详细代码:网页链接
泳者,行者,飞者,整个夏季颂扬
诞生,成长,而死去的众生
惑于感官的音乐,全都无视
纪念永生的智慧而立的碑石。
一个老人不过是一件废物,
一件破衣挂在木杖上,
除非灵魂拍掌而歌,愈歌愈激楚,
为了尘衣的每一片破碎;
没有人能教歌,除了去研读
为灵魂的宏伟而竖的石碑;
所以我一直在海上航行,
来到这拜占庭的圣城。
——《驶向拜占庭》节选
叶芝 /诗 余光中 /译
1 特征选择(Feature Selection)
如果我们要设计一份调查问卷,我们可以用不同问题来了解人群各方面的信息:性别,年龄,爱好,星座,生日,收入水平,职业,政治面貌,是否喜欢叶芝的诗,是否支持川普竞选美国总统,等等。
那么,调查问卷应该包含什么信息?这取决于我们需要回答的问题。例如,如果我们想要了解一个人的政治倾向,根据我们的生活经验(先验假设),“收入水平”,“职业”,“政治面貌”,“是否支持川普竞选美国总统”可能是更为关键的信息。
世事纷繁复杂,针对特定的问题,对描述一个事物所需的信息进行筛选几乎是必不可少的过程。从机器学习算法的角度来叙述,在针对特定问题进行建模的时候,我们需要进行特征选择(feature selection)。在上面提到的例子中,我们认为这群人“是否支持川普竞选美国总统”是重要信息,一般称为相关特征(relevant feature),“是否喜欢叶芝的诗”则可能和他们的政治倾向没有太大的关联,称为不相关特征(irrelevant feature)。然而实际情况可能并非如此,一个人是否喜欢叶芝的诗也许和他的政治倾向存在显著关联。而发现这种有悖生活常识和直觉的关联,恰恰正是数据挖掘和机器学习优越之处。在上一篇研究报告中,我们探讨了如何从已有的数据特征维度出发,进行特征工程(feature engineering)来获得新的特征维度,从而加强模型的解释力。在这里,我们开始探讨通过特征工程获得大量的特征维度以后,如何系统地进行特征筛选。基于 scikit-learn 模块提供的方法,和一篇系统讲述特征选择和代码实现的文章,我们尝试在米筐科技公司策略研究平台中实现并测试了一个集成特征选择打分器(Ensemble Feature Grader, EFG)。具体代码实现请参看米筐科技论坛。
2 特征选择的搜索策略
假定我们通过特征工程获得了 30 个特征变量,当我们进行建模时,每个特征变量有两种可能的状态:“保留”和“被剔除”。那么,这组特征维度的状态集合中的元素个数就是
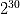 。更一般地,如果我们有 N 个特征变量,则特征变量的状态集合中的元素个数就是
。更一般地,如果我们有 N 个特征变量,则特征变量的状态集合中的元素个数就是 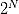 。从算法角度讲,特征选择是一个组合优化问题(combinatorial optimization),通过穷举的方式进行求解的时间复杂度是指数级的 (
。从算法角度讲,特征选择是一个组合优化问题(combinatorial optimization),通过穷举的方式进行求解的时间复杂度是指数级的 (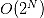 )。当 N 足够大时,特征筛选将会耗费大量的时间和计算资源(图1)。
)。当 N 足够大时,特征筛选将会耗费大量的时间和计算资源(图1)。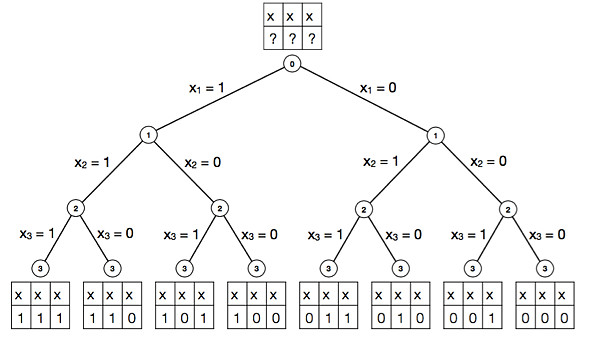
图1:通过穷举法求解特征选择问题的二叉树表示。状态集合中元素的个数随特征变量数目增加而呈现指数增长。
为了减少运算量,目前特征子集的搜索策略大都采用贪心算法(greedy algorithm),其核心思想是在每一步选择中,都采纳当前条件下最好的选择,从而获得组合优化问题的近似最优解。根据其实现的细节,又可将贪心算法分为三种:前向搜索 (forward search),后向搜索(backward search)和双向搜索 (bidirectional search)。
前向搜索的思想是:假定我们有一个特征集合{
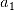 ,
, 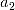 , … ,
, … , 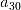 },第一步先从特征变量的集合中选择一个特征变量,构成只有一个元素的特征变量子集。例如依据给定的评价标准,特征a1的效果最优,则子集为{
},第一步先从特征变量的集合中选择一个特征变量,构成只有一个元素的特征变量子集。例如依据给定的评价标准,特征a1的效果最优,则子集为{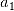 };第二步,则是往已有的子集中加入下一个效果最优的特征变量,例如对于子集{
};第二步,则是往已有的子集中加入下一个效果最优的特征变量,例如对于子集{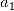 ,
, 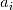 },当 i=2 时效果最优,则新的子集确定为{
},当 i=2 时效果最优,则新的子集确定为{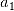 ,
, 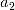 }。如此重复进行搜索,直到新一轮获得的子集效果不如前一轮,则搜索停止。后向搜索的做法,是以包含全部特征的集合开始,逐步剔除特征,直到找到效果最优的子集。双向搜索则把前向搜索和后向搜索结合起来,不断在选定的子集中加入新特征,并同时剔除旧特征。
}。如此重复进行搜索,直到新一轮获得的子集效果不如前一轮,则搜索停止。后向搜索的做法,是以包含全部特征的集合开始,逐步剔除特征,直到找到效果最优的子集。双向搜索则把前向搜索和后向搜索结合起来,不断在选定的子集中加入新特征,并同时剔除旧特征。这三类算法在 R 语言的 stats 包中的线性回归建模中都实现了。Python 的 scikit-learn 模块中提供了一种循环特征剔除 (recursive feature elimination, RFE) 的实现,遵循的也是后向搜索的思路。值得注意的是,在很多中文资料中,都把RFE翻译为”递归特征消除”,然而根据 scikit-learn 模块官方文档的解释,RFE 的计算并非一个递归过程,因此应属于误译。
3 特征选择的子集的评价
一个完整的特征选择包含子集搜索(subset search)和子集评价(subset evaluation)两个步骤。在下面的讨论中,参照 scikit-Learn 模块中 feature_selection 类官方文档中给出的分类方法,我们把将会用到的子集评价标准分为:单变量特征剔除,依据模型的特征剔除和循环特征剔除。
3.1单变量特征剔除(Univariate Feature Elimination)
3.1.1 Pearson 相关系数
Pearson 相关系数是最常用的判断特征和响应变量(response variable)之间的线性关联的标准。在上一篇关于沪深300指数的特征工程和聚类分析中,我们通过计算前一个交易日的特征和这个交易日的对数收益率的 Pearson 相关系数实现了特征选择。Pearson 相关系数的优点在于其计算简单,结果易于理解且易于比较;而其缺点在于不能反映变量之间的非线性关系,而且和线性回归一样,可能出现安斯库姆四重奏(Anscombe's quartet)的问题。
3.1.2 距离相关系数(Distance Correlation Coefficient)
距离相关系数是针对 Pearson 相关系数只能表征线性关系的缺点而提出的。其思想是分别构建特征变量和响应变量的欧氏距离矩阵,并由此计算特征变量和响应变量的距离相关系数(图2)。详细的定义和计算过程可参考维基百科。
距离相关系数能够同时捕捉变量之间的线性和非线性相关(图2)。当距离相关系数为 0,则可断言两个变量相互独立(Pearson 相关系数为 0 不代表变量相互独立)。其缺点是与 Pearson 相关系数相比,其所需的运算量较大,而且取值范围为 [0, 1],无法表征变量之间关联是正相关还是负相关。
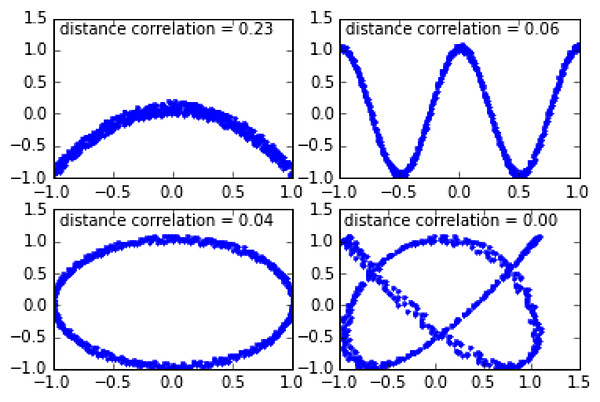
图2:不同的非线性相关下,两个变量的距离相关系数
3.1.3 赤池信息准则(Akaike information criterion, AIC)和贝叶斯信息准则(Bayesian Information Criterions, BIC)
AIC和BIC有相近的数学表达式:
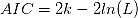
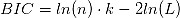
其中
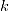 为参数数目,
为参数数目,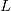 是似然函数(likelihood function),
是似然函数(likelihood function), 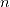 是数据中观测值的数量。
是数据中观测值的数量。AIC 和 BIC 的表达式中均包含了模型复杂度惩罚项(
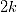 和
和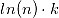 )和和最大似然函数项(
)和和最大似然函数项(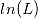 )。不同的地方在于,在 BIC 的表达式中,惩罚项的权重随观测值的增加而增加。因此当观测值数量较大时,只有显著关联的特征变量才会被保留,从而降低模型的复杂性。在 AIC 的维基百科词条中,提到了 AIC 在实践中的效果一般优于 BIC。
)。不同的地方在于,在 BIC 的表达式中,惩罚项的权重随观测值的增加而增加。因此当观测值数量较大时,只有显著关联的特征变量才会被保留,从而降低模型的复杂性。在 AIC 的维基百科词条中,提到了 AIC 在实践中的效果一般优于 BIC。在建模时,我们可以通过最小化 AIC 或 BIC 来选择模型的最优参数。由表达式可以看出,AIC 和 BIC 倾向于复杂度低(
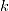 越小越好)和符合先验假设(
越小越好)和符合先验假设(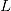 越大越好)的模型。在简单线性回归中,似然函数
越大越好)的模型。在简单线性回归中,似然函数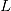 是依据残差服从正态分布的先验假设构建的,即如果特征变量的加入能够使残差更接近正态分布,则认为这个特征能够显著改善线性回归模型。
是依据残差服从正态分布的先验假设构建的,即如果特征变量的加入能够使残差更接近正态分布,则认为这个特征能够显著改善线性回归模型。3.2 依据模型的特征选择(Feature Selection using SelectFromModel)
单变量特征剔除的步骤是先进行特征选择,再利用特征进行建模。而依据模型的特征剔除的思路则是把特征选择和模型结合起来。
在周志华老师的《机器学习》书中的第11章 “特征选择和稀疏学习” 中,把先进行特征选择,再进行建模的方法称为过滤式(filter),此时特征选择的标准和模型优化标准并不一定相同,例如上述的Pearson相关系数和距离相关系数的计算,和下一步将要使用的机器学习算法没有必然联系。而把特征选择和模型优化的标准统一起来的方法则有包裹式(wrapper)和嵌入式(embedding)。包裹式的方法以模型的优化标准作为特征选择的标准,但仍然把特征选择和模型训练分为两个步骤,例如上面提到的 AIC 和 BIC;嵌入式则是把特征选择和模型训练融为一体,不再分为两个步骤,例如以下将要介绍的随机森林算法和基于正则化的线性回归模型。
3.2.1 随机森林(Random Forest)
随机森林算法是把决策树(decision tree)和自助重抽样法(bootstrapping resampling)结合起来的分类或者回归算法。其思想是通过对训练集进行重抽样的方法生成大量的决策树,再把决策树组合起来,从而减少噪音的干扰和过拟合的可能。在 scikit-learn 模块的 ensemble 类中,用随机森林算法进行回归的目标函数是均方差误差函数(Mean Square Error)。
3.2.2 基于正则化的线性回归(Regularization-Based Linear Regression)
在优化理论(optimization theory)中,正则化(regularization)是一类通过对解施加先验约束把不适定问题(ill-posed problem)转化为适定问题的常用技巧。例如,在线性回归模型中,当用最小二乘法估计线性回归的系数
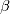 时,如果自变量存在共线性,系数的估计值
时,如果自变量存在共线性,系数的估计值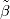 将具有较大的方差,因而会影响后续参数的统计检验。如果在最小二乘法的参数估计表达式中添加L1正则项
将具有较大的方差,因而会影响后续参数的统计检验。如果在最小二乘法的参数估计表达式中添加L1正则项 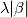 ,则称为Lasso线性回归模型:
,则称为Lasso线性回归模型: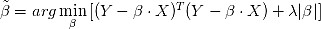
如果添加L2正则项
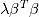 ,则称为岭回归模型(Ridge Regression):
,则称为岭回归模型(Ridge Regression):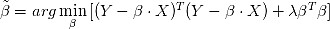
在线性回归的系数估计中,正则化处理在改善问题的适定性的同时,也会使得系数的估计有偏(biased estimation),因此在选择正则化项的权重
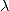 时,一般的原则是在问题足够适定的前提下,
时,一般的原则是在问题足够适定的前提下,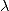 应该尽可能小。在接下来的实现中,我们使用上面提到的AIC和BIC来确定正则化项的权重。另外,L2正则化和L1正则化对解施加的是不同的先验约束:L2正则化会令解出现集中分布的特性,而L1正则化则会令解出现稀疏的特性。在Lasso回归中,因为L1正则化会令部分的系数趋近于0,因此也是一种常用的特征选择方法。
应该尽可能小。在接下来的实现中,我们使用上面提到的AIC和BIC来确定正则化项的权重。另外,L2正则化和L1正则化对解施加的是不同的先验约束:L2正则化会令解出现集中分布的特性,而L1正则化则会令解出现稀疏的特性。在Lasso回归中,因为L1正则化会令部分的系数趋近于0,因此也是一种常用的特征选择方法。尽管L1正则化能够减少系数估计的方差,但利用L1正则化进行特征选择时,其稳定性仍然会受到自变量共线性的影响。例如,在上一篇关于沪深300指数的特征工程的研究报告中,我们提到利用身高,体重两个维度对学生性别进行分类的例子。基于日常生活经验,我们可以预见身高和体重这两个特征变量本身也存在显著的正相关(共线性)。如果先用身高这个维度对学生的性别进行分类,其分类的准确率可能已经达到80%,再利用体重进行下一轮分类,其准确率只提升到85%。在这种情况下,我们可能会得到一个错误的结论:身高这个维度对于区分性别的效果远好于体重这个维度。但实际情况可能并非如此,如果我们改变特征使用的顺序,即先以体重对性别进行分类,得到的分类准确率也可能达到80%甚至更高。
在统计学中,我们通常把这类和自变量和响应变量均存在显著相关性的变量称为混淆变量(confounding variable)。在Lasso回归中,如果存在自变量共线性的问题,则哪一个特征维度被剔除将取决于特征选择子集构建的顺序,从而造成特征选择结果的不确定性。
为了减少 Lasso 回归中特征选择顺序的影响,Python的 scikit-learn 模块 linear_model类 中提供了一个 RandomizedLasso 类。其思路是对训练集的数据进行多次重抽样,从而得到一系列特征选择的子集,再对子集中各个特征变量出现的频率进行统计,剔除掉出现频率低的特征变量。然而在实际测试中,在调用该类的成员函数fit( )时会显示 “This function is deprecated” 的错误信息,其官方文档中亦未对其作出说明。
3.3 循环特征剔除(Recursive Feature Elimination, RFE)
如上所述,循环特征剔除遵循的是贪婪算法中的后向搜索的策略,在每一步选择最优结果,从而逐步剔除不相关特征。在基于 scikit-learn 模块的实现中,我们需要给出最优结果的评估方法(estimator),在下面的实现中,我们将用简单线性回归作为评估方法,来测试其效果。
3.4 集成特征打分器(Ensemble Feature Grader, EFG)
回顾我们以上的讨论,特征选择的本质上是求解一个计算量随特征变量个数呈指数增长的组合优化问题。基于不同的子集搜索和评价标准,不同的方法给出的都只是一个近似最优解,而解的合理性也将受方法本身的局限性所影响。在真实的数据分析中,如果我们通过特征工程产生大量的特征变量,数据集中包含噪音,共线性,非线性相关等情况的问题将难于避免。因此,为了系统化地进行特征选择,获得更为合理的相关特征变量子集,在这里我们借鉴机器学习里面的集成学习(ensemble learning)的思想,提出一个集成特征打分器(以下称EFG)。其主要思路是,根据以上特征选择的方法对特征进行打分(分数的取值范围为0到1),观察特征变量在不同方法下的得分,进而计算其总得分,以尽量减少数据和单一特征选择方法引起的问题,并改善特征选择的效果。
4 基于 scikit-learn 模块的 EFG 实现和测试
在这里,我们选取八个方法来对特征进行打分:Pearson 相关系数,距离相关系数,简单线性回归,基于 AIC 的 Lasso 回归,基于 BIC 的 Lasso 回归,随机森林(以下称 RF),循环特征剔除(以下称 RFE)和岭回归。其中,scikit-learn 模块并未提供距离相关系数计算。我们通过 Github 上的一份源代码对其进行了实现。
为了保证特征在各个特征选择方法中得分在 0 到 1 之间,我们需要对各个方法给出的特征的得分作归一化处理。对于循环特征剔除,这里我们选用简单线性回归作为它的估计方法,由于其给出的是特征重要性的排序,在这里我们把前五个最重要的特征定为 1 分,而其他特征的得分在 0 到 1 之间均匀分布。
在这里,我们选取 Frideman 训练集对 EFG 进行测试。这个训练集中包含非线性相关项,噪音项,权重不同的线性相关项和引起多重共线性的项,基本上囊括了实际数据处理中可能出现的主要问题,因此适合于 EFG 的测试。测试的结果和分析可参看附录1。
5 基于 EFG 的沪深300指数特征选择
我们因循前一篇沪深300指数的特征工程和聚类分析报告的思路,继续尝试对收盘-收盘对数收益率
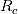 (close-to-close logarithmic return rate)进行聚类分析。除了上一份研究报告中使用的 11 个特征变量,我们通过特征工程进一步获得 49 个新的特征变量(附录2),因此共有 60 个特征变量。接下来我们对这 60 个特征变量进行特征选择。
(close-to-close logarithmic return rate)进行聚类分析。除了上一份研究报告中使用的 11 个特征变量,我们通过特征工程进一步获得 49 个新的特征变量(附录2),因此共有 60 个特征变量。接下来我们对这 60 个特征变量进行特征选择。在 EFG 中我们使用了数个线性回归或基于线性回归的特征选择方法,由于线性回归要求因变量 Y 近似服从正态分布,我们先通过分位数-分位数图(quantile-quantile plot, QQ Plot)图观察
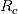 的分布,确认其大致符合正态分布(R=0.9538),且存在一定的集中分布特征(图3)。
的分布,确认其大致符合正态分布(R=0.9538),且存在一定的集中分布特征(图3)。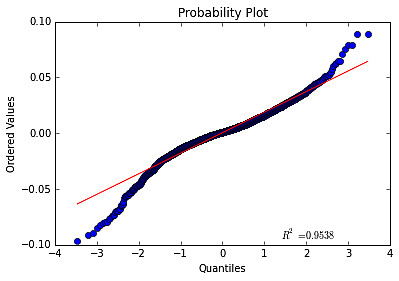
图3:
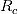 的分位数-分位数图
的分位数-分位数图在EFG测试中,我们以得分高于0.35为标准,选取了14个特征变量进行聚类分析(附录3)。依照上一篇研究报告的分析方法,我们计算了两个聚类对应的均值和标准差(表1),并和上一篇报告的结果进行了对比(表2)。结果表明两个聚类的均值差值增加,聚类区分度提高,且聚类1的标准差增加的同时聚类2的标准差减少,说明一部分波动率较大的交易日被归为聚类1。
接下来我们用新的聚类结果计算上一篇报告提出的基准择时策略的累计收益率(图4)。和由上一次的聚类结果得到的累计收益率相比(图5),2007年和2015年大幅上涨的交易日由聚类2进入了聚类1,使得聚类1对应的累计收益率上升。综上,通过进一步的特征工程和特征选择,我们有效地提升了聚类分析的建模效果。
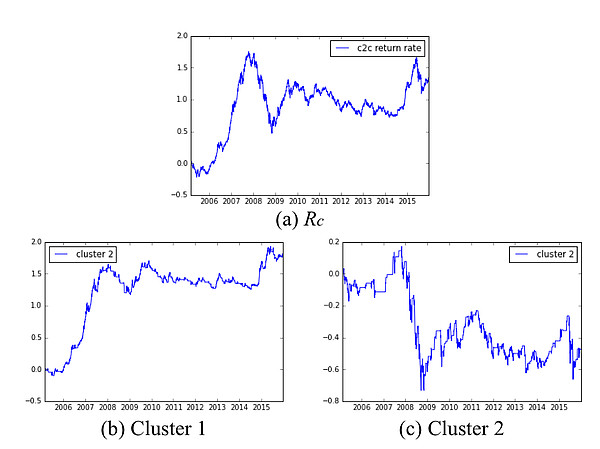
图4:使用EFG进行特征选择后累积收益率曲线计算:(a)沪深300指数;(b) 在聚类1包含的交易日进行交易;(c) 在聚类2包含的交易日进行交易
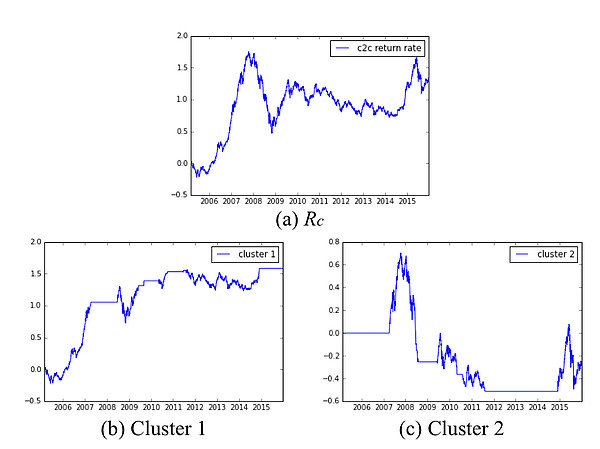
图5:使用 Pearson 相关系数进行特征选择后累积收益率曲线计算:(a)沪深300指数;(b) 在聚类1包含的交易日进行交易;(c) 在聚类2包含的交易日进行交易
6 总结和讨论
特征工程和特征选择是大部分机器学习算法建模前重要的预处理步骤。特征工程和特征选择对于分析结果的影响,往往比之后的机器学习模型的选择更为重要。在这里我们强调了特征选择本质上是一个复杂的组合优化为问题,讨论了各种特征选择方法的特点和局限性,并提出了一个集成特征选择打分器,尝试减少数据的缺陷和方法的局限性给分析结果带来的负面影响。
在这两份报告中我们大致描述了一个实现特征工程和特征选择的框架,可以一定程度上实现这两个步骤的自动化处理。但它仅仅是我们进行数据处理和建模的辅助,而不能代替我们对问题进行分析和思考。首先,如果在进行分析时没有准确,全面地理解数据和方法,我们将有可能错误地理解分析结果。例如,在附录1我们分析 EFG 在 Friedman 训练集测试的结果时,发现简单线性回归方法对非线性相关项给出比线性相关项更高的打分,但这并非是因为简单线性回归能够有效识别非线性相关,而是因为自变量的多重共线性引起了系数估计的不稳定性。其次,如果我们不加思考地通过特征工程获得大量的特征,再分析其和相应变量的关联,将有可能出现多重比较谬误(multiple comparisons fallacy),这种因为大量两两比较而出现的统计学上的伪关系(spurious relationship)将会导致我们对问题作出错误的分析和预测。要减少伪关系的干扰,除了一些通用的统计学处理方法外,一是分析时使用尽量多的样本(回测足够长的时间),同时我们要应当仔细推敲建模所采用的特征变量所对应的的经济学涵义。
7 致谢
本篇研究报告的主要思路和代码框架均来自于:
网页链接
相关系数矩阵源代码来源于:
网页链接
特征选择方法的分类部分借鉴了周志华老师的《机器学习》的观点,在此一并致谢。
附录1:EFG 在 Friedman 训练集上的测试
我们按以下方式生成 14 组的随机特征变量,每组有750个观测值的 Friedman 训练集:
(1) 生成 10 组服从 [0, 1] 之间均匀分布的随机变量
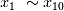 :
:(2) 按如下的Friedman函数生成响应变量
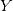 :
: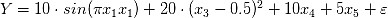
(3) 再定义变换:
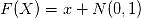
把
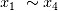 作为输入,生成和
作为输入,生成和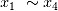 存在显著相关,又包含高斯白噪音的另外四个随机向量 。在这14组随机变量中,
存在显著相关,又包含高斯白噪音的另外四个随机向量 。在这14组随机变量中,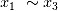 为非线性项,
为非线性项,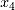 和
和 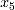 为权重不同的线性项,
为权重不同的线性项,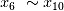 为噪音项,
为噪音项,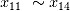 为引起多重共线性项。使用EFG对这个训练集进行计算得到表3:
为引起多重共线性项。使用EFG对这个训练集进行计算得到表3: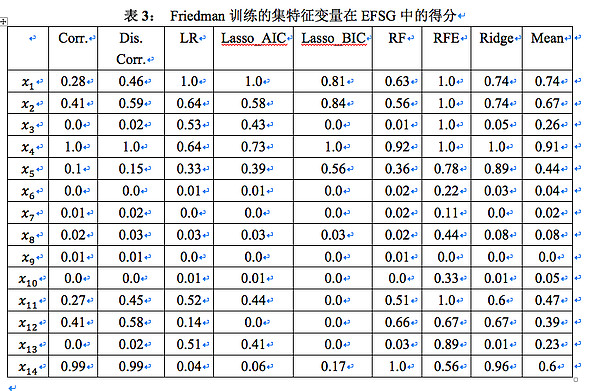
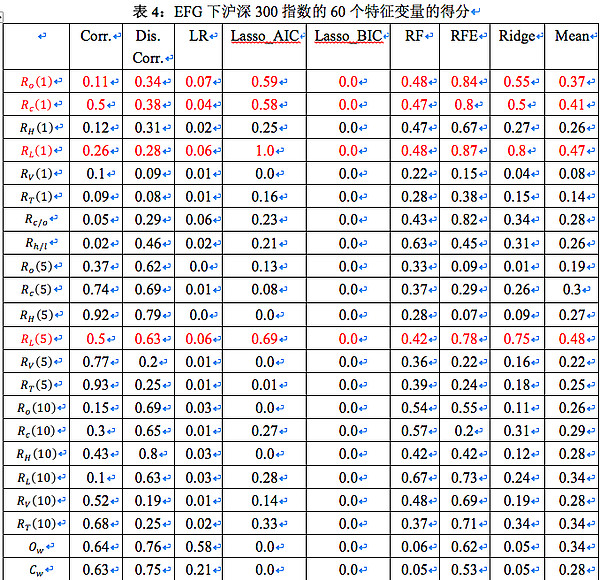
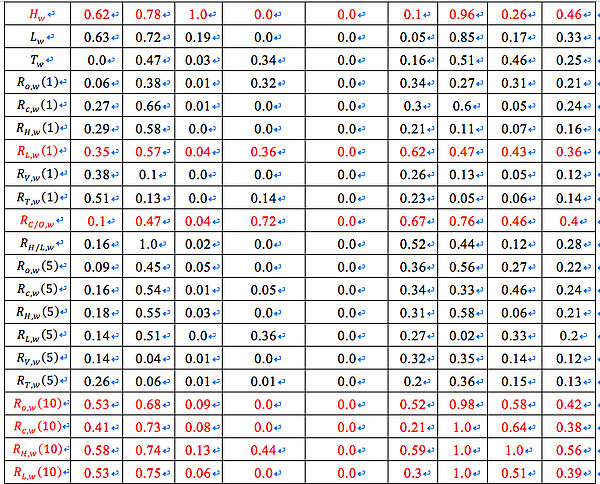
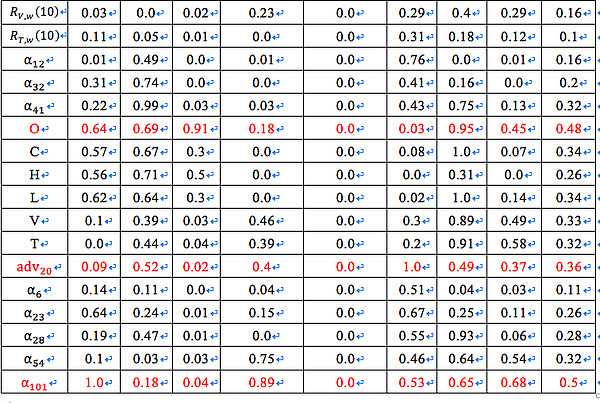
备注:Corr. 表示 Pearson 相关系数,Dis. Corr. 表示距离相关系数,LR 表示线性回归,Lasso_AIC 表示基于AIC的 Lasso 回归,Lasso_BIC 表示基于 BIC 的 Lasso 回归,RF 表示随机森林,RFE 表示循环特征剔除,Ridge 代表岭回归,最后一列为变量在所有方法中得分的均值。
首先对噪音项
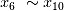 得分进行分析。在EFG中,这5个随机变量的得分均值明显低于其它特征变量,说明EFG能够有效识别出噪音项。另外,如果观察它们在每一个方法中的打分,其主要得分来源是RFE方法,而且和
得分进行分析。在EFG中,这5个随机变量的得分均值明显低于其它特征变量,说明EFG能够有效识别出噪音项。另外,如果观察它们在每一个方法中的打分,其主要得分来源是RFE方法,而且和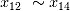 的得分接近,说明基于简单线性回归的RFE虽然能够有效识别出最重要的几个特征变量,但对于次要的特征变量和噪音项的分辨能力不强。
的得分接近,说明基于简单线性回归的RFE虽然能够有效识别出最重要的几个特征变量,但对于次要的特征变量和噪音项的分辨能力不强。然后对生成因变量随机变量
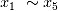 和
和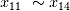 进行分析。
进行分析。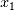 ,
,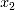 ,
,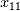 和
和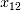 在距离相关系数的计算中得分较高,证明了距离相关系数对于某些变量之间非线性相关的识别能力。对于非线性项
在距离相关系数的计算中得分较高,证明了距离相关系数对于某些变量之间非线性相关的识别能力。对于非线性项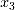 和
和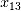 ,它们在相关系数和计算中得分为0,符合相关系数无法表征变量之间非线性相关的特性;而在简单线性回归和基于简单线性回归的RFE中得分较高。然而,这并不说明简单线性回归能够识别非线性相关。其得分较高的原因是因为自变量存在多重共线性(
,它们在相关系数和计算中得分为0,符合相关系数无法表征变量之间非线性相关的特性;而在简单线性回归和基于简单线性回归的RFE中得分较高。然而,这并不说明简单线性回归能够识别非线性相关。其得分较高的原因是因为自变量存在多重共线性(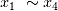 和
和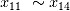 )。,因而造成参数估计的不稳定。另外两个正则化处理的线性回归方法(基于BIC的Lasso和岭回归)均对
)。,因而造成参数估计的不稳定。另外两个正则化处理的线性回归方法(基于BIC的Lasso和岭回归)均对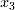 和
和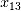 给出了较低的分数。
给出了较低的分数。总结来说,在这八个方法里面,线性回归和基于简单线性回归的RFE由于受到多重共线性的干扰,其表现较差;基于AIC的Lasso回归同样表现一般:它既未能对权重最高的线性相关项
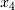 给出最高得分,同时也对等价的特征变量
给出最高得分,同时也对等价的特征变量 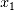 和
和 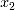 也给出了差别较大的打分。而基于BIC的Lasso回归对于特征关联强度较为严苛,它对大部分的特征变量都给出了零分。
也给出了差别较大的打分。而基于BIC的Lasso回归对于特征关联强度较为严苛,它对大部分的特征变量都给出了零分。最后,各个方法得分均值较为符合我们的期望:相应变量Y中权重最高的线性项(
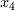 和
和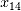 )得分最高(0.84),权重较高的非线性项和权重较低的线性项次之(
)得分最高(0.84),权重较高的非线性项和权重较低的线性项次之(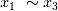 ,
,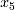 和
和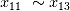 ),等价的非线性相关项得分接近(
),等价的非线性相关项得分接近(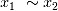 和
和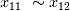 ),噪音项低分最低(
),噪音项低分最低(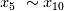 )。因此,可以说EFG在 Frideman 训练集中的表现令人满意。
)。因此,可以说EFG在 Frideman 训练集中的表现令人满意。附录2:沪深300指数的特征工程
在上一篇报告中,我们使用了以下 12 个特征变量:
(1)6个基本变量:开盘价(open),收盘价(close),日内最高价(high),日内最低价(low),成交量(volume),转手率(turnover)。
(2)1个衍生变量:adv(20)
(3)5个阿尔法变量:alpha#6,alpha# 23,alpha#28,alpha# 54,alpha#101
除这12个特征变量外,在下面的分析中,我们增加以下的特征变量:
除这12个特征变量外,在下面的分析中,我们增加以下的特征变量:
(1) 我们定义 变量 在前 个交易日的变化率:
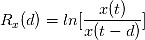
备注:对一个随机序列的前后两项的比取对数,来近似其变化率是常用的数学技巧。对上面的对数函数表达式作泰勒展开,可看出其为变化率的一阶近似。
 为以上的6个基本变量。我们计算前1个,5个和10个交易日的变化率,共得到18个特征变量。在下面的分析中,我们将用这些变量的英文首字母作为下标,例如,
为以上的6个基本变量。我们计算前1个,5个和10个交易日的变化率,共得到18个特征变量。在下面的分析中,我们将用这些变量的英文首字母作为下标,例如,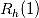 即代表日内最高价(high)在前1个交易日的变化率。
即代表日内最高价(high)在前1个交易日的变化率。(2) 前一个交易日内最高价和日内最低价比的对数:
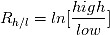
(3) 前一个交易日内收盘价和开盘价比的对数:
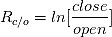
由以上(1),(2) ,(3) 我们得到20个新的特征变量,我们对这20个新特征变量和基本变量中除交易量外的5个变量继续进行特征工程:以交易量为权重,对这些变量的前5个交易日计算其加权平均值,再得到25个新的特征变量。我们对标量添加下标w来表示其为加权平均变量,例如,
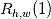 即 代表日内最高价(high)在前1个交易日的加权平均变化率。
即 代表日内最高价(high)在前1个交易日的加权平均变化率。按照《101 Formulaic Alphas》报告中 WorldQuant LLC 给出的阿尔法表达式 alpha # 12,alpha #32 和 alpha # 41 生成 3 个特征变量。
由此我们共得到 48 个新的特征变量,再加上原来的 12 个特征变量,共得到 60 个特征变量。
附录3:沪深300指数的特征变量在 EFG 中的得分
表4为沪深300指数的60歌特征变量的在EFG得分。值得注意的是,基于 BIC 的 Lasso 回归对所有的特征变量均给出了 0 分。其原因是是在 2647 个观测值的情况下,BIC 表达式中的惩罚项权重较高,我们选用的特征变量均未被认为能显著改善回归结果。红色部分为得分均值高于0.35,用于聚类分析的特征变量。
$乐视网(SZ300104)$ $黄河旋风(SH600172)$
@Stevevai1983 @今日话题 @刘轶南老师 @量化钢铁侠 @银行螺丝钉 @编程浪子 @Tess@量化小王子 @GT周 @非典型伪价值投机@骑行夜幕的统计客 @张翼轸