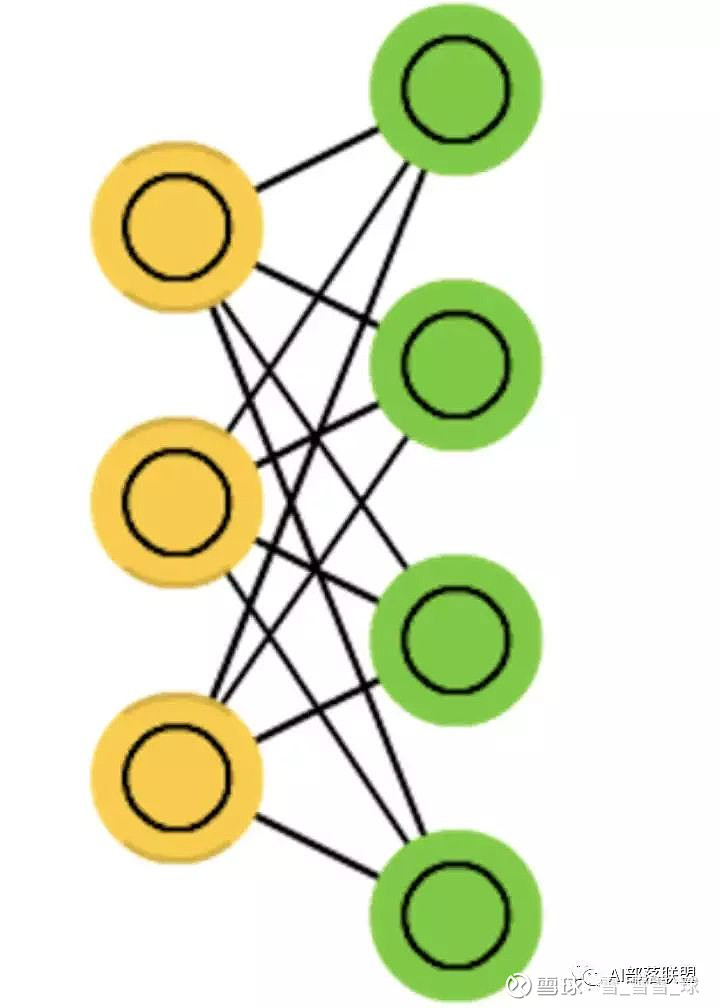
对应的代码:
2.7 Autoencoders (AE)
自动编码,和FFNN有些类似,它更像是FFNN的另一种用法,而不是本质上完全不同的另一种架构。
对应的代码:
2.8 Sparse autoencoders (SAE)
稀疏自动编码,跟自动编码在某种程度比较相反。
对应的代码:
2.9 Variational autoencoders (VAE)
变分自动编码,和AE架构相似,不同的是:输入样本的一个近似概率分布。这使得它跟BM、RBM更相近。
对应的代码:
2.10 Denoising autoencoders (DAE)
去噪自动编码,也是一种自编码机,它不仅需要训练数据,还需要带噪音的训练数据。
对应对应的代码:
2.11 Deep belief networks (DBN)
深度信念网络,由多个受限玻尔兹曼机或变分自动编码堆砌而成。
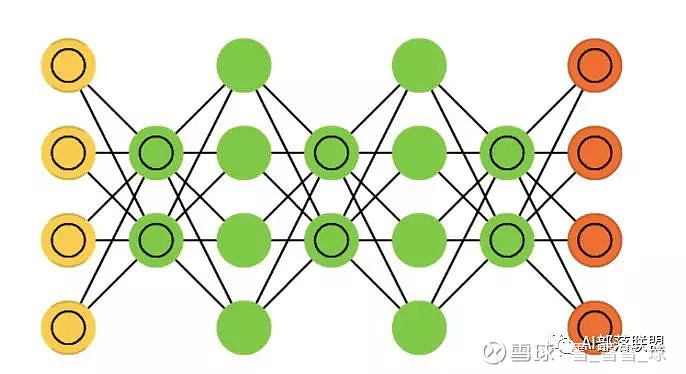
对应的代码:
2.12 Convolutional neural networks (CNN or deep convolutional neural networks, DCNN)
卷积神经网络,这个不解释也都知道。
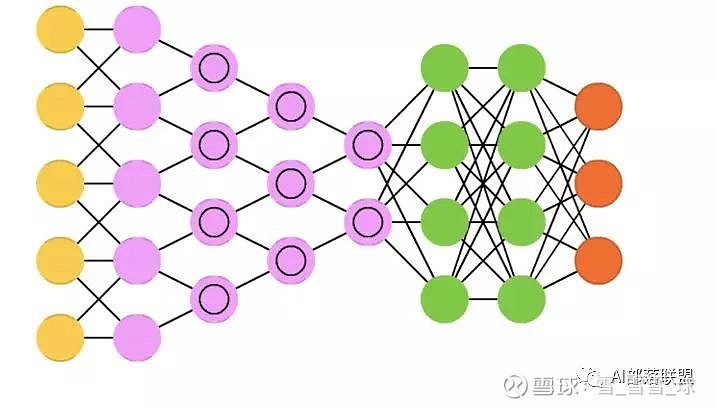
对应的代码:
CNN:网页链接
DCNN:网页链接
2.13 Deconvolutional networks (DN)
去卷积网络,又叫逆图形网络,是一种逆向的卷积神经网络。
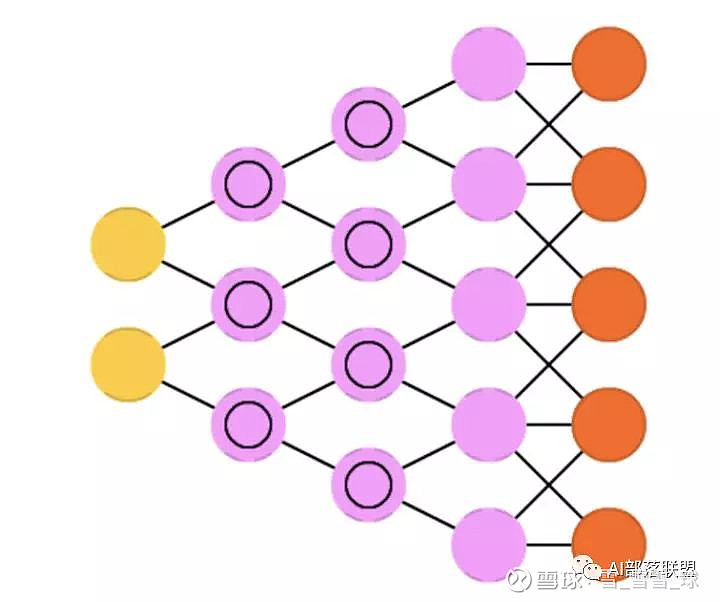
对应的代码:
2.14 Deep convolutional inverse graphics networks (DCIGN)
深度卷积逆向图网络,实际上是VAE,且分别用CNN、DNN来作编码和解码。
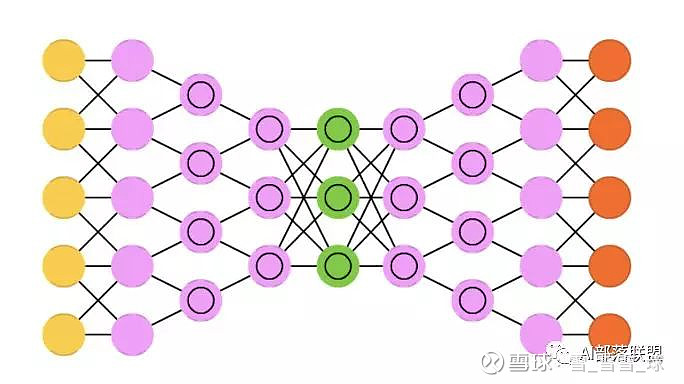
对应的代码:
2.15 Generative adversarial networks (GAN)
生成对抗网络,Goodfellow的封神之作,这个模型不用解释也都知道。
对应的代码:
2.16 Recurrent neural networks (RNN)
循环神经网络,这个更不用解释,做语音、NLP的没有人不知道,甚至非AI相关人员也知道。
对应的代码:
2.17 Long / short term memory (LSTM)
长短期记忆网络, RNN的变种,解决梯度消失/爆炸的问题,也不用解释,这几年刷爆各大顶会。
对应的代码:
2.18 Gated recurrent units (GRU)
门循环单元,类似LSTM的定位,算是LSTM的简化版。
对应的代码:
2.19 Neural Turing machines (NTM)
神经图灵机,LSTM的抽象,以窥探LSTM的内部细节。具有读取、写入、修改状态的能力。
对应的代码:
2.20 Bidirectional recurrent neural networks, bidirectional long / short term memory networks and bidirectional gated recurrent units (BiRNN, BiLSTM and BiGRU respectively)
双向循环神经网络、双向长短期记忆网络和双向门控循环单元,把RNN、双向的LSTM、GRU双向,不再只是从左到右,而是既有从左到右又有从右到左。
对应的代码:
BiRNN:网页链接
BiLSTM:网页链接
BiGRU:网页链接
2.21 Deep residual networks (DRN)
深度残差网络,是非常深的FFNN,它可以把信息从某一层传至后面几层(通常2-5层)。
对应的代码:
2.22 Echo state networks (ESN)
回声状态网络,是另一种不同类型的(循环)网络。
对应的代码:
2.23 Extreme learning machines (ELM)
极限学习机,本质上是随机连接的FFNN。
对应的代码:
2.24 Liquid state machines (LSM)
液态机,跟ESN类似,区别是用阈值激活函数取代了sigmoid激活函数。
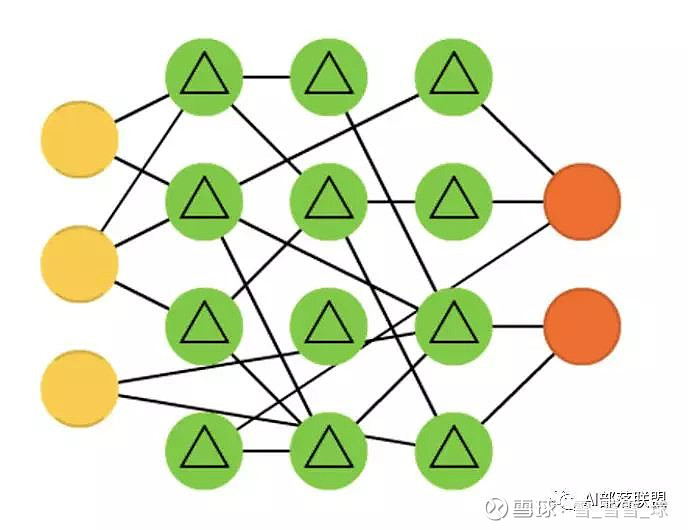
对应的代码:
2.25 Support vector machines (SVM)
支持向量机,入门机器学习的人都知道,不解释。
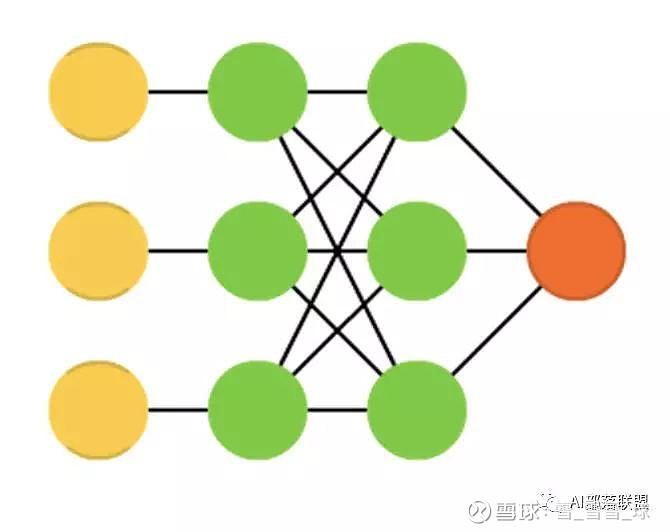
对应的代码:
2.26 Kohonen networks (KN, also self organising (feature) map, SOM, SOFM)
Kohonen 网络,也称之为自组织(特征)映射。
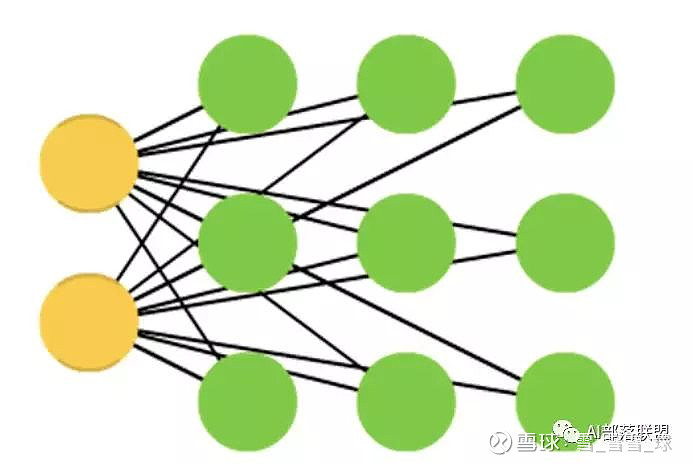
对应的代码KN/SOM:
后续建议
我个人感觉能力提升最快的方式是:先横向学习一个领域,做到全面的认识;然后从头到尾一项一项去突破,做到有深度。如果今天学点这个,明天学点那个,水平提升很慢,建议顺着技术发展的主线从头到尾学完。技术是无止境的,积累很重要,但有量远远不够,还得讲究方法。
对应到本文,学会并实现和优化这些模型,远远不够。我建议还可以有如下尝试:
单层模型实现之后,试试多层或者模型stack;
试试模型的结合,比如LSTM/GRU+CNN/DCNN、CNN/DCNN+LSTM/GRU、LSTM/GRU+CRF等;
在一些模型上加attention(这里很多模型适合加);
利用这些模型解决一些比较简单的小问题,比如用CNN识别数字、LSTM+CRF做NER等;
性能方面的提升,比如支持分布式训练、支持GPU等;
把这些模型做成一个框架,到时候记得通知我,我一定拜读。
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
CTA核心技术及应用峰会
◆
5月25-27日,由中国IT社区CSDN与数字经济人才发展中心联合主办的第一届CTA核心技术及应用峰会将在杭州国际博览中心隆重召开,峰会将围绕人工智能领域,邀请技术领航者,与开发者共同探讨机器学习和知识图谱的前沿研究及应用。
更多重磅嘉宾请识别海报二维码查看。目前会议8折预售票抢购中,点击阅读原文即刻抢购。添加小助手微信15101014297,备注“CTA”,了解票务以及会务详情。
推荐阅读
赌5毛钱,你解不出这道Google面试题
@程序员,别再自己闷头学了
人工智能的浪潮中,知识图谱何去何从?
你在B站看番,她却在B站学习!爬一爬B站高播放量编程类视频
“踏实工作 7 年,辞职时老板头都不抬”
10 种最流行的 Web 挖掘工具 | 程序员硬核评测
阿里云的物联网之路
60倍回报! AI工程师用OpenAI创建了一个比特币自动交易工具! 这里是详细做法 | 技术头条
小姐姐公开征婚高智商 IT 男:微信号竟要质数解密?

点击阅读原文,了解「CTA核心技术及应用峰会」