AI浪潮滚滚向前,众生皆被裹挟。
今年6月,Meta更新了隐私权政策。根据新版隐私权政策,用户必须同意将自己发布的内容给Meta的AI模型训练,否则将被禁止使用Facebook和Ins等产品。
这个政策彻底点燃了艺术家们的反AI情绪。他们纷纷离开Ins,“逃亡”到一个叫Cara的地方。
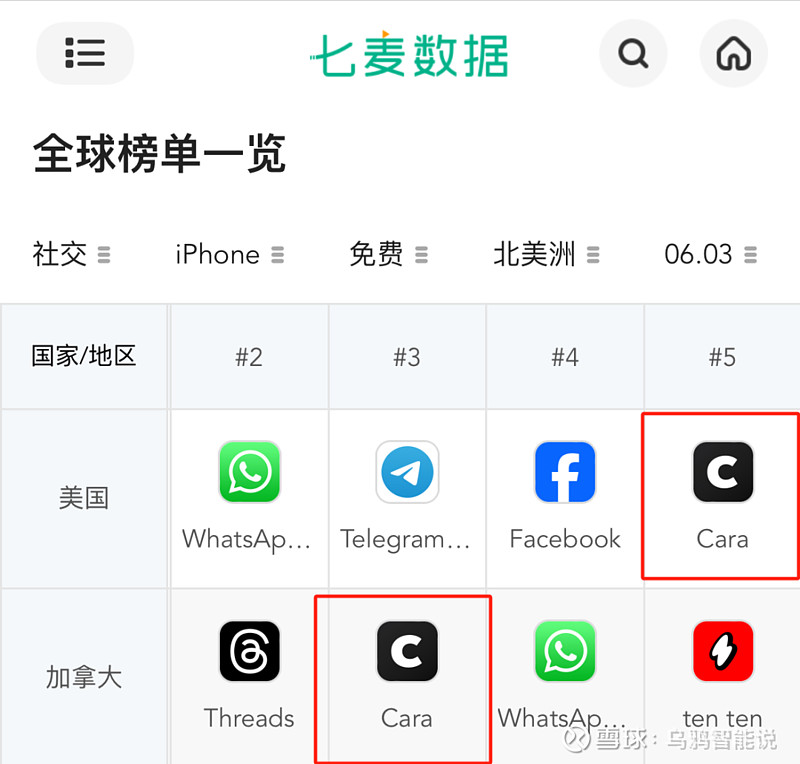
从6月1日到6月9日,在未进行任何广告投放的情况下,Cara用户量就从4万增至80万,一跃成为美国社交应用榜Top5,超过了X、Reddit、Discord等,一时间风头无两。要知道,Ins平均每周的增长用户约为135万,这意味着Cara的增量已经接近Ins的60%。
艺术家们之所以看重Cara,就是因为这个平台足够“反AI”:Cara不允许用户发布AI生成的图像,也不允许科技公司随意收集平台的信息,还会给艺术家们提供“反AI”的保护工具。
从Ins到Cara,并不是一次普通的平台间用户迁移,这背后反映了AI时代平台与用户之间的矛盾正在加剧:
当数据越来越值钱,用户正在试图从平台手中重新拿回数据控制权。
/ 01 / 给AI“下毒”,反AI平台Cara火了
在艺术领域,艺术家与AI的矛盾由来已久。2022年,MidJourney在美国科罗拉多州博览会艺术比赛中凭借AI画作拿下第一名。
自那一刻起,在很多人眼里,艺术失守几乎只是时间问题。抢饭碗就算了,毕竟艺术家管不着。但现在AI公司们变本加厉了。
今年6月,Meta更新了隐私权政策。根据新版隐私权政策,除了用户与好友之间的私密消息内容外,其他数据及衍生数据均会被用于模型训练。这是通知,不是商量,用户没有手动勾选其他选项的可能。
这下艺术家真的怒了。饭碗都要没了,平台还要拿我辛辛苦苦创作的成果去训练AI,这谁能答应?
6月11日,普利策奖得主、摄影记者丹尼尔·埃特(Daniel Etter)发布了一则题为“选择退出——致Meta的公开信”的公告,强烈反对Meta公司使用旗下平台上的公开照片来训练其人工智能产品。截至目前,已有超过200位摄影师、摄影机构和编辑签署了这封公开信。
离开Meta后,他们很快找到了一个没有AI的地方——Cara。在很短的时间内,大量用户纷纷涌入Cara。除了移动端下载量暴涨,网站流量也出现剧增。据similarweb数据,6月前Cara的网站访问量屈指可数,到了6月猛增到了920万。
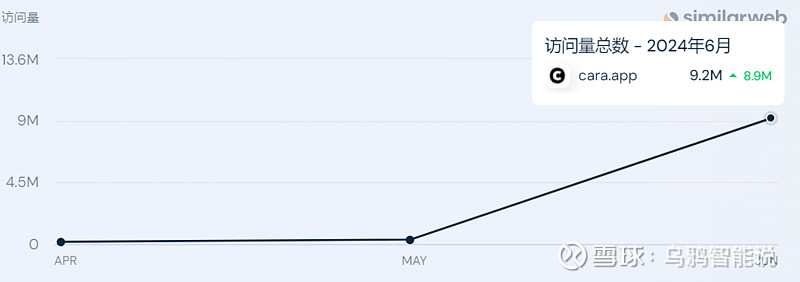
▲Cara的网站访问数据,来源:similarweb
据七麦数据,Cara在5月27日之前还未进入应用任何榜单。到了6月3号,Cara已经进入了各国社交应用榜前五:在美国排名第5,在英国、澳大利亚、新西兰、挪威、瑞典排名第4,在西班牙、加拿大排名第3。
Cara吸引艺术家的原因也很简单,就是在身上打满“反AI”标签。平台不仅专注于建立非AI图片的社区,同时承诺不会将用户内容用于AI训练。
Cara创始人Jingna Zhang(张晶娜)本身就是一名艺术创意从业者兼摄影师,对版权保护的立场坚定,曾参与多起作品维权,其中包括面向Stable Diffusion、Google以及其他AI生图工具的集体诉讼。
更重要的是,Cara还会给艺术家们提供“反AI”的保护工具。
当艺术家在Cara平台发布作品时,Ta可以勾选“我要保护这张图”,网站会给作品“上一层釉”,而这个操作并不会影响画作的肉眼效果。而这道工序背后暗含着Cara的一个秘密武器——Glaze技术。

▲在Cara“上釉”前后的图片对比,来源:Jingna Zhang
Glaze通过向图像添加不可见的噪声来保护艺术家,使AI系统感知到与原始风格不同的风格,从而防止AI模仿艺术家的独特风格。比如,Glaze会对梵高的画作进行微调,导致AI模型无法准确学习梵高的绘画风格,从而实现对原作艺术风格的保护。
这样的保护机制之所以成立,原因是人类与AI看画的方式很不一样。
人类通常是通过观察线条、色彩等视觉元素来感知艺术作品,而AI是基于纯数学的方式进行分析。人类在观看时不会关注到每一个像素的细节,但计算机会读取每个像素。即使是肉眼看来微小的改动,也可能对AI的理解造成显著影响。
根据Glaze技术团队的说法,科技公司要去除Glaze的效果非常困难,这个过程的难度相当于,毒药已经在一杯水里溶解,现在你要把毒性从这杯毒水里完全去除。
固然,Cara能够用魔法打败魔法,但依然解决不了根本问题:在AI时代,用户数据的控制权到底归谁?
/ 02 / 当数据成为一种生意,控制权争夺战正在打响
在互联网大厂,修改隐私条款的情况并不是个例。
过去一年里,包括Adobe、谷歌、Zoom和X等大公司都纷纷更新其服务条款或隐私政策。目的只有一个,就是允许自己使用用户数据来训练AI模型。
去年7月,谷歌对其隐私政策进行了修改,增加了“公共信息可用于训练其AI聊天机器人,以及谷歌翻译、Bard等产品和功能”的描述,这一动作引发争议。为了安抚用户,谷歌声明称,其隐私政策的变更只是澄清了“像Bard(现为Gemini)这样的新服务也包括在内。”
6月初,Adobe就在其隐私政策中加入了一句关于内容访问权限的更新,激怒了不少创作者。这个条款影响了Adobe创意云套件的超过2000万用户,一些用户认为Adobe正在收集用户的艺术作品,用于训练AI模型。

来源:Adobe
不止硅谷,国内类似的事件也时有发生。
2023年3月,网易旗下LOFTERAI绘画功能被质疑使用用户作品进行AI训练,导致不少原创画师逃到了其他平台。随后,LOFTER下架相关产品,并发布官方致歉信。
2023年8月,多位插画师发布停更通知,他们质疑小红书旗下AI绘画产品TriK未经允许,将其绘画作品“投喂”给AI训练,引发版权争议。
这些背后凸显了一个关键问题——当数据价值越来越大,平台选择不断释放数据价值,而用户正试图重新拿回数据控制权。
在互联网时代,用户数据的讨论主要集中在安全性。但到了AI时代,这事的性质彻底变了。数据不仅成了重要的生产资源,甚至买卖数据成为了媒体和社交平台一种的商业模式。
作为全世界最大的UGC平台之一,Reddit拥有超过10亿个帖子和160亿条横跨各个主题的评论,无疑是数据采集的金矿。
根据Reddit财报披露,公司预计今年从LLM开发商授权数据的交易中获得6600万美元收入,占年收入的6%。随着与OpenAI达成新的数据授权协议,这一数字还有不小增长空间。
此前,苹果公司也曾向新闻出版商提供5000万美元的报价,以获取其内容训练LLM。一些出版商也已与OpenAI等公司签约,价格也很可观,按照每张图片1-2美元、每段短视频2-4美元、每字0.001美元的定价向其出售内容。
当数据买卖逐渐成为平台重要的收入来源时,作为数据内容的重要生产方,用户与平台之间仍然缺乏一个合理的分配机制。
更令人头疼的问题是,由于监管的滞后性,传统著作权法中所适用的侵权判定原则,并不适用于平台AI的侵权问题。
谈到如何判定AI侵权事件时,律师事务所从业者甲片告诉乌鸦君,著作权本意是维护作者的独创性,而AI作为大数据的产物,利用百家之所长将各种要素堆砌在一起形成不同风格的作品,由于要素涉及面广,很容易直接“复制黏贴”其他作者独到的地方。
甲片补充说,作为新兴产物,AI相关法律法规并不完善,如将以前判定抄袭方式同样应用到AI上恐怕会造成认定困难。在实务中,判定AI侵权的难点在于举证,被侵权人很难用完整的证据链证明AI存在抄袭行为,最终导致不构成侵权等不利后果。
也就是说,平台的用户和创作者几乎没有任何反制的手段。从这个角度看,艺术家们纷纷“逃离” Ins,何尝不是拿回数据控制权的一种选择。
从长远看,只要一天没有建立合理的利益分配机制,平台与用户之间数据控制权的争夺就永远不会结束。这次艺术家与Meta旗下平台发生冲突,Cara爆火,一切更像是一个开始。
