Python因为有GIL锁,多线程一直被诟病。在CPU密集型的任务场景中Python的多线程并不是很理想,而对于像网络爬虫这样的IO密集型任务场景,Python的多线程可以在一定程度上提高任务的并行度。下面我们详细说一下:
一、原理
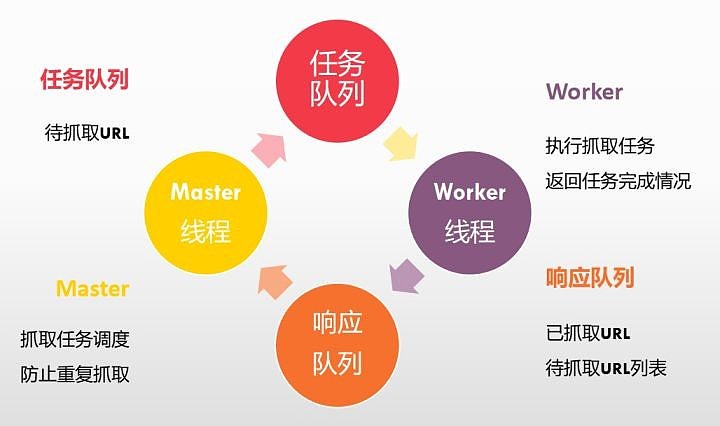
主线程负责任务调度,在初始化时,加载待抓取的URL,可以从文件或者数据库中读取。把待抓取的URL放入任务队列,然后检查响应队列的返回结果。如果有返回结果,会保存已抓取的URL。为了防止重复抓取,这里会对比待抓取的URL与已抓取URL,只把未抓取过的URL放入到任务队列中。
子线程负责执行抓取任务,并返回当前执行任务的URL,还有通过该URL,获取的信息,也就是下一步要抓取的URL列表。解释一下,如果当前任务是需要抓取公告列表页A,执行抓取结果中,抓取到了两个公告页B和C的URL,那么返回的抓取结果,不仅包含A的URL,同时包含B和C的URL。
二、代码实现

解释一下:
master线程的run方法中,第一眼看它是个死循环,实际上它的意思是:我们从response_queue中,拿不到任务响应的时候,会抛出异常,退出循环体。拿到响应以后,调用filter方法,filter的参数是ResponseItem对象,ResponseItem中包含已抓取URL,这个方法有两个作用:第一个是保存已抓取链接,第二个是去掉待抓取链接中重复的链接。

三、总结一下
简单的说,主线程负责任务调度,从响应队列获取任务执行结果, 往任务队列加入新的任务,子线程负责抓取任务。从任务队列获取任务,执行完成后返回结果,存放到响应队列。
好了,今天的内容就介绍到这里,希望今天的内容对你所帮助!