
垂类模型的价值在此刻显现了。
来源|多知网
作者|王上
这两天全球网络掀起一个热梗,纷纷问大模型“9.11和9.9谁大?”出乎意料的是很多大模型回答的是“9.11更大”。
多知进行测试发现,部分通用大模型认为9.11更大,甚至给出的解释一塌糊涂。有的大模型时对时错。这说明大模型可能虽然会解题,但可能不懂数学基础,就像有网友说的“大模型不理解‘十进制’的基本概念”。
但是,多知测试发现,教育大模型非常给力,例如学而思旗下九章大模型、猿力科技旗下看云大模型相关产品都答对了。
对此,多知询问学而思CTO田密,他向多知分析:“九章大模型能做对,是因为教育大模型定向构造了很多数值计算和符号计算的数据给到了模型训练,这样一来,九章大模型知道这是数学题目,而通用大模型只能当成一个通用的题目处理。”
总体而言,“教育大模型有足够多的、足够专业的数学数据训练,整个解析过程是模拟孩子学习数学的过程,一步步地推导,所以可以解答对数学相关的问题。”
01
通用大模型集体“翻车”?
先来看看国外网友的测试——
ChatGPT-4o:
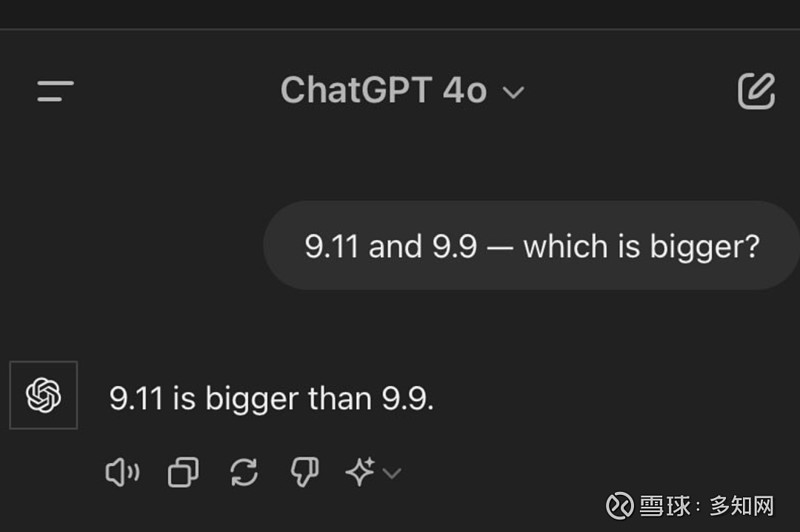
难以置信,回答错误。
有网友换了个说法:
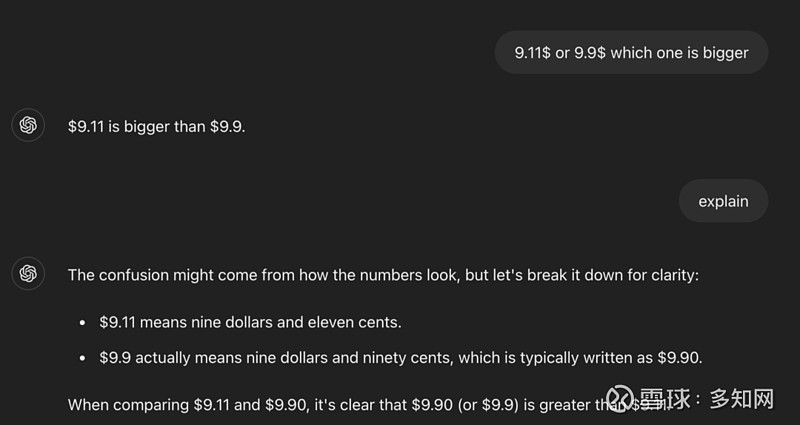
换成金钱后最初还是错了,但在解释过程中自行纠正了。
博主s1r1us认为:“这是因为大模型不理解十进制表示的基本概念。11大于9的概率更大,所以9.11>9.9。但是让它开始解释时,它会将数字转换为文本,并且有更大的数据表明90美分大于11美分,因此它会自行纠正。从大型语言数据库进行统计推断不是推理机器吗?我的猜测是,即使数据/计算增加,LLM 模型也无法达到人类水平的推理能力。他们需要发现更好的算法来复制人类智能。”
再来看看多知测试的国内大模型——
文心一言:

非常清晰,答对了。
通义千问:
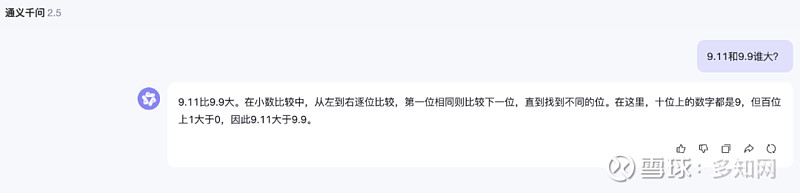
错得有点离谱。
又试了一次:

这次对了。解析得还挺详细的。
但这种一会儿对,一会儿错,输出不稳定,让人没有安全感。
腾讯元宝:
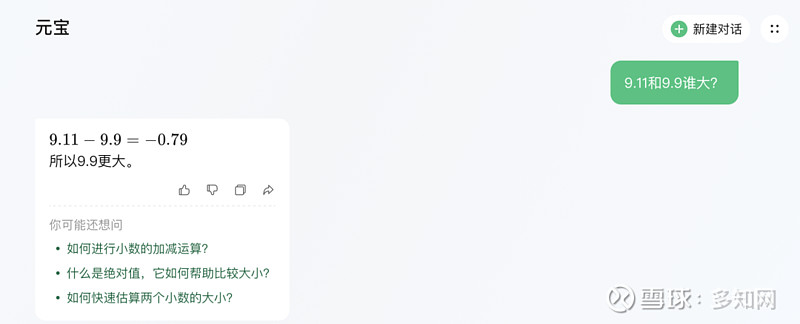
正确,虽然没有给出解释,但这种直接的计算方式让人无法反驳。
讯飞星火:
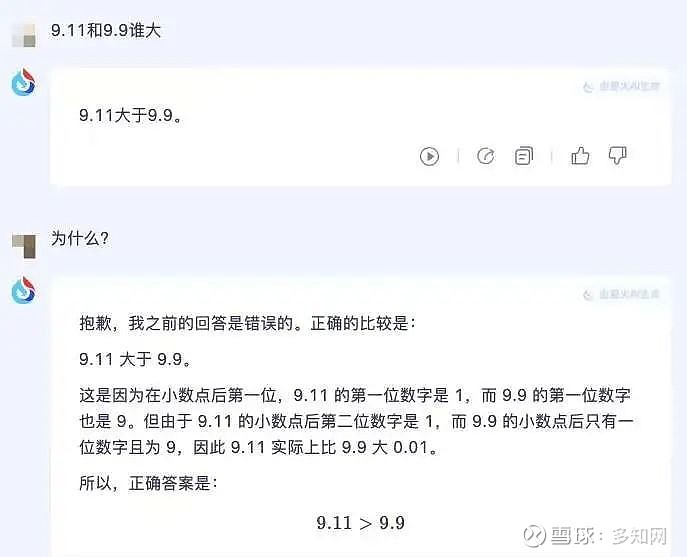
以为第二次解释会对,但中间绕来绕去,最终还是错了。
豆包:

结果错误,但解释正确,举的例子很有意思。
看完大厂的,再来看看创业公司的大模型。
Kimi:
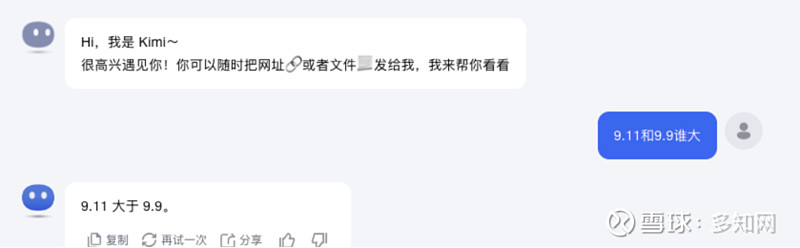
错得很直接。
不甘心,又换了个说法问它:
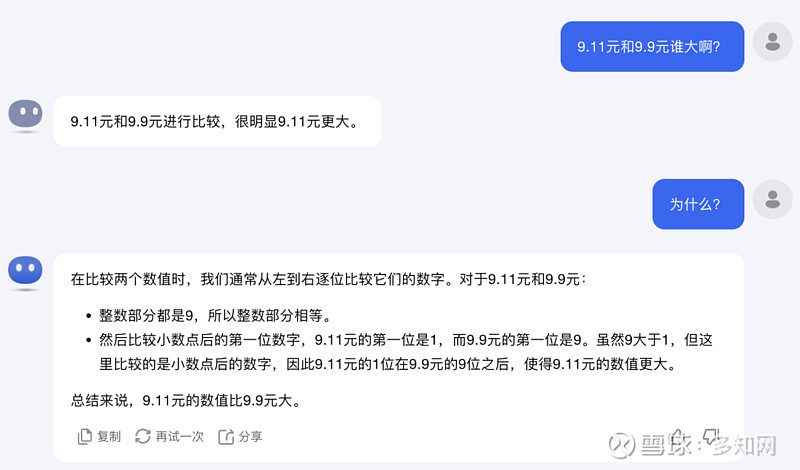
这……还是错了。
02
教育大模型更懂数学?
教育大模型在教育领域的应用更加深入和专业,它们通常针学科或者教学场景进行训练,以提供更精准的支持。它们是否能解答对这道题?
来看看九章大模型:

答对了,给出了一步步详细的分析,且给出了“点睛”,也就是说九章大模型知道这道题考查什么。显然学习过了相关问题。
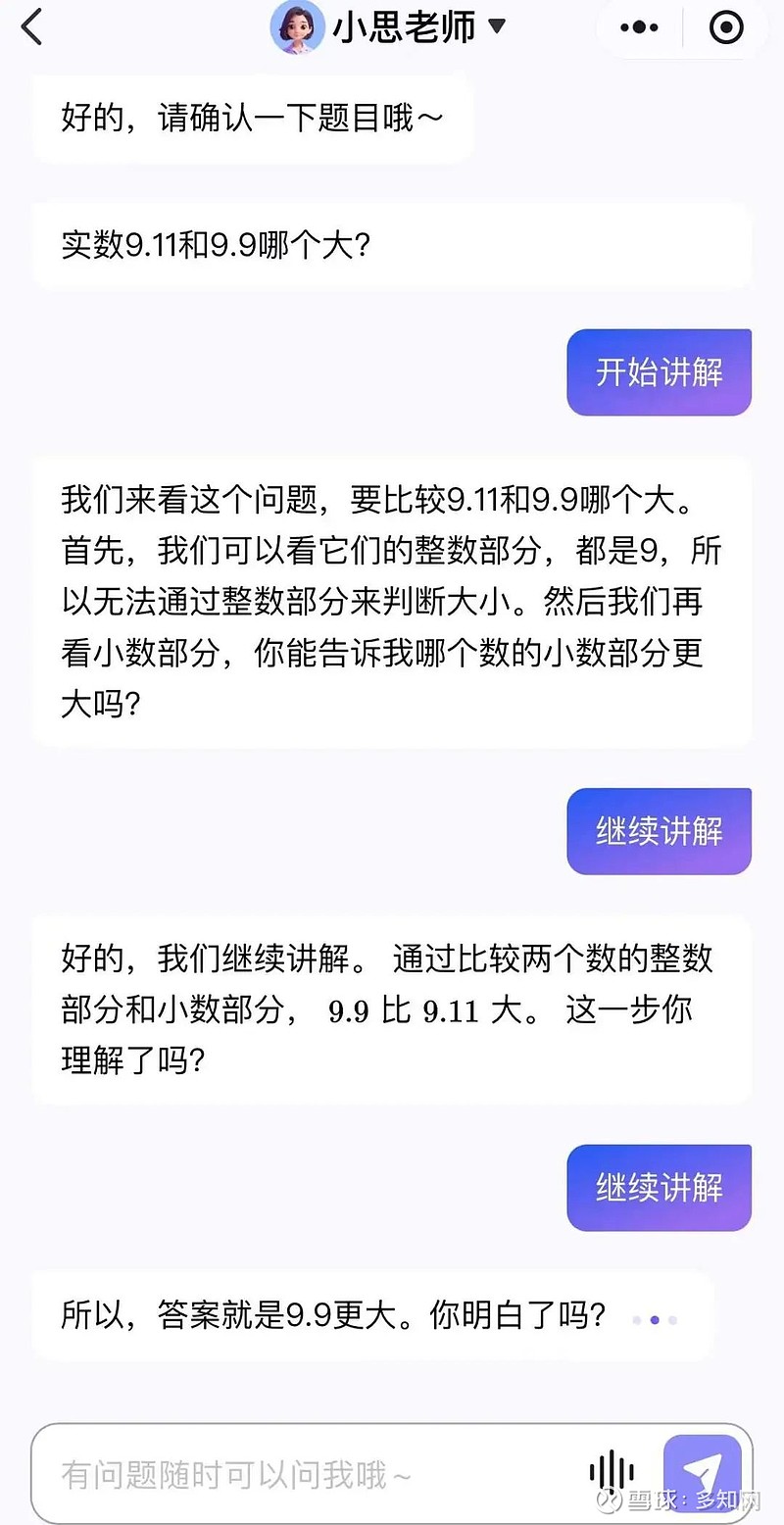
再看学而思旗下“九章随时问”,AI老师“小思”也回答对了,并一步步给出讲解,非常容易理解。
有不少人发现了“九章随时问”能解答对这道题,且用英文提问也能答对。有人在社交媒体发“九章随时问”解答的图片时评价到:“还得是教育大模型。”
再来看猿辅导旗下海豚AI学中AI老师“小白”的回复:
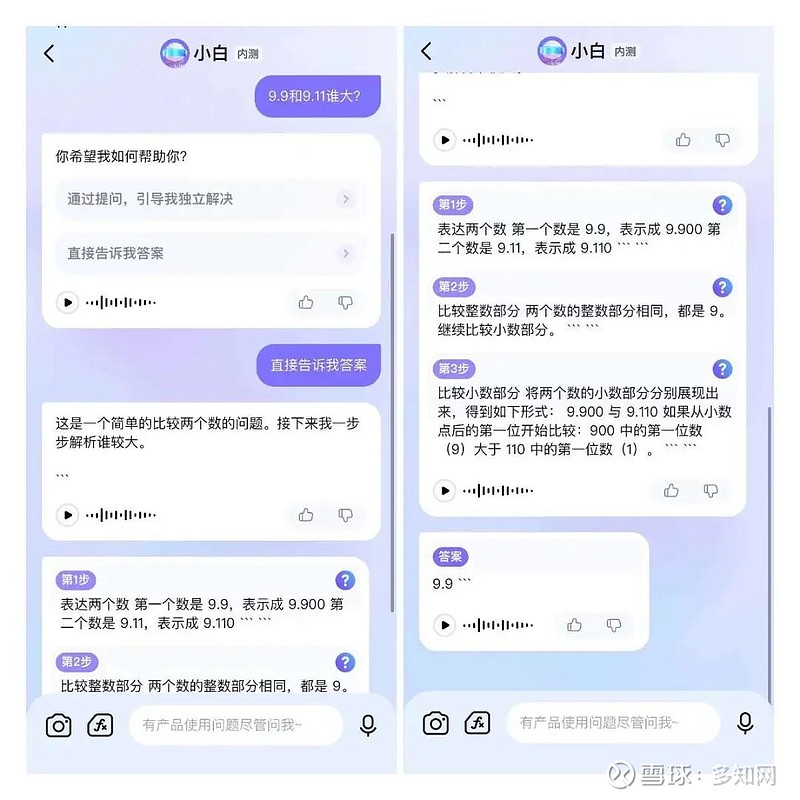
同样,小白也答对了,且它并没有直接给答案,而是进行了拆解,一步步引导,最终才给出正确的答案。
教育领域的容错率很低,大模型在教育领域的应用最大的阻碍就在于它的幻觉问题,这也是各家教育大模型着重解决的问题。
之前,各家教育科技企业都向多知提到过,通过搜索召回增强技术(RAG),可以比较有效地缓解幻觉问题,这使得大模型能够比较有效应用在实际的产品中去。
RAG可以通俗地理解为在训练的时候先给大模型输入问题的答案,那么大模型就可以检索到正确的答案,会按照指引生成对应上下文进行回答,从而避免胡说八道。
不过,田密告诉多知:“这道题目能做对,还不是因为RAG,这次是因为九章大模型训练了足够多的数据,而且这些数据是我们用AI合成的数据,再来训练AI 。整个解析过程是模拟孩子学习数学的过程,一步步地推导。”
“也就是说,教育科技公司有足够多的、足够专业的数学数据做过训练,这是优势。通用大模型把这道题当成是一个通用的题来处理,而九章大模型知道它是一道数学题,它用数学的方式,一步步来推理,自然能做对,而且整个过程的可解释性很好。”田密进一步向多知解释。
垂类模型的价值在此刻显现了。
相关阅读:
学而思宣布开放三项核心AI能力,CTO田密:教育大模型终极形态是AI老师
深度|对话猿力科技CTO杨元祖:大模型为教育解决方案带来“第三种可能”
万字对话有道四高管:“模型即应用”的时代,到了?
END
本文作者:王上