具有高级数学推理能力的通用人工智能有可能开辟科学技术的新领域。
来源|多知
作者|Penny
前一段时间,部分大模型连9.11和9.9谁大都分不清,而今,高级数学推理问题被破解了!
7月25日,谷歌DeepMind团队发文宣布,推出基于强化学习的新型形式数学推理系统 AlphaProof,以及几何求解系统的改进版本 AlphaGeometry 2。这两个系统共同解决了今年国际数学奥林匹克(IMO) 六道题目中的四道,首次在竞赛中取得与银牌得主同等的成绩。
谷歌DeepMind团队认为,具有高级数学推理能力的通用人工智能(AGI)有可能开辟科学技术的新领域。
“这是机器学习和人工智能领域的一大进步,”参与该项目的谷歌 DeepMind 研究副总裁 Pushmeet Kohli 表示。“迄今为止,还没有开发出能够以如此高的成功率和如此普遍性解决问题的系统。”
作为 IMO 工作的一部分,DeepMind还试验了一种基于Gemini和谷歌最新研究的自然语言推理系统,以实现高级问题解决技能。该系统不需要将问题翻译成形式语言,并且可以与其他 AI 系统结合使用。DeepMind还在今年的 IMO 问题上测试了这种方法,结果显示出巨大的潜力。
DeepMind的团队正在继续探索多种用于推进数学推理的人工智能方法,并计划很快发布有关 AlphaProof 的更多技术细节。
DeepMind团队提到:“很高兴看到未来数学家们能够利用人工智能工具探索假设,尝试大胆的新方法来解决长期存在的问题,并快速完成耗时的证明步骤——而像Gemini这样的人工智能系统在数学和更广泛的推理方面的能力将变得更强。”
01
高级数学推理进入新阶段,教育将如何改变?
AI在数学推理方面的进步让许多人感到震撼,同时也引发了对教育的思考。
前美国奥数队总教练罗博深教授认为,“极强的学术技能将不再是一人独有的硬核技术。而拥有能够认识未来世界的全局的洞察力和应变力将变得至关重要。学会发现问题提出问题,学会整合和利用资源,理解那些在完成目标的过程中遇到的一个个小问题,才是一个人能够有策略地解决任何难题的关键。按照目前的发展趋势,人类无法在速度和准确性上击败计算机,但更加迫在眉睫的是,我们需要找到属于自己的那条,旁人和人工智都能未曾踏入的河流。”
对于孩子教育的问题,他说:“现在,AI已经能够解决IMO问题,这意味着它们已经学会了解决没有见过的新问题,这几乎是人类最有价值的技能之一,因此,现有的教育方法需要快速改变。不管人们是否愿意承认,我们的教育结构目前深受标准化考试影响,学生仍然在‘被迫’追求解题的熟练程度。但现在,每个人都需要学习如何解决他们以前从未见过的问题,以跟上AI的发展。
此外,技术越强大,我们就越需要努力保护人类文明和人性的光辉。我们需要建立一个人们愿意共同友好合作,相互支持的,让人类感到安全和进步的社群,而不是成为一个个为了竞争在内卷中彼此争斗打压的个体。分裂则衰。对我来说,这与建立人类智能密切相关,如果我们培养一个寻求打败他人的‘人才’而不是帮助他人的人才可能是有害的。”
剑桥大学专门研究数学和人工智能研究员凯蒂·柯林斯 (Katie Collins) 表示:“创建能够解决更具挑战性的数学问题的人工智能系统可以为激动人心的人机合作铺平道路,帮助数学家解决和发明新类型的问题。这反过来可以帮助我们更多地了解人类如何解决数学问题。”
02
模型达到了国际奥数IMO银牌水平
人工智能模型可以轻松生成论文和其他类型的文本。然而,它们在解决数学问题方面却远远不够,因为数学问题往往需要逻辑推理,而这超出了大多数当前人工智能系统的能力。而谷歌DeepMind的新模型终于突破了高难度的数学问题。
众所周知,国际数学奥林匹克竞赛是历史最悠久、规模最大、最负盛名的青年数学竞赛,自 1959 年起每年举办。
每年,顶尖的大学前数学家们都要训练,有时要训练数千小时,以解决代数、组合学、几何学和数论领域的六道极其困难的难题。菲尔兹奖是数学家的最高荣誉之一,许多获奖者都曾代表他们的国家参加过国际数学奥林匹克比赛。
近年来,一年一度的国际数学奥林匹克竞赛也被广泛认为是机器学习领域的一大挑战,也是衡量人工智能系统高级数学推理能力的理想基准。
今年,DeepMind将联合人工智能系统应用于 IMO 主办方提供的竞赛问题。DeepMind的解决方案由著名数学家、IMO 金牌得主和菲尔兹奖得主蒂莫西·高尔斯爵士教授和两届 IMO 金牌得主、IMO 2024 问题选择委员会主席约瑟夫·迈尔斯博士根据 IMO 的评分规则进行评分。
DeepMind采用的方式是:首先,问题被手动翻译成正式的数学语言,以便模型理解。在正式比赛中,学生分两节提交答案,每节 4.5 小时。而DeepMind的模型在几分钟内解决了一个问题,而解决其他问题则需要三天时间。
AlphaProof 通过确定答案并证明其正确性,解决了两道代数题和一道数论题。其中包括比赛中最难的一道题,今年的 IMO 比赛中只有五名选手解决了这道题。AlphaGeometry 2 解决了几何问题,而两道组合问题仍未解决。
六道题目每道可得 7 分,总分最高为 42 分。DeepMind的模型最终得分为 28 分,每道题目都获得满分 ,相当于银牌类别的最高分。今年,金牌门槛为 29 分,在正式比赛中,609 名参赛者中有 58 人达到了金牌门槛。
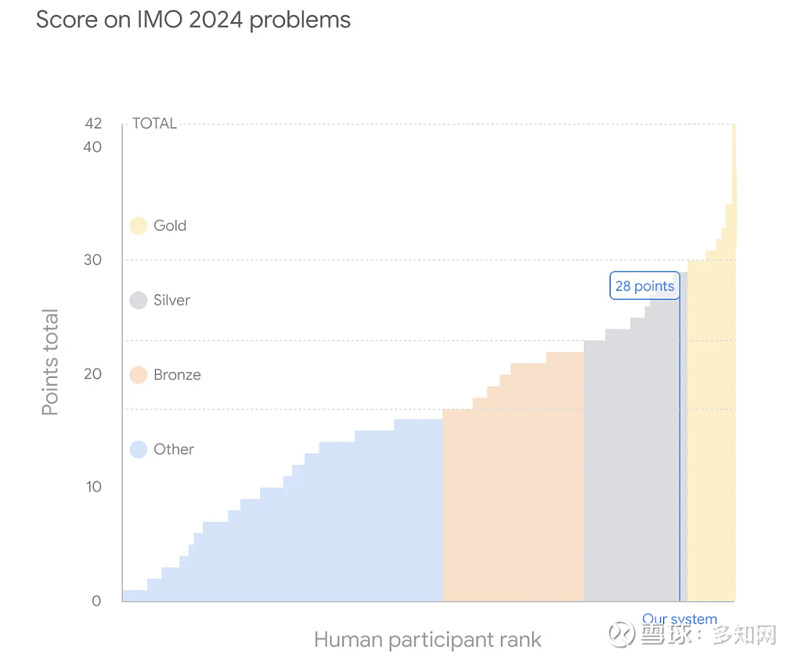 (图表显示了谷歌AI 模型在 IMO 2024 中相对于人类竞争对手的表现,其获得了总分 42 分中的 28 分,达到与比赛中银牌得主相同的水平。)
(图表显示了谷歌AI 模型在 IMO 2024 中相对于人类竞争对手的表现,其获得了总分 42 分中的 28 分,达到与比赛中银牌得主相同的水平。)
03
AlphaProof:一种形式化的推理方法
AlphaProof 是一个自我训练的系统,用于用形式语言Lean来证明数学陈述。它将预先训练好的语言模型与AlphaZero强化学习算法结合在一起,后者之前曾自学过如何掌握国际象棋、将棋和围棋等益智游戏。
形式语言的关键优势在于,涉及数学推理的证明可以得到形式化验证,以确保其正确性。然而,它们在机器学习中的应用此前一直受到人工编写数据量非常少的限制。
 (AlphaProof研发团队部分成员)
(AlphaProof研发团队部分成员)
相比之下,基于自然语言的方法尽管能够访问数量级更多的数据,却可能产生看似合理但实际上不正确的中间推理步骤和解决方案。DeepMind通过微调Gemini模型来自动将自然语言问题陈述转换为形式陈述,从而在这两个互补领域之间建立了一座桥梁,创建了一个包含各种难度的形式化问题的大型问题库。
当遇到问题时,AlphaProof 会生成解决方案候选,然后通过搜索 Lean 中可能的证明步骤来证明或反驳这些候选。每个找到并验证的证明都会用于强化 AlphaProof 的语言模型,从而提高其解决后续更具挑战性的问题的能力。
在比赛开始前的几周内,DeepMind通过证明或反证数百万道题目来训练 AlphaProof,题目涉及各种难度和数学主题。比赛期间也应用了训练循环,不断强化对竞赛题目自生成变体的证明,直到找到完整的解决方案。
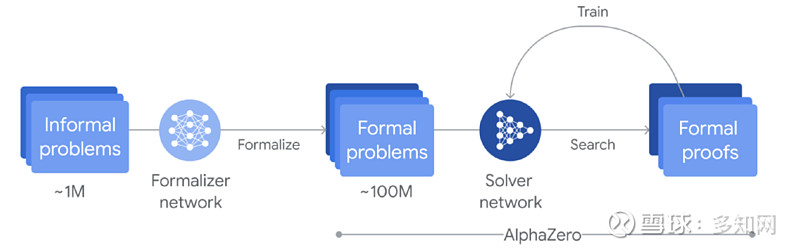 (AlphaProof 强化学习训练循环的流程图:形式化网络将大约一百万个非正式数学问题翻译成正式数学语言。然后,求解器网络搜索问题的证明或反证,通过 AlphaZero 算法逐步训练自身以解决更具挑战性的问题。)
(AlphaProof 强化学习训练循环的流程图:形式化网络将大约一百万个非正式数学问题翻译成正式数学语言。然后,求解器网络搜索问题的证明或反证,通过 AlphaZero 算法逐步训练自身以解决更具挑战性的问题。)
04
AlphaGeometry 2:解决更具挑战性的几何问题
AlphaGeometry 2 是AlphaGeometry的一个显著改进版本。它是一个神经符号混合系统,其中的语言模型基于Gemini,并使用比其前身多一个数量级的合成数据从头开始训练。这有助于该模型解决更具挑战性的几何问题,包括有关物体运动和角度、比率或距离等方程式的问题。
AlphaGeometry 2 采用的符号引擎比其前代产品快两个数量级。当遇到新问题时,会使用一种新颖的知识共享机制,来实现不同搜索树的高级组合,以解决更复杂的问题。
由于AlphaGeometry 2 比前代系统接受了更多合成数据的训练,因此能够解决更具挑战性的几何问题。
在今年的比赛之前,AlphaGeometry 2 可以解决过去 25 年所有 IMO 几何问题中的 83%,而其前身的解决率仅为 53%。在 IMO 2024 中,AlphaGeometry 2在获得形式化后 19 秒内就解决了问题 4。

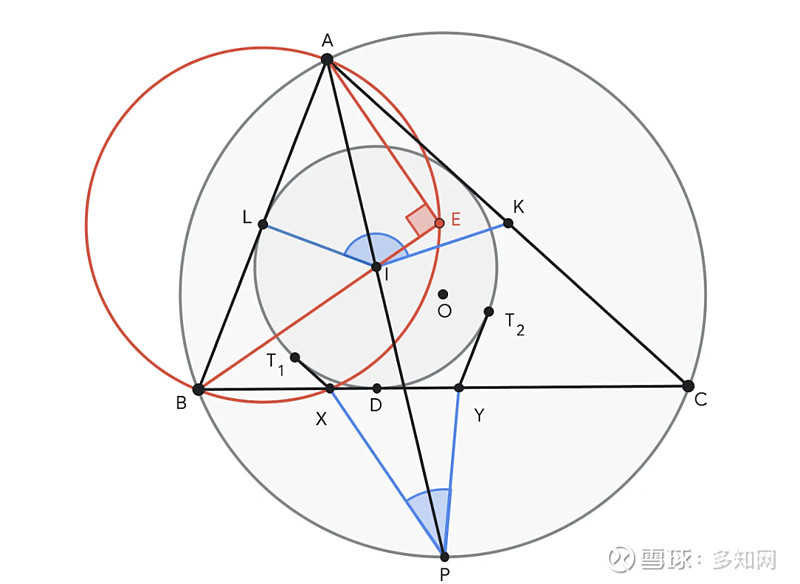 (问题 4 ,要求证明 ∠KIL 与 ∠XPY 之和等于 180°。AlphaGeometry 2 建议构造 E,即直线 BI 上的一个点,以便 ∠AEB = 90°。点 E 有助于确定 AB 的中点 L,从而创建证明结论所需的多对相似三角形,例如 ABE ~ YBI 和 ALE ~ IPC。)
(问题 4 ,要求证明 ∠KIL 与 ∠XPY 之和等于 180°。AlphaGeometry 2 建议构造 E,即直线 BI 上的一个点,以便 ∠AEB = 90°。点 E 有助于确定 AB 的中点 L,从而创建证明结论所需的多对相似三角形,例如 ABE ~ YBI 和 ALE ~ IPC。)
谷歌DeepMind的原文:
谷歌数学模型解答第四题的全过程:
END
本文作者:王上

《教育科技这一年·2022》+《培训行业这一年·2021》+《教育科技行业图谱2022-2023》,重磅发售!
点击购买↓