10倍英伟达GPU:大模型专用芯片一夜成名,来自谷歌TPU创业团队!
能带来完全不同的大模型体验。
我们知道,大模型到 GPT-3.5 这种千亿体量以后,训练和推理的算力就不是普通创业公司所能承担的了,人们用起来速度也会很慢。
但自本周起,这种观念已成为历史。
有名为 Groq 的初创公司开发出一种机器学习处理器,据称在大语言模型任务上彻底击败了 GPU—— 比英伟达的 GPU 快 10 倍,而成本仅为 GPU 的 10%,只需要十分之一的电力。
这是在 Groq 上运行 Llama 2 的速度:
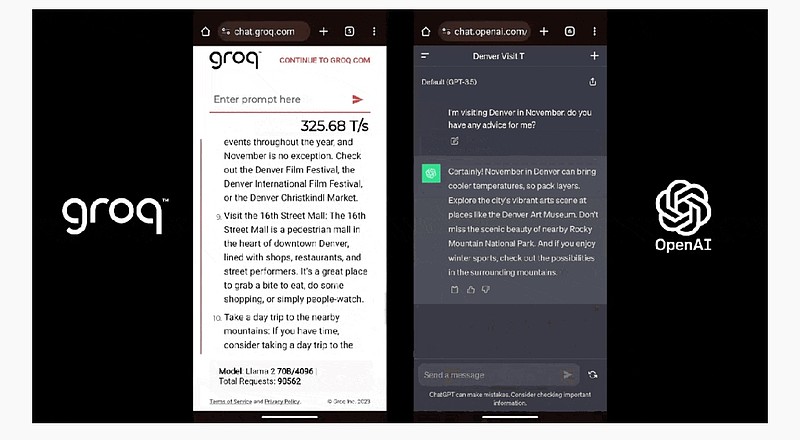
这是 Groq(Llama 2)和 ChatGPT 面对同一个 prompt 的表现:
Groq 的处理器名为 LPU(语言处理单元),是一种新型的端到端处理单元系统,可以为具备序列组件的计算密集型应用(比如 LLM)提供极快的推理速度。
它带动的大模型速度能达到前所未有的 500 Token/s,并且实现了极低的延迟。
2024年2月20日,由谷歌TPU第一代设计者Jonathan Ross所创立的Groq公司正式宣布:
新一代LPU(Language Processing Unit),以API形式提供先进的MOE 开源大语言模型 Mistral 8X 7B 的推理,并在多个公开测试中,以几乎最低的价格,相比GPU推理速度翻倍。
天风研究所的判断:
我们在此前2024年9大科技判断即认为“AlphaGo(Self play、Synthetic Data)+LLM重塑大模型架构。计算/成本的最大瓶颈或许不再是内存墙。”
Groq的本质即为减少计算中内存调用次数,实现Scale Out,从而实现推理效率的突破。
Groq ASIC芯片在推理端的架构优势进一步显现:
根据Groq官网白皮文档,Groq LPU的先进源于其设计理念的独立,部分放弃卷积的设计,专注于矩阵X向量 、 矩阵X矩阵计算。芯片的核心是矩阵乘法单元,矩阵引擎通过具有320个元素的向量进行操作。浮点运算中一对字节平面(byte planes)协作产生一个FP16的输出。 芯片的中间是矢量执行模块(VXM,vector execution module)。
Groq ASIC芯片通过放弃灵活性和训练性能获得推理性能大幅提升:
其对大模型的定制化编译,大幅提升推理速度, LPU 运行编译后的LLM代码,执行生成AI推理应用程序。编译器提供可预测的工作负载性能和计时。
ASIC芯片在成本优势主要体现在内存:
根据Groq创始人采访,与GPU不同,LPU只有一个核心,创始人称之为TISC或时间指令集计算机体系结构。它不需要像GPU那样频繁地从内存重新加载。因此采用SRAM而非昂贵的HBM。目前Groq API推理Mistral的定价低于其它32K 上下文长度GPU 定价。
更多芯片互联势必带来网络架构进一步升级:
根据Groq官网白皮书,Groq采用蜻蜓拓扑来完全连接机架内的八个全局节点集,系统中可连接多达145个机架,从而实现超过10000 TSP的总可扩展性,势必带来光模块用量的持续提升。
边缘推理成本时延有望进一步突破,应用有望快速爆发:
我们认为相比HBM,SRAM设计下的ASIC芯片有望在边缘端实现更低成本下的快速,灵活的推理,在语音交互,图片和视频生成等场景逐步提供与用户需求匹配的体验,从而带动AI应用进一步快速渗透与迭代。
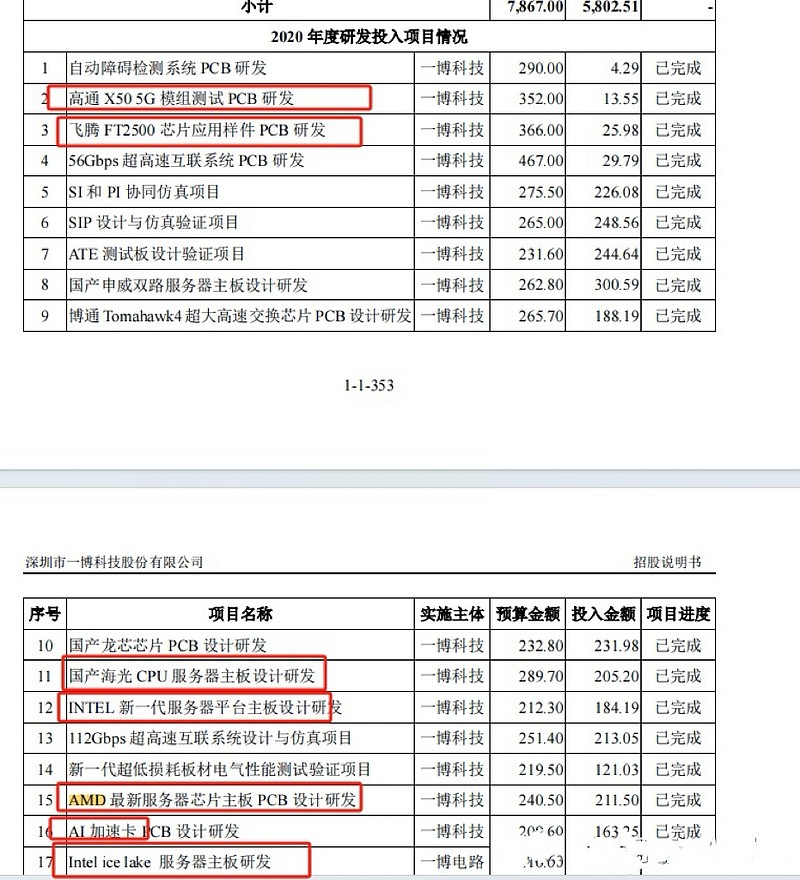
最纯正的标的一博科技(301366):
公司已与Intel、AMD、Marvell等国际知名芯片公司保持十余年的长期合作,对芯片测试验证的PCB设计、仿真分析及生产验证积累了丰富的经验。公司亦为飞腾、申威、龙芯、海思等国产芯片公司的研发提供技术服务。