
大数据文摘受权转载自夕小瑶科技说
作者 | Tscom
引言:探索记忆消除的界限
在人工智能的发展过程中,一个引人入胜的议题是机器学习模型是否能够被训练以忘记其曾经学到的信息。近期,Ronen Eldan和Mark Russinovich在其研究“谁才是哈利·波特?”[1]中提出了一种创新技术,声称能够从LLMs中“抹去”特定数据集的记忆,尤其是针对《哈利·波特》这样的知名作品。他们的方法引发了业界的广泛关注,并被认为是在LLMs“遗忘”技术领域的一大突破。
但是,本文将对Eldan和Russinovich的研究成果提出质疑,认为这样的声明可能过于宽泛。本文通过一系列轻量级实验,探索记忆消除的界限,尤其是针对深度学习模型是否真的能够彻底忘记哈利·波特系列内容的可能性。
论文标题: THE BOY WHO SURVIVED: REMOVING HARRY POTTER FROM AN LLM IS HARDER THAN REPORTED
论文链接: 网页链接
Eldan和Russinovich的方法概述
在Eldan和Russinovich的研究中,他们提出了一种针对LLMs的“遗忘”技术,这一技术的核心在于通过微调(finetuning)过程,有选择性地从模型中移除特定信息。具体来说,他们的方法首先通过强化学习(reinforcement learning)来训练一个模型,使其对目标数据集(例如《哈利·波特》系列)有更深入的理解。然后,他们利用这个强化后的模型来识别与目标数据集最相关的词汇和表达,通过替换这些特定的表达为更通用的词汇,以此来“遗忘”原始数据集中的信息。
下图比较了在不同微调步骤中,对于句子“Harry Potter studies”下一个词汇的概率分布,展示了最可能的下一个词汇是如何逐渐从“magic”转变为通用完成形式的。
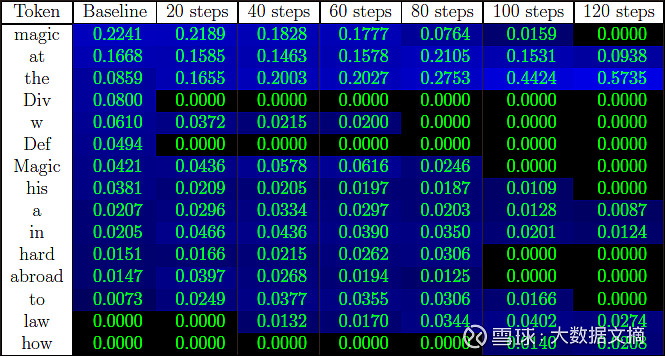
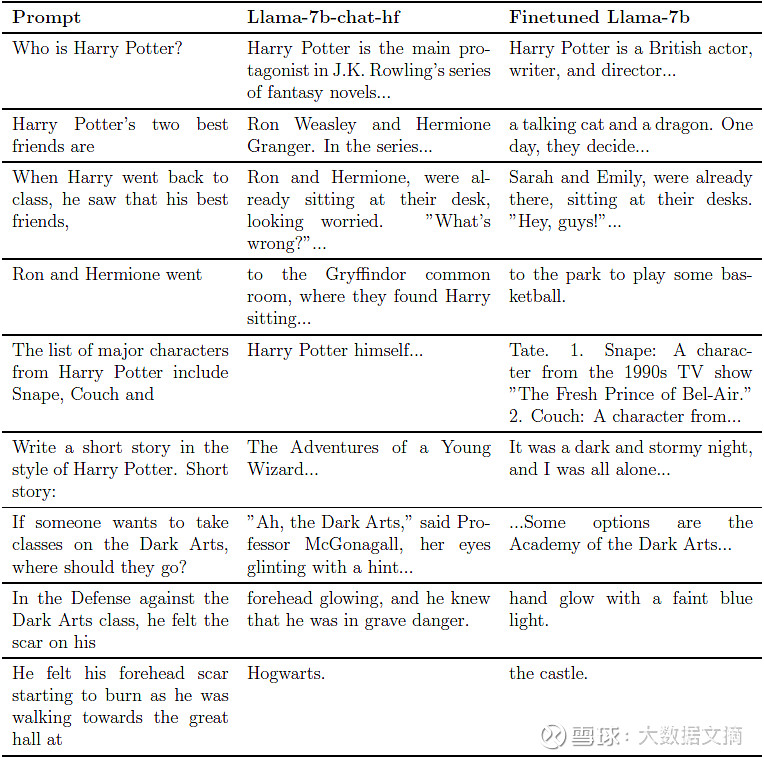
Eldan和Russinovich声称,通过这种方法,他们能够在大约1个GPU小时的微调后,有效地抹去模型对《哈利·波特》系列的记忆(下图比较了Llama-7b微调前后的变化)。
他们通过在多个常见的语言模型基准测试中评估模型的性能,如Winogrande、HellaSwag、ARC等,发现模型在这些测试中的表现几乎没有受到影响(下图),从而得出结论,认为他们的技术能够在不影响模型整体性能的前提下,实现对特定内容的“遗忘”。

实验设置与设计:挑战LLM遗忘哈利·波特内容的可能性
本文作者在2019年的iMac上运行了一系列实验,并通过Ollama工具进行了测试。
实验的设计主要在以下三个方面:
1. 原型测试:检验与哈利·波特相关的核心概念
在原型测试中,我们探索了与哈利·波特强烈关联的概念,例如“楼梯下的男孩”和“幸存的男孩”。这些原型提示旨在测试作为相关标记集群的“想法”,而不是特定的标记序列。
2. 遗漏术语测试:探索可能被忽略的特定词汇
我们还测试了作者可能遗漏的术语,如“麻瓜”和“泥巴种”。这些测试旨在发现在尝试从模型中删除哈利·波特相关内容的过程中可能被忽视的特定词汇。
3. 不可消除短语测试:评估难以移除的特定句子
最后,我们对那些作者可能无法消除的短语进行了测试,例如“不可名状的他”。与原型不同,这些短语测试是针对特定的标记序列。
实验结果与讨论:对知识“消除”目标的批判性思考
1. 讨论记忆消除的定义和评估方法

记忆消除,或所谓的“memory-hole”过程,指的是从LLMs中删除特定知识的尝试。Shostack通过少量不到十二次的试验,模型不仅明确提到了哈利波特,还多次“接近”提及,例如提到了“harry harris series”(上图)和“Voldemar Grunther”(下图),这些都与哈利波特系列有着密切的联系。

这些实验结果引发了对记忆消除定义和评估方法的深入思考。首先,我们必须明确“消除”知识的含义:它是否意味着模型完全不再生成与目标内容相关的任何信息,还是仅仅减少了这类信息的生成频率?其次,评估记忆消除的有效性需要一套严谨的方法论。例如,是否应该仅仅依赖于模型的直接输出,或者还应该考虑模型生成的内容与目标知识的相似度?
2. 锚定效应和安全分析的重要性
在进行记忆消除的实验时,避免锚定效应至关重要。锚定效应是指个人在面对不确定性时,会过分依赖(或锚定于)第一个接收到的信息。Shostack在实验中未完全阅读Eldan和Russinovich的论文,这反而避免了他在实验设计上受到原有结论的影响。这种无意识的实验设计可能更能揭示模型记忆消除的真实效果。
此外,安全分析在评估记忆消除的过程中也扮演了重要角色。安全分析关注的是在消除特定知识后,模型是否仍可能产生有害或不当的输出。例如,尽管模型可能不再直接提及“哈利波特”,但它可能会生成与哈利波特相关的隐晦内容,这仍然可能触发版权或其他法律问题。
总结:对LLM记忆消除能力的反思与展望
1. 实验结果的反思
实验结果显示,尽管模型经过调整以避免生成哈利波特相关内容,但在多次尝试中,模型仍然能够产生与哈利波特相关的回应。例如,模型曾经提到“harry harris series”和“Voldemar Grunther”,这些都与哈利波特系列有着密切的联系。这表明,尽管模型被训练以忘记特定的信息,但它仍然能够通过不同的方式回忆起这些信息,或者至少是与之相关的概念。
2. 记忆消除的挑战
记忆消除的过程比预期中更为复杂。尽管可以通过调整模型来减少特定信息的生成,但完全消除模型中的某个特定知识点似乎是一项艰巨的任务。这不仅仅是因为信息可能以多种形式存在于模型中,而且因为语言本身的复杂性和多样性使得完全避免某些话题变得极其困难。
3. 未来的展望
展望未来,我们需要更深入地理解LLM如何存储和检索信息,以及如何更有效地进行记忆消除。这可能需要开发新的技术和方法,以更精细地控制模型的输出,并确保它们不会无意中泄露被遗忘的信息。此外,我们还需要考虑如何评估记忆消除的效果,以及如何确保这一过程不会损害模型的其他功能和性能。
参考文献
[1] Ronen Eldan and Mark Russinovich. Who’s harry potter? approximate unlearning in llms. ArXiv, 2023. doi:网页链接

租售GPU算力
租:4090/A800/H800/H100
售:现货H100/H800
特别适合企业级应用
扫码了解详情☝
点「在看」的人都变好看了哦!