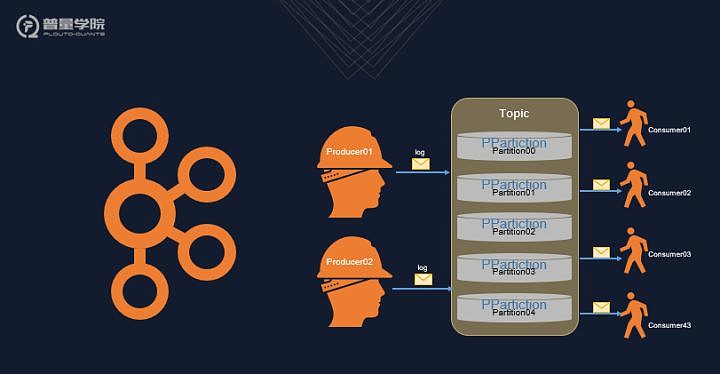
本次我们分享的内容是基于消息系统的分布式量化交易系统,主要是讲Kafka的实际应用。Kafka是一个分布式的发布-订阅消息系统,它最初由LinkedIn开发,开源之后,不久成为Apache的顶级项目,现在众多大型平台都在使用,比如阿里云就提供基于Kafka的消息中间件服务。这张图就是Kafka的一个基本场景,最左端是Producer,也就是生产者,多个生产可以生成统一类别的消息,在Kafka的术语里,消息又被称为log。所谓同一类别,也就是同一个topic。从图上可以看出,一个Topic可以分为多个partition,这些partition可以在一台主机上,也可以在分布在多台主机上,这些多台主机之间的同步由zookeeper来保证。图上最右侧就是多个consumer,也即是说同一个topic,可以被多个consumer订阅。每一个consumer都会在kafka服务器注册,Kafka服务器会维持每一个consumer已经消耗的消息的偏移量。因此Kafka可以完全保证,每一个consumer都可以按照时序消费所有消息。对Kafka的基本概念和使用方法,不是特别了解的同学,可以参考我们的其他课程,或者参阅官方文档。我们这次课,主要是和各位同学分享Kafka在量化交易系统中的所发挥的重要作用。
一 场景:行情数据分发
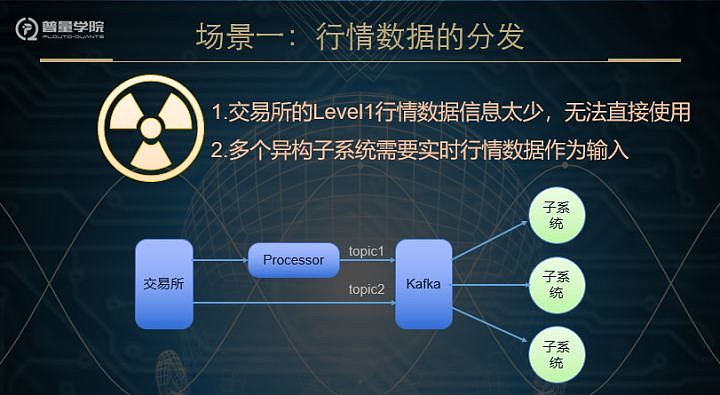
我们面临的第一个问题就是行情数据的处理,行情数据是量化交易系统最基本的输入数据,但是,从交易所过来的Level1并不能直接使用,是因为它里面包含的信息太少,只有当前这个时刻的高、开、低、最新价、成交量、成交额、买五和卖五等。大家可以去上交所和深交所的网站上查看官方文档,里面有详细的介绍。所以我们首先要对这些原始行情数据进行处理,比如聚合为分钟线。第二个要解决的问题,普量云的量化交易系统里面包含了很多子系统,这些子系统也需要行情数据作为输入。看到这些问题,有些同学,肯定立即又想到了,利用数据库作为数据的中转站。的确,刚开始我们也是这样使用的,可是很快就出现了瓶颈,对数据库的压力太大。Level1的行情数据是每3秒更新一次,算上指数,大概有6000多条记录,再加上不同系统的同时读写,可想而知,对数据库造成的压力有多大。其实,那么这种场景就是Kafka最基本的应用场景。(出图)交易所过来的数据,作为一个topic直接进入Kafka,经过Processor处理的数据,作为另外一个topic进入Kakfa。那么各个子系统,就可以根据需求订阅topic1、topic2,或者二者都有。通过这种改造以后,延迟降到了毫秒级别。
二 场景:模拟盘数据流
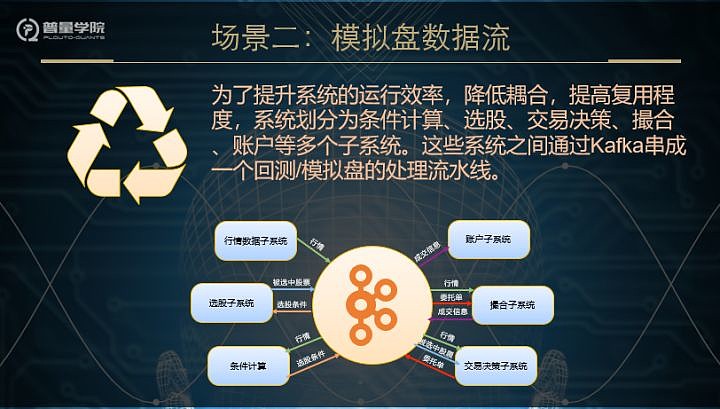
量化的交易过程一般包括了条件计算、选股、交易决策、撮合等多个步骤,因此如果只是做实验,可能只需要一个脚本既可以全部包括了。而普量云是将这些功能封装为不同的子系统,从而提高策略验证的运行效率,也降低了耦合。那么这些系统之间的数据交换就是一个需要解决的问题。一种可选方式就是每个子系统提供一套API,供相关系统调用,这很符合微服务的设计理念。可是这样无疑会增加很多和子系统核心功能无关的开发工作,也加重了后期维护的代价。另外一种可选的方式,当然还是数据库,在回测或者模拟盘运行过程中,系统之间的数据交换十分频繁,数据量也比较大。另外,随着回测的次数的增多,那么数据库就会急剧膨胀。至此,无需再深入分析,数据库似乎不太现实。因此我们还是考虑使用Kafka作为数据流转的中枢。
三 场景:任务触发器
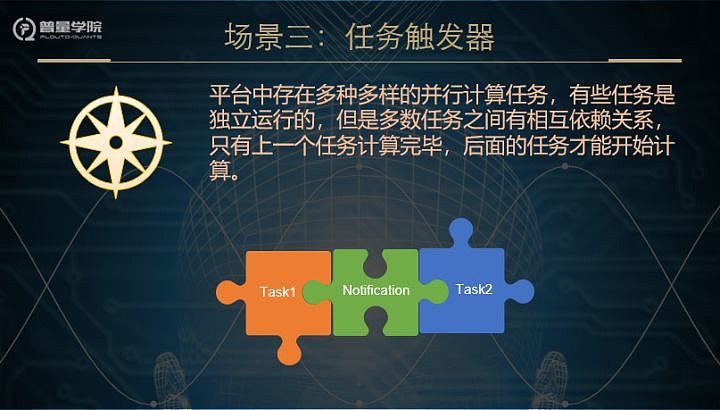
分布式的量化交易系统中可能包含了上百个不同的计算任务。这些任务有些独立运行的,有些是有相互依赖关系的。一个任务只有它依赖的任务计算完,这个任务才能执行。一种解决方案就是把任务的运行状态写入数据库中,后执行的任务就不断的轮询它依赖的任务的状态,直到前面的任务执行完毕。可是,这种做法很显然效率极低,因此还是用Kafka作为任务的触发器。例如,Task1计算完后,就会发送一个notification到Kafka,Kafka就把订阅了这些notification的任务,比如task2,task2收到这个通知后,就开始计算。
上面就是Kafka在普量云中三种典型运用场景。在使用的过程,我们也遇到了不少问题,我相信其他同学也可能会遇到这些问题,那么我们就来看这些问题。
 第一个问题,说起来似乎有点不可思议,或者阴沟里翻船的感觉,就是Kafka的服务器和客户端版本不一致的问题。如果版本不一致,就会导致客户端连不上服务器。解决问题的方法十分简单,就是让客户端和服务器端的版本保持一致。那么为什么会有这个问题?主要是因为,普量云系统中包含了不同语言的子系统,比如Java、Python、Node等,因此一定要注意这些语言的驱动程序的版本。
第一个问题,说起来似乎有点不可思议,或者阴沟里翻船的感觉,就是Kafka的服务器和客户端版本不一致的问题。如果版本不一致,就会导致客户端连不上服务器。解决问题的方法十分简单,就是让客户端和服务器端的版本保持一致。那么为什么会有这个问题?主要是因为,普量云系统中包含了不同语言的子系统,比如Java、Python、Node等,因此一定要注意这些语言的驱动程序的版本。第二个问题,就是磁盘空间耗尽。为什么会出现这个问题呢?因为Kafka对消息做了持久化,Producer发送到服务器的消息都会被保存到磁盘上。这种做法的优点十分明显,如果某个Consumer临时关闭,这个Consumer重启后,Kafka服务器就会从这个Consumer关闭时所消费的消息的Offset开始发送消息。可是随着Topic的增多,Kafka持久化的数据就会越来越多,磁盘空间可能会很快被占满。解决的办法,就是设置topic的rentention时间或者大小。设置时,要考虑不同Topic的使用方式。比如对实时行情,可能只需要保留一天,那就可以设为24小时。
第三个问题,就是offset回跳。什么意思呢?就是有些消息会被反复消费,并且offset不再向前移动。在消费者端时检测消息的offset是否在上条消息之后,如果不是就强制设置offset。
好了,今天的内容就介绍到这里,希望今天的内容对你有所帮助!