
大数据文摘受权转载自机器人大讲堂
近日,Google DeepMind发表了一项突破性的研究成果,该公司利用深度强化学习方法,成功训练出了一个能够在简化版1v1足球比赛中灵活运动、高效进攻防守的 “足球运动员”机器人。这一研究不仅让双足机器人在动作技能上有了大幅提升,更为开发通用智能体迈出了关键一步!相关研究论文以“Learning agile soccer skills for a bipedal robot with deep reinforcement learning”为题,以封面文章的形式已发表在 Science 子刊 Science Robotics 上。

端到端强化学习,掌握多项运动技能
与传统的机器人控制方法不同,DeepMind采用了端到端的深度强化学习范式来训练机器人。这种方法不需要人工设计具体的动作指令,而是让智能体通过不断与环境互动、获得奖励反馈来自主学习最优策略。
具体来说,研究人员将训练过程分为两个阶段。第一阶段聚焦于基本运动技能的习得,包括从地面站立起身、在面对未经训练的对手时进球得分等。第二阶段则是在完整的1v1足球赛中综合运用这些技能,并根据比赛形势进一步优化策略。值得一提的是,第二阶段还融入了自我对弈的训练方式,即机器人随机与自身在此前不同训练阶段的状态进行对抗。这使得机器人学会了根据场上形势调整策略,预判和应对对手的行为。
通过这样的分阶段训练,机器人最终掌握了行走、转弯、踢球、快速起身等多项不同粒度的运动技能,并能在实战中灵活切换。当快速奔跑时,机器人的步态与慢走时明显不同;当需要护球或拦截时,它会采取与射门时不一样的姿态。这些丰富的动作变化本质上源自端到端范式下智能体对环境的连续自适应过程。
大幅超越传统机器人控制方法
为了定量评估学习策略的性能,研究人员将其与传统的脚本化控制器进行了横向比较。他们设计了行走速度、转弯速度、起身时间、踢球速度等一系列指标。结果显示,在所有这些指标上,学习所得的策略都取得了显著优势:
行走速度:提高181%,达到脚本化控制器的2.81倍
转弯速度:提高302%,达到脚本化控制器的4.02倍
起身时间:缩短63%,仅为脚本化控制器的37%
踢球速度:提高34%,为脚本化控制器的1.34倍
这些数据有力地证明了端到端强化学习范式在机器人运动控制领域的优越性。学习所得的策略不仅在动作效率上全面超越了传统方法,而且展现出了更强的灵活性和鲁棒性。比如面对突发的摔倒,学习策略能迅速做出保护和恢复的应急反应,而不是像脚本控制那样呆滞地躺在地上。
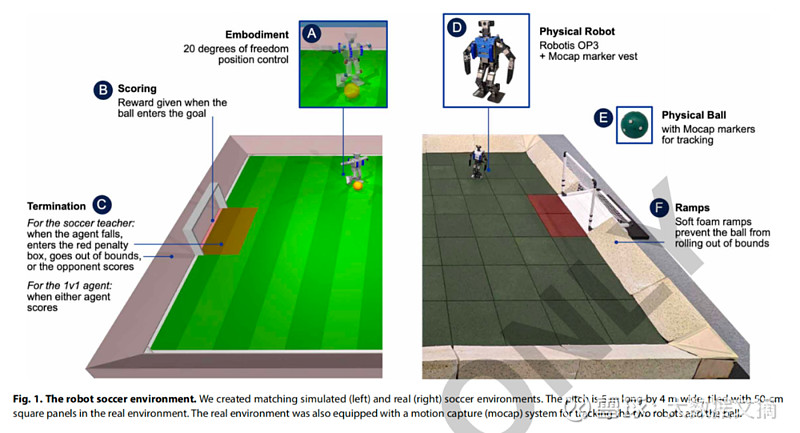
从模拟到现实的"零次学习"迁移
值得一提的是,尽管机器人的训练完全在模拟环境中进行,但学习所得的策略可以直接"零次迁移"到真实机器人平台上,中间无需任何人工调优。这得益于研究人员在模拟训练中采取的一系列领域随机化和数据增强技术,旨在最小化模拟与真实环境之间的差异。
在真实环境中的系统测试进一步验证了该方法的有效性。以机器人静止时用右脚射门为例,在模拟环境中的成功率为100%,而在真实环境中依然高达87.5%。虽然现实世界的复杂性不可避免地带来了一定程度的性能损失,但在绝大多数典型的足球测试场景下,真实机器人的成功率均在70%以上。这充分证实了该学习方法的实用潜力,有望在实际应用中取得良好的鲁棒性和泛化性能。

连贯而灵活地切换不同动作模式
研究人员之所以选择端到端强化学习范式,一个重要原因就是希望学到一个能连贯而灵活地在不同动作模式间切换的策略。为了直观展示学习策略的这一特性,,他们借鉴了分析动物运动的方法,将机器人的20维关节运动在低维空间中可视化。
通过对比学习策略与脚本化控制器的嵌入空间轨迹,可以清晰地看到两者的区别:脚本化控制往往基于特定频率的正弦型轨迹,因此在嵌入空间中形成简单的闭合曲线。学习策略的轨迹则呈现出更多变化。不同步态之间的过渡不再突兀,而是形成了一条连续的"丝带"。同时,不同的动作模式(如慢走、快跑、踢球、起身等)在嵌入空间中形成了独特的簇结构。
当在1v1足球赛中长时间运行时,学习策略在动作空间中划出了一个包含多个亚循环的复杂轨迹。这表明该策略能根据复杂多变的比赛形势,在各种动作模式间灵活调度、动态切换,由此产生了宏观上的整体协调和高度适应性。
迈向通用智能体的坚实一步
综上所述,DeepMind的这一研究工作充分展示了端到端深度强化学习在机器人领域的巨大潜力。它不仅在单项运动技能的效率、灵活性上实现了大幅跃升,更为实现多个复杂技能的流畅整合、策略层面的动态调控打开了新的可能性。尽管离参加人机世界杯还有很长的路要走,但这项突破无疑为开发多任务、多场景下的高性能通用机器人迈出了关键一步。展望未来,类似"自我蒸馏"式的端到端学习范式有望成为通用智能体研发的有力工具,并在工业、服务、救援等领域得到广泛应用,推动人工智能事业的进一步发展。
对未来机器人和人工智能的展望
DeepMind此次利用强化学习成功训练出灵活高效的双足足球机器人,可以说是向着通用人工智能迈进的重要里程碑。它不仅在机器人领域展现了深度学习的强大潜力,也为其他需要复杂序贯决策的智能任务提供了新的思路。
未来,类似的端到端学习范式有望在更多实际场景中得到应用。比如在工业领域,我们可以期待机器人能像人一样灵活操纵工件、适应多变的生产需求;在家庭服务领域,老人和儿童的陪护机器人或将具备更自然的社交互动能力;在危险环境勘察、搜救等任务中,高度灵活自主的机器人助手将大大提高任务效率和安全性。
当然,当前的研究还主要局限在相对单一和结构化的环境中。未来要实现在开放环境下多任务、多场景、长时序的自主学习,还面临诸多挑战:
其一,现实世界远比实验环境复杂,存在大量的不确定性、稀疏回报等"困难样本",对学习算法的采样效率和泛化能力提出了更高要求。如何在有限的实际互动中学到鲁棒、高效的策略将是关键研究方向。
其二,要实现多个复杂技能的流畅整合,可能需要发展多尺度、多层次的时空抽象机制。这涉及如何平衡局部精细控制与全局宏观规划,以及如何实现反馈控制、运动规划、概念推理等不同认知模块的协同。
其三,机器人在实际应用中还面临一系列硬件约束,比如能耗、算力、成本等。这就要求学习算法能充分利用有限资源,甚至主动探索硬件结构与控制策略的协同优化。
此外,随着机器人等智能系统走向开放环境,安全性和伦理问题也日益凸显。如何建立行为准则,避免意外伤害、误用滥用将是一个重要议题。这可能需要从算法层面引入安全防护和价值引导,确保智能体在学习过程中始终遵循人类的意图。
尽管挑战不少,但人工智能和机器人技术正在快速发展。DeepMind的这项工作无疑为通用智能系统的实现开辟了广阔前景。未来,人形机器人也许真的能成为人类生活和工作中的得力助手,并由此引发社会范式的深刻变革。我们期待在不远的将来,能有更多突破性的进展出现,共同推动人工智能事业的蓬勃发展。

租售GPU算力
租:4090/A800/H800/H100
售:现货H100/H800
特别适合企业级应用
扫码了解详情☝
点「在看」的人都变好看了哦!