《从Sora看多模态大模型发展》的研报来自浙商证券,写于2024年2月。
这篇报告主要探讨了多模态大模型的发展趋势,特别是OpenAI发布的视频生成模型Sora,以及其对行业发展的影响。以下是报告的核心内容概述:
Sora模型的发布:
- OpenAI于2024年2月16日发布了视频生成模型Sora,该模型能够生成长达1分钟、不同宽高比和分辨率的视频和图片。
- Sora基于Diffusion Transformer技术,结合了视频压缩网络、潜空间patch、直接在原始大小训练和重新标注技术,能够处理图像和视频输入,实现多种视频生成和编辑功能。
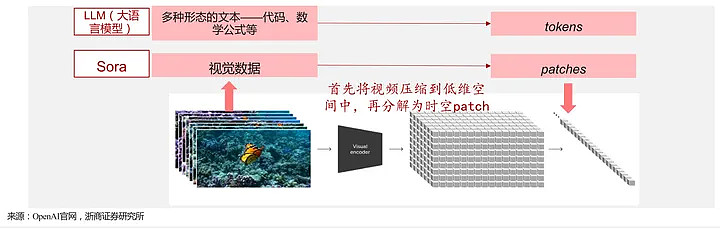
视频压缩网络(Video compression network):减少视觉数据维度。输入原始视频,输出一个在时间和空间上都压缩了的潜在空间。Sora在这个压缩后的潜在空间中进行训练。(同时训练了一个解码器将生成的潜在表征转回原像素空间)
潜空间patch(Spacetime latent patches ):类比Transformer tokens,推理时通过在合适大小的网格中随机初始化patch控制生成视频的大小。
直接在原始图片的大小上训练:过去往往将视频或者图片压缩到固定大小(比如4秒钟、分辨率256*256),Sora直接在原始素材规格上训练。
为视频训练素材生成详细字幕和标注:Re-captioning technique字幕自动生成。首先训练一个能生成详细描述的标注模型,然后用它为训练集中的视频生成文本说明。DALL E3中已经使用过,使用GPT将简短prompt转化为详细说明,这些说明会被输入到视频模型中。这可以增强文本理解能力,可以提高文本的保真度和视频的整体质量,使得Sora能够生产准确遵循用户提升的高质量视频。
Sora核心能力:3D一致性、物体持久性、世界交互、模拟数字世界
Sora模型的局限性:虽然能模拟一些基础物理互动,比如玻璃的碎裂,但还不够精确;
其他相互作用,比如吃食物,并不总是能产生物体状态的正确变化;
长视频中存在逻辑不连贯,或者物体会无缘无故出现的现象。
多模态大模型的商业化前景:
- 国内外厂商如谷歌、字节跳动等也在布局多模态大模型领域,预计2024年文生视频将进入商业化探索阶段。
- 高质量数据和底层通用大模型是文生视频能力的关键因素,随着技术的进步,文生视频在时间长度、画面清晰度和内容逼真程度等方面有望实现显著提升。
全球视频内容市场的潜力:
- 据数据显示,2025年全球数字视频内容市场规模有望达到3271.9亿美元,2021-2025年复合年增长率约为13.7%。
- 海外已有Synthesia、Runway等厂商在文生视频领域形成成熟商业方案,应用于企业产品介绍、操作指南、客户服务等场景。
建议关注的标的公司:
- 大模型厂商:科大讯飞、云从科技、微软、谷歌。
- 多模态应用厂商:万兴科技、虹软科技、焦点科技、Adobe。
公司名称代码AI+视频相关业务/产品科大讯飞002230.SZ国产大模型龙头,多模态领域技术积累深厚海康威视002415.SZ研发视觉多模态大模型大华股份002236.SZ自研大华星汉大模型云从科技-UW688327.SH国内CV领域龙头厂商之一焦点科技002315.SZAI外贸虚拟人视频助手虹软科技688088.SH视觉AI开放平台万兴科技300624.SZAI视频领域龙头,“天幕”大模型国投智能300188.SZAI视频图像鉴真工作站当虹科技688039.SHAI智能视频解决方案网达软件603189.SH积极推动“大视频+AI"在垂直领域的布局丝路视觉300556.SZ子公司是视频染技术龙头商汤-Whttps://0020.HK“日日新SenseNova"大模型拓尔思300229.SZ并面向媒体、金融、政务领域、拓天大模型汉王科技002362.SZ笔智能交互、NLP技术、大数据处理、智能人机交互、垂直领域大模型
风险提示:
- AI技术迭代不及预期的风险。
- AI商业化产品发布不及预期的风险。
- 政策不确定性带来的风险。
- 下游市场不确定性带来的风险。
报告还详细分析了多模态AI的核心技术环节、Sora模型的技术路线和应用案例,以及国内外其他厂商的AI视频生成算法及工具。此外,报告对AIGC在视频领域的商业化现状与展望进行了探讨,并预测了千亿级数字视频生成市场的未来潜力。