
大数据文摘授权转载自zzllrr小乐
作者:Keith Devlin
译者:zzllrr小乐
像ChatGPT这样的大语言模型(Large Language Models,LLM)会改变新数学的发现方式吗?是的。它已经发生了,就像早期的计算技术:机械和电子计算器,通用数字计算机,图形计算器等,以及最近的工具,如Mathematica,Maple和(我最喜欢的)Wolfram Alpha。(后三种可以声称是一种特殊的“人工智能”,尽管与国际象棋系统一样,该领域的高度限制性意味着我们通常不会将它们归类为人工智能。
在数学中,是否存在人类可以解决而AI不能解决的问题?我会争辩说,有。长期悬而未决的问题,如黎曼假设(RH)可能是这样的例子。当然,证明这一点并不简单,因为它是一个普遍的否定性命题。事实上,你无法证明这种说法。我们所能做的反映了数学的本质,并提供了初步认定的证据,证明数学发现的某些方面是大语言模型无法实现的。
然而,实际情况是,使用大语言模型很可能(我猜是“将”,很快)为人类数学家解决重大开放问题(如RH)提供有价值的帮助。做到这一点的关键是确定大语言模型给数学带来了什么新的东西(在某些情况下是它们独有的),以及数学思维的哪些部分是它们不能做的。
和往常一样,由于数学思维是人类思维的极端情况,这种分析肯定会揭示出大语言模型可能导致的我们生活其他方面的变化。
首先,讲一点历史。(这是个人视角的历史,但它为我关于大语言模型的论点提供了一些背景。)目前对人工智能的狂热被ChatGPT等大语言模型的成功所激发,这至少是我经历过的第四次“人工智能革命”。我说“至少”是因为这个数字取决于你对“人工智能革命”的看法。几乎每一代学习数理逻辑(我将其视为一种过滤器,因为它甚至适用于不基于逻辑的人工智能)的学生,都被“会思考的机器”的诱惑所吸引。即使是我们这些意识到机器(就像我们今天所知道的和可以建造的那样)实际上不会思考的人,也会对创造能够进行有用形式的“仿造思维”的机器的可能性而感兴趣。

1950年10月出版的学术期刊《MIND心智》的封面(左),该期刊发表了艾伦·图灵关于“思考机器”的著名论文(右第一页)
我出生得太晚了,没有被第一次人工智能浪潮所吸引,这是数学家和计算机先驱艾伦·图灵(Alan Turing,1912 - 1954)在1950年发表在学术哲学杂志《心智》上的论文《计算机器和智能》 网页链接 中开创的。图灵在文章的开头写道:“我建议考虑这样一个问题:机器能思考吗?”
从今天的角度来看,他的论文最突出的特点是,他首先承认需要“机器”和“思考”的定义,并提出了一个解决这些定义相关问题的程序(他著名的“图灵测试”)。没有人工智能系统通过了它,但它们的表现要好得多。其中一个因素是,人类倾向于将智能代理归于任何表现出(非常)少数类似人类行为特征的系统;例如,参见1996年由我(最近)的斯坦福大学同事拜伦·里夫斯(Byron Reeves)和已故的克利福德·纳斯(Clifford Nass,1958 - 2013)撰写的《媒体等同》(The Media Equation)。
图灵的论文发表后不久,1956年,约翰·麦卡锡在达特茅斯学院组织了一次小型科学会议,通常被认为是人工智能(AI)学术(研究和工程)学科的奠基,在此会议过程中给它起了这个名字。
(我认识麦卡锡,有一次在家里招待过他;我最接近图灵的是一位逻辑学家同事,他曾是图灵的学生。)
最初的人工智能革命,以形式逻辑为理论基础,最终被称为GOFAI(good old-fashioned AI),“好的老式人工智能”。这是开发“思考机器”的许多尝试中的第一个,每一种新方法的推出都预测这些目标将在大约25年内实现。
必须指出,未能实现这些崇高目标,是由于每一次努力都引发了现在我们在生活的许多方面认为理所当然的技术的真实进步。追求大目标而未能实现它们总是一个很好的前进策略。

人工智能先驱约翰·麦卡锡(1927 - 2011)
以我为例,1968年我从伦敦国王学院数学系毕业后(在此期间,我在英国石油化工公司做暑期工作,用Algol-60和汇编语言编写大型机的程序),我去了布里斯托大学,打算攻读计算理论博士学位,这是一门刚刚兴起的学科,人工智能是其中的一部分。我很快就改变了方向,当这个研究领域的原始状态被公理集合论的爆炸性活动所掩盖时,1963年保罗·科恩(Paul Cohen,1934 - 2007)发现了一种方法来证明(某些种类的)数学命题是不可判定的。
(作为一个刚刚起步的年轻数学家,我渴望研究“深奥而困难的问题”。我太年轻了,没有意识到数学的“困难”可以有不同的形式,证明定理并不是唯一的主要目标。)差不多过了20年,我才回到了计算机能做什么的初始兴趣。
我对人工智能一直缺乏兴奋感,尤其是在我职业生涯的早期,源于阅读休伯特·德雷福斯(Hubert Dreyfus,1929 - 2017)的书《计算机不能做什么》(What Computers Can’t Do)。德雷福斯的批评发表于1972年,也就是我获得集合论博士学位的第二年,当时很多人都不认可他的批评,但对我来说,他的观点听起来是正确的,现在仍然如此。
1984年苹果电脑的发布重新点燃了我对计算机和人工智能的兴趣(我立刻成为WIMP(窗口、图标、菜单、鼠标)技术的粉丝,可以看到数学中的主要用途),我接受了邀请,加入了英国技术公司Logica的一个研究团队,从事由Alvey计划资助的项目,这是英国的一项主要倡议,(主要是)人工智能技术(另一个名称:基于知识的智能系统,IKBS - Intelligent Knowledge-Based Systems),以响应日本的“第五代计算机计划”。
我的参与并没有持续很长时间。在我看来,德雷福斯的批评一如既往地中肯。但到那时,我已经充分接触了自然语言处理和使用数字设备来调解人类互动的最新令人兴奋的发展,将这些视为人工智能技术可能发挥作用的有前途的领域。(对我来说,关键是使用人工智能技术来补充人类智能,而不是取代它。最近并行分布式处理(PDP - Parallel Distributed Processing)也取得了成功,正如大卫·鲁梅尔哈特(David Rumelhart,1942 - 2011)和杰伊·麦克莱兰(Jay McClelland,1948 -)在1987年出版的同名书籍中所描述的那样;这真的让我很兴奋(因为它试图模拟大脑的工作方式)。
我重新燃起的兴趣使我受到了斯坦福大学的邀请,参加了一个多学科的项目,做的正是我想从事的研究。于是,1987年夏天,我和家人收拾行李(每人两包)飞往加州(最初是一年)。我们再也没有回家。从那时起,我的大部分研究生涯都涉及到试图发展数学技术(“基于数学的”是一个更准确的描述),以处理推理和沟通方面的方式,努力尊重德雷福斯和追随他的其他学者所提出的批评。
正是在斯坦福大学,我不仅遇到了PDP的Rumelhart(现已去世)和McClelland,而且还遇到了Terry Winograd(特里·威诺格拉德,1946 -),斯坦福大学的人工智能先驱,他也加入了“GOFAI反对派”;这一举动肯定与他早期职业生涯中建造物理机器人的人工智能重点不无关联,这意味着他的人工智能程序不断与无情的和不可误导的真实世界正面交锋。(参见现状!)
我还认识了斯坦福大学的心理学家和心理语言学家赫伯·克拉克(Herb Clark,1940 -),然后开始与英国的社会语言学家和人种志学家杜斯卡·罗森伯格(Duska Rosenberg)进行长达十年的研究合作(她获得了计算机科学的第二博士学位--部分原因是她当时在伦敦布鲁内尔大学反驳了工程学同事的批评)。
与Rosenberg的合作产生了我认为是我迄今为止最好的数学工作(第二个十年是与其他美国合作者合作),尽管没有一个发表在数学期刊上。(这与数学相关,但不是通常意义上的数学。我通过撰写关于这个主题的文章,参与数学教育,以及对数学认知的持续兴趣,保持了我在主流数学界的成员资格。)
我在1987年之后所做的工作,尤其是那些与斯坦福大学的联系,以及我与Rosenberg的合作,让我沉浸在太多关于人、语言和社会的证据中,以至于几个月前ChatGPT突然出现时,我没有被它的浮华所诱惑。毫无疑问,它的光彩炫目令所有人感到惊讶,即使是那些建造了这个系统的人。(但只是浮华而已。请注意计算语言学家艾米丽·本德Emily Bender,她是斯坦福大学的博士生,她的导师是我的好朋友。她关于大语言模型的文章是正确的。她描述大语言模型为“随机鹦鹉 stochastic parrot”,既高度准确,又是一个把注意力集中在“大语言模型能思考吗?”问题上的精彩meme迷因)。
这让我看到了大语言模型在数学实践和数学研究中的作用。
为什么大语言模型(以及人工智能)不会取代人类数学家?
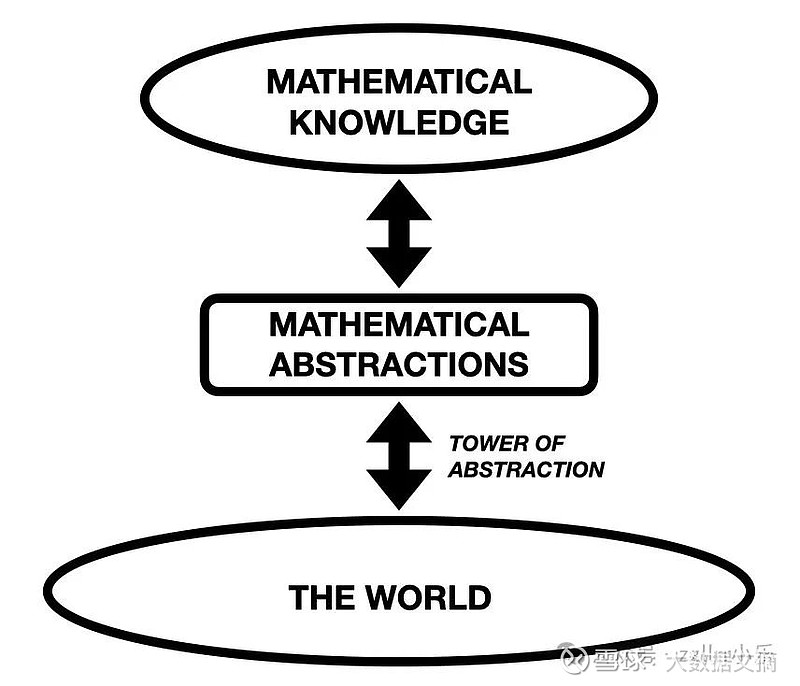
图1. 数学活动的景观。数学通过寻找模式而进步。人类在整个空间中理解工作;大语言模型只在顶部区域工作(尽管它们可以检查更大的搜索空间),但没有理解
尽管数学是抽象的,但它深深植根于物理世界和社会世界。它的基本概念不是任意的发明;它们确实是世界的抽象。
这种抽象的过程可以追溯到数学的起源,大约1万年前在苏美尔出现了数字。去年6月28日,我在纽约数学博物馆的一次在线演讲中讲述了这段历史。你必须支付给MoMath来观看它(它是整个四部分剧集的一部分),但支持博物馆是值得的!
事实上,数字可以说是最基本的数学抽象。你可以提出一个更基本的抽象集合的概念,但从历史上看,数字在几千年前就被抽象了。可以肯定的是,今天的抽象数字是从抽象集合定义和构建的,但我们今天使用的数字,包括计数数字 - 通常作为数轴上的点介绍给孩子 - 是19世纪末20世纪初的创造。
在历史的大部分时间里,计数数字都是多物种配对,它们起源于货币系统(就像我们的“4美元和90美分”货币数字一样)。从这些早期的数字到今天的纯抽象的过渡开始于17世纪的笛卡尔(René Descartes,1596 - 1650),哈里奥特(Thomas Harriot,1560 - 1621),牛顿(Isaac Newton,1643 - 1727)和其他人,只有皮亚诺(Giuseppe Peano,1858 - 1932)和其他人在19世纪末和弗雷格(Friedrich Ludwig Gottlob Frege,1848 - 1925),罗素(Bertrand Arthur William Russell,1872 - 1970),希尔伯特(David Hilbert,1862 - 1943),冯·诺依曼(John von Neumann,1903 - 1957)和其他人在20世纪初的工作才完成。(负数直到19世纪才被认为是真正的数学对象。)
上面的段落是对一个漫长的进化过程的简化,但它指出了我们在抽象上建立抽象的方式。数学抽象与其世界起源之间的联系通常是一座塔。(见图1)
现代数学中的许多抽象实体,如群、环、域、希尔伯特空间、巴拿赫空间等等,都是通过抽象的高塔与现实世界联系在一起的。尽管数学看起来很深奥,但它深深植根于真实的世界。这就是为什么数学结果可以应用于真实的世界;例如,关于4维及更高维度的几何结构的定理可以(并且正在)应用于解决关于通信网络、运输网络和有效数据存储的现实问题。
虽然我们数学家在抽象的世界里工作很舒服,但我们首先(作为学生)爬上塔楼,这意味着我们赋予概念的意义是基于现实的——即使我们没有意识到这种基础。(数学家,也许比其他许多人更清楚地意识到,即使在深入思考解决问题的过程中,我们对自己头脑中发生的事情的理解是多么的少。每当我们“突然”有了突破性的想法时,这种认识就会强加给我们!)
[是的,上个月的帖子是为了建立这个场景,尽管我在本文所写内容独立于那个帖子中的论题。]
因此,数学是一种语义的事业,由与现实有着深刻而根本联系的生物/心灵参与,它们有动机、欲望、好奇心和理解世界和彼此的驱动力。就图示而言,我们在景观中的整个空间中操作。数学知识来自于我们作为生物所从事的活动,使用的是我们和我们的前辈从世界中抽象出来的概念和方法。
大语言模型,相反,只在上层的区域——数学知识。它们处理文本。不是意义,只是文本(即,符号串)。虽然我们人类可以通过看到我们正在研究的语义实体中的模式来取得进步,但大语言模型(隐含地)辨别它们处理的符号中的模式。这些模式反映了符号在人类产生的大量文本中的受欢迎程度(以及,越来越多地,它们自己早期和其他大语言模型的产物,这可能会成为它们和我们的主要问题)。见图2。
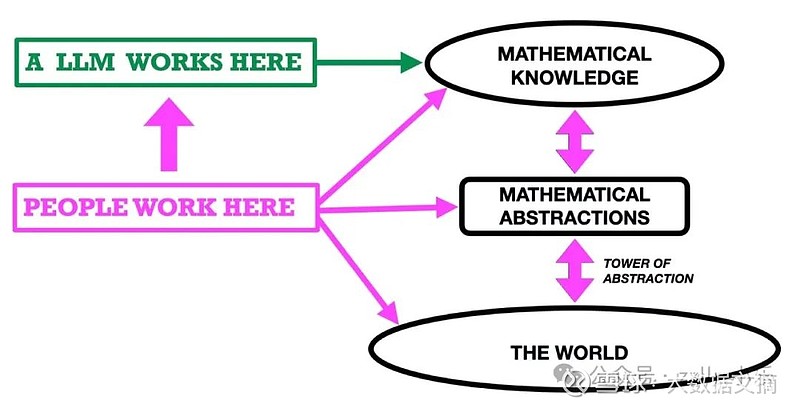
图2. 洋红色箭头表示人们在做数学运算时的操作位置。大语言模型被限制为完全在数学文本上操作(在语法级别)。左边垂直的洋红色箭头表示我们人类数学家如何让大语言模型为我们工作,如果我们这样选择的话。
在大多数情况下,它们的产物是正确的,因为它们引用的大多数文本都是正确的——特别是如果大语言模型被限制为引用经过某种形式的审查和编辑控制的来源。(是这样吗?)但正如现在已经众所周知的那样,它们可以产生看似合理但经检验完全是胡说八道的输出。(对很多应用来说,这是一个很大的负面影响,但对数学来说,这不是一个大问题。我们有能力发现错误,而且通常是非常明确的。)
我认为,这是大语言模型作为“思考机器”的一个主要弱点。即使当我们头在数学云中,我们人类的脚也坚实地站在地面上。(打个比方,我们中的许多人蜷缩在舒适的椅子上沉思。)我们是这个世界的生物,我们是与这个世界互动的一部分,我们的大脑进化成了关于这个世界的行动、反应和思考。一个大语言模型输入和输出符号串。这些是截然不同的活动。[参见附录中关于我们如何思考的当前认知科学的工作总结。]
认为这不是一个巨大区别的任何人,应该花一些时间在图书馆,沉浸到放在“人文”标志下的大量文献中。(也参见我上面关于Winograd和他早期的机器人人工智能工作的旁注。)我们能够为大语言模型的输出给予意义,这一事实反映了我们的认知能力,而不是它们的认知能力;它们只是在做我们设计它们做的事情。(非常像我们建造的时钟一样;时钟没有时间的概念;我们建造时钟,以便我们可以将它们的状态解释为时间。对人工智能系统使用“智能”或“思考”这样的词是一种分类错误。大语言模型做一些与我们不同的事情。(可以把它们想象成一个非常奇特的时钟类似物,设计用途是报告存储在互联网上的人类知识的现状。)我们应该这样看待它们。
我觉得特别有趣的是,大语言模型可能会在当前的数学知识库中发现一种我们人类不太可能发现的模式——除非是两个(或更多)研究人员的一次偶然相遇,他们发现每个人都知道一些与另一个人相关的东西。(数学的民间传说中充满了导致重大进展的例子。这里有一个跨学科的例子。网页链接 )在我看来,这是大语言模型有利于数学研究的一种方式。事实上,大语言模型以这种方式产生原始结果并不是不可能的(尽管可能性很小),也许会给世界带来“ChatGPT-7定理”。
在我看来,更有可能的是大语言模型让数学家意识到他们不知道的(人类或书面)来源。(大语言模型作为“试图证明定理的数学家的约会APP”,有人这样做吗?)当然,我们已经可以使用搜索引擎来做到这一点;事实上,我们中的许多人在开始解决一个新问题时,都会使用Google作为第一个停靠港,正如我之前针对此场景所指出的那样。但是大语言模型带来了一些新的东西:在大量的人类无法辨别(由于规模的原因,如果没有别的原因的话)的书面数学语料库,辨别句法(即,符号)模式的能力。这些模式当中,有许多模式可能最终都没有数学意义。但某些可能会有意义,从而是我们以前从未有过的。
注意:在我去年5月、6月和7月的帖子中,我讨论了大语言模型已具备的用作Wolfram Alpha等数学系统前端的强大力量。
附录:我们如何思考
[更准确的标题应该是“我们如何思考我们的思考”。]
虽然我们对最近的大语言模型的表现感到惊讶,但我们设计了它们,我们知道它们是如何工作的,直到细节。与此相反,我们对自己的大脑如何工作并没有真实的知识。我们没有设计大脑。我们绝不能确定目前的科学知识状态能够描述,更不用说解释我们的大脑是如何工作的了。事实上,有一个强有力的、自然选择的论点可以证明,我们永远不会有意识地接近我们心灵的“内部运作”。(参见《Devlin之角》2023年1月和2月的文章)
我们所能做的就是列出我们思考的一些特征。因为数学思维只是人类思维的一种高度受限的形式(就像语言和音乐是人类交流的受限形式一样),这些思考将为推测我们如何做数学提供一个起点。
人类拥有感知和行动系统,可以干预外部世界并产生有关它的新信息。这些行动系统利用体现在理论(科学或直觉)中的因果表征,也是寻求真理的认知过程的结果。这些理论是根据外部世界进行评估的,并对该世界的行为进行预测和塑造;来自该世界的新证据可以从根本上修改它们。因果表征,如感知表征,旨在解决“逆问题”:根据我们从外部世界接收的数据,重建一个新的、不断变化的外部世界的结构。尽管这些表述可能非常抽象,就像科学理论一样,但它们最终取决于感知和行动,取决于能够以新的方式感知世界并采取行动。文化的进化取决于两种不同认知机制之间的平衡。模仿使知识或技能从一个人传递到另一个人。创新通过与不断变化的世界接触产生新的知识或技能。模仿意味着每一个个体都不需要创新——他们可以利用他人的认知发现。但是,如果某些行为主体没有创新能力,模仿本身就毫无用处。正是这两者的结合,使文化和技术进步。
将上述考虑与大语言模型进行对比,大语言模型聚合了人们生成的大量信息,并使用相对简单的统计推断从这些信息中提取模式。
大语言模型的设计允许产生我们以前没有意识到的信息,我们有时可能会对我们得到的结果感到惊讶。然而(与人类的头脑相反),我们了解生产的机制,直到细节。
在大语言模型的训练或目标函数中,没有任何东西是为了实现寻求真理系统的认知函数(功能),如感知、因果推理或理论形成。
这使得它们成为我们个人和社会使用的(潜在的)有用工具。这可能是一种进步。这种新工具可能会改变我们的生活和工作方式;如果是这样,那么可能会以令我们惊讶的方式(甚至可能让我们感到恐惧,至少在最初)。
然而,与任何具有“隐藏部分”的工具一样,使用它的任何人都必须了解它是如何工作的,它的局限性是什么,以及这些局限性可能导致什么样的危险。Bender高妙的术语“随机鹦鹉”最早出现在2021年的一篇研究论文中,题为《关于随机鹦鹉的危险:语言模型能过大吗?》(On the Dangers of Stochastic Parrots:Can Language Models Be Too Big?)网页链接 注意“危险”这个词。(该论文在ChatGPT出现之前,就出现了。)
在那篇论文中,作者列出了大语言模型对社会的一些真实的危险。随着这些危险的显现(已经开始),社会可能会寻求实施严格的控制。这种新人工智能为数不多的真实的好处之一可能是数学、科学和工程知识,在这些场景中,真理和真实的世界是不可动摇的衡量标准。(影响数学家、科学家和工程师群体的问题则完全不同;在这些方面的危险,Bender等人指出特别严重。)
我们物种的历史中充满了这样的发展,一旦发生,就无法回头。这可能是一个奥本海默时刻。
参考资料:
关于上述问题有大量的文献。我将引用一篇最近的论文,它提供了一个进入该文献的初始入口。我把它作为我的大纲(尤其是上面项目符号列表)的参考来源:
Eunice Yiu , Eliza Kosoy, and Alison Gopnik, Transmission Versus Truth, Imitation Versus Innovation: What Children Can Do That Large Language and Language-and-Vision Models Cannot (Yet) 网页链接 , Association for Psychological Science: Perspectives on Psychological Science , 2023, pp.1–10, National Institutes of Health, DOI 10.1177/17456916231201401

租!GPU算力
新上线一批4090/A800/H800/H100
特别适合企业级应用
扫码了解详情☝

点「在看」的人都变好看了哦!