6篇获选进行口头报告的微软论文
(映维网Nweon 2024年06月24日)计算机视觉是使用计算机及相关设备对生物视觉的一种模拟,是人工智能领域的一个重要组成,并且在AR/VR,3D重建,工业检测,无人机和自动驾驶汽车等领域具有重要应用。
作为重要的计算机视觉和模式识别大会,每年的CVPR大会(Computer Vision and Pattern Recognition)都将吸引业界和学界的广泛参与,而来自世界各地的计算机视觉研究者和工程师都会在这里分享相关研究的最新进展。
对于正在举行中的CVPR 2024,微软共有63份论文获得收录,其中6篇获选进行口头报告。
微软指出:“从在增强现实中精确重现3D人物和视角的技术,到结合先进的图像分割与合成数据以更好地复刻现实世界场景,研究项目的多样性反映了微软研究团队采用的跨学科方法。其他项目则展示了研究人员如何将机器学习与自然语言处理和结构化数据相结合,开发出不仅可以可视化而且可以与环境交互的模型。总的来说,相关项目旨在提高机器感知能力,实现与世界更准确、更灵敏的交互。”
下面整理了6篇获选进行口头报告的微软论文,包括论文链接和摘要介绍(点击小标题即可访问论文的PDF完整版本或项目页面):

1. 网页链接{《BIOCLIP: A Vision Foundation Model for the Tree of Life》}

从无人机到个人手机,各种摄像头收集的自然世界图像日益成为生物信息的丰富来源。用于从科学和保护图像中提取生物学相关信息的计算方法和工具的爆炸式增长,特别是计算机视觉。
然而,其中大多数都是为特定任务设计的定制方法,不容易适应或扩展到新的问题、上下文和数据集。所以,迫切需要为一般性生物图像问题提供一个视觉模型。
为了实现这一目标,团队发布了TreeOfLife-10M,这是最大、最多样化的生物图像机器学习数据集。然后,利用TreeOfLife-10M捕获的生物学的独特属性,即植物、动物和真菌图像的丰富性和多样性,以及丰富的结构化生物学知识,团队开发了TreeOfLife的基础模型BioCLIP。
研究人员严格地对方法进行了各种细粒度生物分类任务的基准测试,并发现BioCLIP始终并且实质上优于现有的基线(绝对高出17%到20%)。Intrinsic Evaluation表明,BioCLIP已经学习了符合TreeOfLife的层次表示,揭示了其强大的泛化能力。代码、模型和数据将在网页链接提供。
2. 网页链接{《EgoGen: An Egocentric Synthetic Data Generator》}

以第一人称视角理解世界是增强现实的基础。与第三人称视角相比,这种沉浸式视角带来了戏剧性的视觉变化和独特的挑战。合成数据增强了第三人称视角视觉模型的能力,但其在具身自中心感知任务中的应用在很大程度上尚未得到探索。
一个关键的挑战在于模拟自然的人类运动和行为,有效地引导具现摄像头捕获到3D世界的忠实自中心表现。
为了应对这一挑战,团队提出了一种全新的合成数据生成器EgoGen,它可以为自中心感知任务生成准确而丰富的真实训练数据。
EgoGen的核心是一种新颖的人体运动合成模型,它直接利用虚拟人的以自中心视觉输入来感知3D环境。结合避免碰撞的运动原语和两阶段强化学习方法,所提出的运动合成模型提供了一个闭环解决方案,其中虚拟人的具现感知和运动无缝耦合。
与以前的研究相比,所述模型消除了预定义全局路径的需要,并且直接适用于动态环境。结合易于使用和可扩展的数据生成管道,研究人员在三个任务中展示了EgoGen的效果:头戴式摄像头的映射和定位,自中心的摄像头追踪,以及从自中心视图中恢复人体网格。
EgoGen将完全开源,从而为创建真实的自中心训练数据提供实用的解决方案,并旨在成为自中心计算机视觉研究的有用工具。项目页面请访问这里。
3. 网页链接{《Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks》}
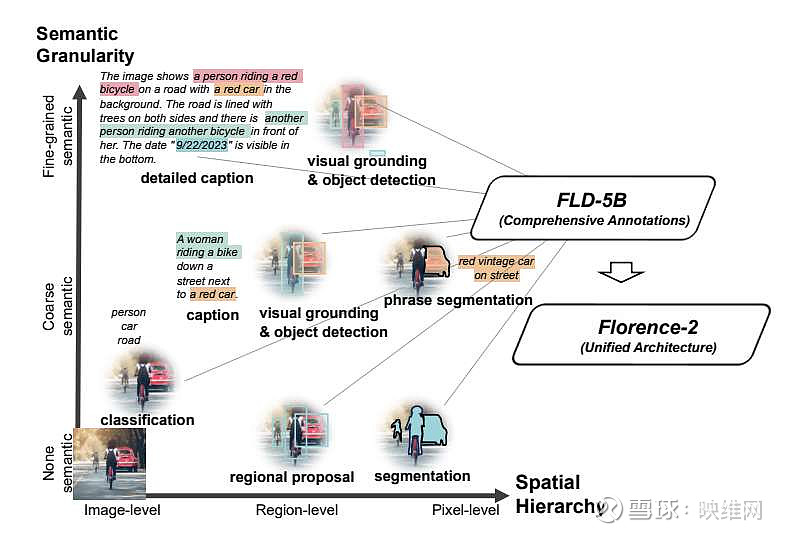
团队介绍了一种全新的视觉基础模型Florence-2。它具有统一的、基于提示词的表示,适用于各种计算机视觉和视觉语言任务。尽管现有的大视觉模型在迁移学习方面表现出色,但它们很难用简单的指令执行各种任务,这种能力意味着要处理各种空间层次和语义粒度的复杂性。
Florence-2旨在将文本提示作为任务指令,并以文本形式生成理想的结果。这种多任务学习设置需要大规模、高质量的注释数据。所以,团队共同开发了FLD-5B。FLD-5B采用自动图像标注和模型细化的迭代策略,在1.26亿张图像包含54亿个综合视觉标注。研究人员采用序列到序列的结构来训练Florence-2执行多用途和综合的视觉任务。对众多任务的广泛评估表明,Florence-2是一个强大的视觉基础模型竞争者,具有前所未有的zero-shot和微调能力。
4. 网页链接{《LISA: Reasoning Segmentation via Large Language Model》}

尽管感知系统近年来取得了显著的进步,但在执行视觉识别任务之前,它们仍然依赖于明确的人类指令或预定义类别来识别目标对象。这样的系统不能主动推理和理解隐含的用户意图。
在这项研究中,团队提出了一种全新的分割任务:推理分割。这个任务的目的是在给定复杂且隐式的查询文本的情况下输出分段掩码。另外,研究人员建立了一个包含一千多个图像指令掩模数据样本的基准,将复杂的推理和世界知识纳入评估目的。
最后,他们提出了LISA:Large Language Instructed Segmentation Assistant/大型语言指导分割助手。它继承了多模态大型语言模型LLM的语言生成能力,同时具有生成分割掩码的能力。研究人员用token扩展了原始词汇表,并提出了嵌入作为掩码的范式来解锁分割能力。
值得注意的是,LISA可以处理涉及复杂推理和世界知识的案例。另外,当只在无推理数据集训练时,它显示出稳健的zero-shot能力。同时,仅使用239个推理分割数据样本对模型进行微调可以进一步提高性能。定量和定性实验表明,所述方法有效地为多模态LLM提供新的推理分割能力。代码、模型和数据可在访问网页链接。
5. 网页链接{《MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild》}
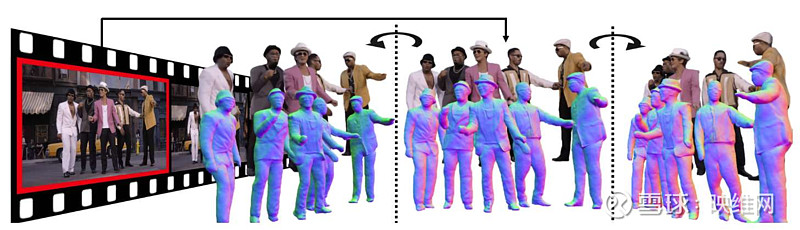
团队提出了的全新框架可以从单目in-the-wild视频中以3D形式重建多人。从单目in-the-wild视频中重建自然移动和交互的多个个体是一项具有挑战性的任务。要解决这个问题,需要在没有任何先验知识的情况下,精确地在像素级解开个人的纠缠。另外,它需要从短视频序列中恢复复杂而完整的3D人体形状,而这又加大了难度。
为了应对相关挑战,研究人员首先为整个场景定义了一个分层的神经表示,由个人和背景模型合成。他们通过分层可微体渲染从视频中学习分层神经表示。所提出的混合实例分割方法结合了自监督的3D分割和promptable 2D分割模块,从而进一步增强了这一学习过程,即便在紧密人类交互下都能产生可靠的实例分割监督。
另外,团队提出了一种基于置信度的优化方案来对人体姿态和外形进行交替优化。他们结合了有效的目标来通过光度信息来完善人体姿势,并对人体动力学施加物理上合理的约束,从而实现高保真度的时间一致3D重建。对方法的评估表明,所提出的方法优于现有技术。
6. 《SceneFun3D网页链接{: Fine-Grained Functionality and Affordance Understanding in}3DScenes》
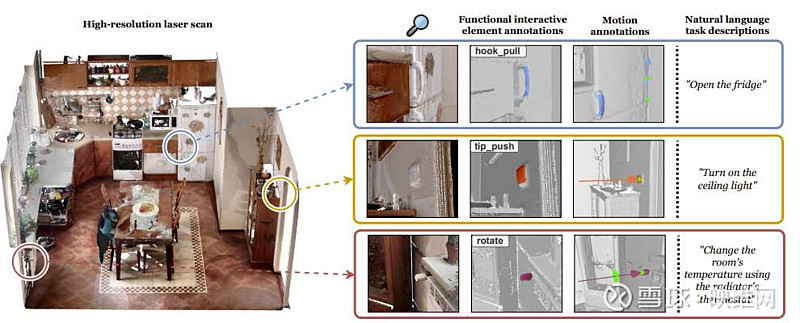
现有的3D场景理解方法主要集中在3D语义和实例分割。然而,识别对象及其组成只构成了迈向更细粒度目标的中间步骤。
所以,团队提出了SceneFun3D,这是一个拥有超过14.8k高精度交互注释的大规模数据集,涉及710个高分辨率真实3D室内场景。他们提供提供过了运动参数信息,描述了如何与相关元素交互,以及一组涉及在场景上下文中操纵它们的任务的自然语言描述。
为了展示数据集的价值,研究人员引入了三个新的任务:功能分割;任务驱动的affordance grounding;以及3D运动估计。他们同时采用现有的最先进的方法来解决它们。
---
原文链接:网页链接