图片上传中......
赛题背景
近年来,随着陆上风电机组装机厂址的扩展,在天气突变较多的地区安装的风力发电机组受到气象变化的影响愈发显著。在风况突变时,由于控制系统的滞后性,容易导致机组出现载荷过大,甚至是倒机的情况,造成重大经济损失。同时,现有超短期风功率预测的准确性较差,导致风功率预测系统对电网调度的参考价值不大,并且会导致业主产生大量的发电量计划考核。由于常见的激光雷达等风速测量产品单价高昂、受天气影响较大,难以实现批量化的应用部署,且在大时间空间尺度下仍难以具有可靠的前瞻性。因此,可靠的超短期风况预测迫在眉睫。
超短期风况预测是一个世界性难题,如果能通过大数据、人工智能技术预测出每台机组在未来短时间内的风速和风向数据,可以提升风电机组的控制前瞻性、提高风电机组的载荷安全性;同时,现有超短期风功率预测能力的提升,将带来显著的安全价值和经济效益。
本次比赛由深圳保安区人民政府与中国信息通信研究院联合主办,提供了来自工业生产中的真实数据与场景,希望结合工业与AI大数据,解决实际生产任务中面临的挑战。
数据分析
训练集说明
两个风场各两年的训练数据:
1. 每个风场25台风电机组,提供各台机组的机舱风速、风向、温度、功率和对应的小时级气象数据;2. 风场1的风机编号为:x26-x50,训练集数据范围为2018、2019年;3. 风场2的风机编号为:x25-x49,训练集数据范围为2017、2018年;4. 各机组的数据文件按 /训练集/[风场]/[机组]/[日期].csv的方式存储;
5. 气象数据存储在 /训练集/[风场] 文件夹下。
测试集说明
1. 测试集分为两个文件夹:测试集初赛、测试集决赛,初赛和决赛的文件夹组织形式一致;
2. 初赛和决赛文件夹各包括80个时段的数据,每个时段1小时数据(30S分辨率,时间以秒数表达),春夏秋冬各20个时段,初赛编号1-20,决赛编号21-40;即初赛的时段编号为春_01-冬_20共80个;决赛的时段编号为春_21-冬_40共80个;
3. 各机组的数据文件按照 /测试集_**/[风场]/[机组]/[时段].csv 的方式存储;
4. 气象数据存储在 /测试集_**/[风场]/ 文件夹下,共80个时段风场所在地的风速风向数据,每个时段提供过去12小时和未来1小时的风速和风向数据。时段编码同上,时间编码为-11~2,其中0~1这个小时正好对应的是机舱的1小时数据。

上图为测试集合数据划分方式,-11~1时间段之内积累的数据作为模型的输入,用于预测未来10分钟内(1~2之间)的风速和风向。
缺失值
数据中的缺失值主要来自两个方面,一种是当天的数据记录存在缺失,另一种是某些时间段的数据存在缺失。多种缺失情况导致在填充数据时存在遗漏问题,仅使用一种方式填充缺失值会导致缺失值的填充出现缺漏,因此比赛中我们同时使用了forward fill、backward fill与均值填充以保证填充覆盖率。这样处理可能会引入噪音,但是神经网络对于噪音有一定的容忍度,因而最终的训练效果影响并不大。考虑到训练数据、未来的测试数据中都可能存在缺失数据,而且它们的记录方式是相同的,因此我们没有去掉存在缺失值的数据,同时对它们使用了相同的填充方式,避免因为预处理不同导致数据分布不一致问题的出现。
模型思路介绍
模型结构
比赛中,我们采用了Encoder-Decoder 形式的模型,通过序列模型挖掘输入序列中的信息,再通过Decoder进行预测。这里的Encoder、Decoder有多种选择,例如常见的序列模型LSTM,或者近几年兴起的Transformer。比赛中我们在Decoder侧堆叠了多层LSTM,Encoder侧只使用了一层LSTM。模型中没有加入dropout进行正则化,这是考虑到数据中本身就存在大量的高频噪音,再加入dropout会导致模型收敛缓慢,影响模型的训练效率。我们使用飞桨框架搭建模型结构,后来发现飞桨官方的自然语言处理模型库PaddleNLP(https://github.com/PaddlePaddle/PaddleNLP)提供了方便的数据处理API、丰富的网络结构和预训练模型以及分类、生成等各种NLP应用示例,很适合打比赛,后续会考虑用起来。
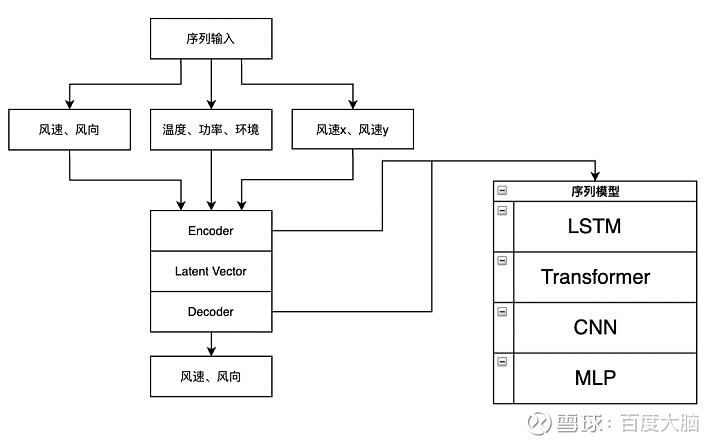
使用飞桨框架构建的最终模型结构的代码如下:
class network(nn.Layer):
def __init__(self, name_scope='baseline'):
super(network, self).__init__(name_scope)
name_scope = self.full_name()
self.lstm1 = paddle.nn.LSTM(128, 128, direction = 'bidirectional', dropout=0.0)
self.lstm2 = paddle.nn.LSTM(25, 128, direction = 'bidirectional', dropout=0.0)
self.embedding_layer1= paddle.nn.Embedding(100, 4)
self.embedding_layer2 = paddle.nn.Embedding(100, 16)
self.mlp1 = paddle.nn.Linear(29, 128)
self.mlp_bn1 = paddle.nn.BatchNorm(120)
self.bn2 = paddle.nn.BatchNorm(14)
self.mlp2 = paddle.nn.Linear(1536, 256)
self.mlp_bn2 = paddle.nn.BatchNorm(256)
self.lstm_out1 = paddle.nn.LSTM(256, 256, direction = 'bidirectional', dropout=0.0)
self.lstm_out2 = paddle.nn.LSTM(512, 128, direction = 'bidirectional', dropout=0.0)
self.lstm_out3 = paddle.nn.LSTM(256, 64, direction = 'bidirectional', dropout=0.0)
self.lstm_out4 = paddle.nn.LSTM(128, 64, direction = 'bidirectional', dropout=0.0)
self.output = paddle.nn.Linear(128, 2, )
self.sigmoid = paddle.nn.Sigmoid()
# 网络的前向计算函数
def forward(self, input1, input2):
embedded1 = self.embedding_layer1(paddle.cast(input1[:,:,0], dtype='int64'))
embedded2 = self.embedding_layer2(paddle.cast(input1[:,:,1]+input1[:,:,0] # * 30
, dtype='int64'))
x1 = paddle.concat([
embedded1,
embedded2,
input1[:,:,2:],
input1[:,:,-2:-1] * paddle.sin(np.pi * 2 *input1[:,:,-1:]),
input1[:,:,-2:-1] * paddle.cos(np.pi * 2 *input1[:,:,-1:]),
paddle.sin(np.pi * 2 *input1[:,:,-1:]),
paddle.cos(np.pi * 2 *input1[:,:,-1:]),
], axis=-1) # 4+16+5+2+2 = 29
x1 = self.mlp1(x1)
x1 = self.mlp_bn1(x1)
x1 = paddle.nn.ReLU()(x1)
x2 = paddle.concat([
embedded1[:,:14],
embedded2[:,:14],
input2[:,:,:-1],
input2[:,:,-2:-1] * paddle.sin(np.pi * 2 * input2[:,:,-1:]/360.),
input2[:,:,-2:-1] * paddle.cos(np.pi * 2 * input2[:,:,-1:]/360.),
paddle.sin(np.pi * 2 * input2[:,:,-1:]/360.),
paddle.cos(np.pi * 2 * input2[:,:,-1:]/360.),
], axis=-1) # 4+16+1+2+2 = 25
x2 = self.bn2(x2)
x1_lstm_out, (hidden, _) = self.lstm1(x1)
x1 = paddle.concat([
hidden[-2, :, :], hidden[-1, :, :],
paddle.max(x1_lstm_out, axis=1),
paddle.mean(x1_lstm_out, axis=1)
], axis=-1)
x2_lstm_out, (hidden, _) = self.lstm2(x2)
x2 = paddle.concat([
hidden[-2, :, :], hidden[-1, :, :],
paddle.max(x2_lstm_out, axis=1),
paddle.mean(x2_lstm_out, axis=1)
], axis=-1)
x = paddle.concat([x1, x2], axis=-1)
x = self.mlp2(x)
x = self.mlp_bn2(x)
x = paddle.nn.ReLU()(x)
# decoder
x = paddle.stack([x]*20, axis=1)
x = self.lstm_out1(x)[0]
x = self.lstm_out2(x)[0]
x = self.lstm_out3(x)[0]
x = self.lstm_out4(x)[0]
x = self.output(x)
output = self.sigmoid(x)*2-1
output = paddle.cast(output, dtype='float32')
return output
飞桨框架在训练模型时有多种方式,可以像其他深度学习框架一样,通过梯度回传进行训练,也可以利用高度封装后的API进行训练。在使用高层API训练时,我们需要准备好数据的generator和模型结构。飞桨框架中generator的封装方式如下,使用效率很高:
class TrainDataset(Dataset):
def __init__(self, x_train_array, x_train_array2, y_train_array=None, mode='train'):
# 样本数量
self.training_data = x_train_array.astype('float32')
self.training_data2 = x_train_array2.astype('float32')
self.mode = mode
if self.mode=='train':
self.training_label = y_train_array.astype('float32')
self.num_samples = self.training_data.shape[0]
def __getitem__(self, idx):
data = self.training_data[idx]
data2 = self.training_data2[idx]
if self.mode=='train':
label = self.training_label[idx]
return [data, data2], label
else:
return [data, data2]
def __len__(self):
# 返回样本总数量
return self.num_samples
准备好generator后,便可以直接使用fit接口进行训练:
model = paddle.Model(network(), inputs=inputs)
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.002,
parameters=model.parameters()),
loss=paddle.nn.L1Loss(),
)
model.fit(
train_data=train_loader,
eval_data=valid_loader,
epochs=10,
verbose=1,
)
优化pipeline
对于不同风机的数据,我们提取特征的方式是相同的,因此我们可以利用python的Parallel库进一步优化代码的性能,提升迭代的效率。核心代码如下:
# 生成训练数据
def generate_train_data(station, id):
df = read_data(station, id, 'train').values
return extract_train_data(df)
# 通过并行运算生成训练集合
train_data = []
for station in [1, 2]:
train_data_tmp = Parallel(n_jobs = -1, verbose = 1)(delayed(lambda x: generate_train_data(station, x))(id) for id in tqdm(range(25)))
train_data = train_data + train_data_tmp
这里提升的效率与CPU的核心个数成正比,比赛中我们使用了8核CPU,因此可以在数据生成上提升8倍的效率。
拟合风向的问题
本次比赛的预测标签包含风速与风向,其中对于风向,由于角度是循环的,我们有
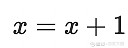
评价函数为 MAE。在训练阶段,直接预测风向会存在问题,因为0与1代表着相同的意义,模型在遇到风向为0/1的情况时预测为它们的均值0.5,导致误差。这里我们通过将风向、角度转化为风向在垂直方向上的分量,来避免直接预测风向,同时可以避免拟合风向带来的问题。
处理噪音
在取得A榜第一名的成绩后,我们尝试对数据中存在的噪音进行处理。由于对输入侧进行处理的风险比较大,容易抹除输入特征中的有效信号,于是我们选择对标签进行平滑处理。我们将模型预测后的值与原标签做加权平均,接着使用平滑后的新标签进行训练,实现了在A榜上0.1分的提升。
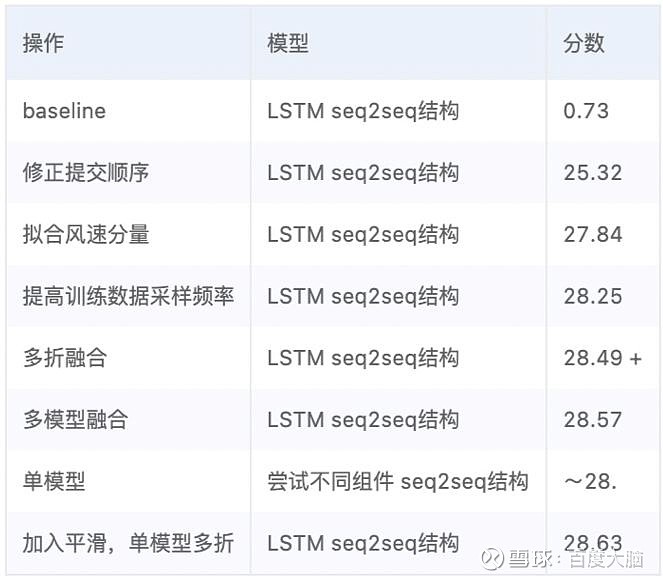
实验结果
比赛的分数由如下公式计算得出:
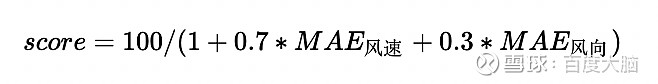
其中,
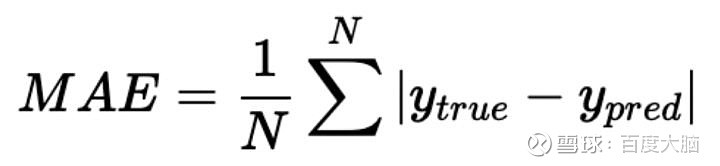
为平均绝对误差。实验结果如下表所示。不难发现,比赛成绩的提升主要来自于对数据与标签的处理,这也是我们在建模时最应该重视的两个要素。
赛后感想
这一次工业大数据比赛中,我们在风况预测赛道与重型配件需求预测赛道中均取得了二等奖的好成绩。通过这一次比赛,我们发现工业场景下的数据质量可能并不理想,对缺失值、噪音都需要进行细心处理。在处理时间序列预测任务时,历史数据的积累中可能并不包括未来遇到的突发情况,仅仅依赖模型可能会存在较大的偏差,这也是我们在建模时需要格外关注的问题。
studio项目链接:https://aistudio.baidu.com/aistudio/projectdetail/3260925Paddle地址: https://github.com/PaddlePaddle/PaddlePaddleNLP地址:https://github.com/PaddlePaddle/PaddleNLP
参考文献
[1] 工业大数据产业创新平台 https://www.industrial-bigdata.com/