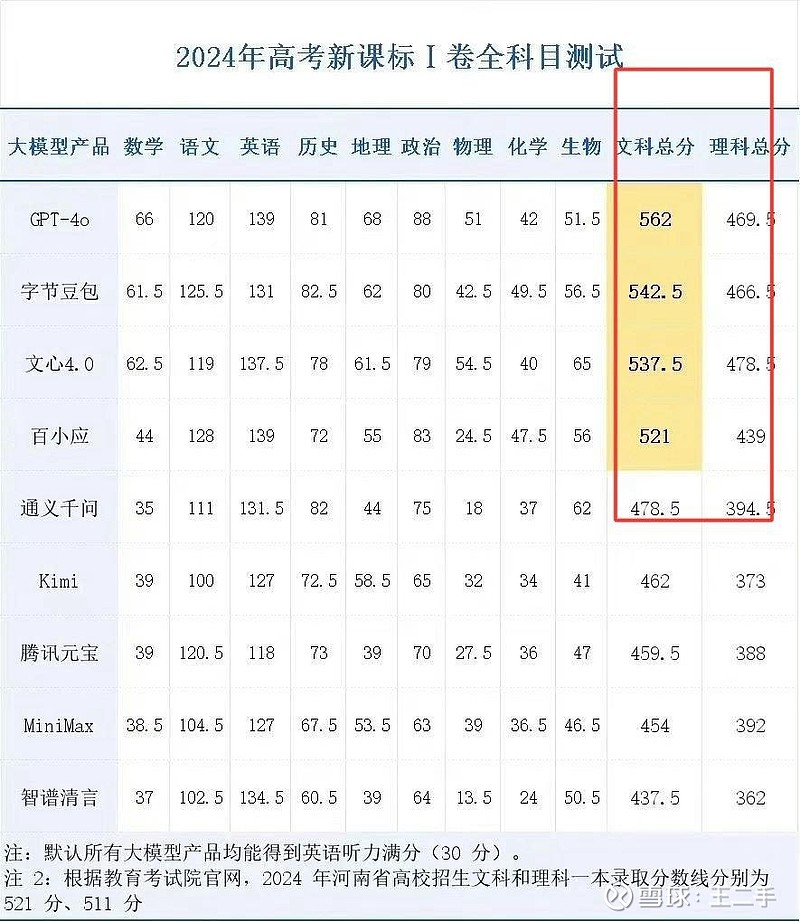
#AI# #ChatGPT# 大家原本一致预期AI应该在逻辑推理和运算上更胜一筹,所以参加高考的话应该更擅长理科而不是文科。结果出来了,恰恰相反。所有的大模型都是语文分数高于数学分数,文科总分数高于理科总分数。不仅国内的大模型如此,国外的chatgpt也是如此。由此可见,目前的大模型依旧处于一个依葫芦画瓢的初级阶段,是一个玩剪辑拼接文字游戏的“符号房间”(类比“中文房间”概念)。而不是我们真正想象和需要的人工智能。