大模型三要素:
1.算力(训练迭代次数)
2.数据规模(训练集的tokens数)
3.参数规模
三要素中任意要素的指数增长,都会带来模型性能的线性增长
增长收益:参数规模>数据规模>算力
!也就是说,要提升模型性能,未来的投入要指数级别的增加了
GPU性能(计算速度、显存大小、互联性能)
GPU价格极其昂贵,并且供不应求
次顶级GPU A100,1万美元
顶级GPU H100,3万+美元
英伟达8个A100协同工作的DGX A100,20万美元
亚马逊AWS租用8个A100的实例,一天461美元
训练成本
175B参数模型OPT(Meta AI),1000个A100训练2个月
176B参数模型Bloom(Hugging Face),385个A100训练3个月
175B参数的GPT3,训练一次460万美元
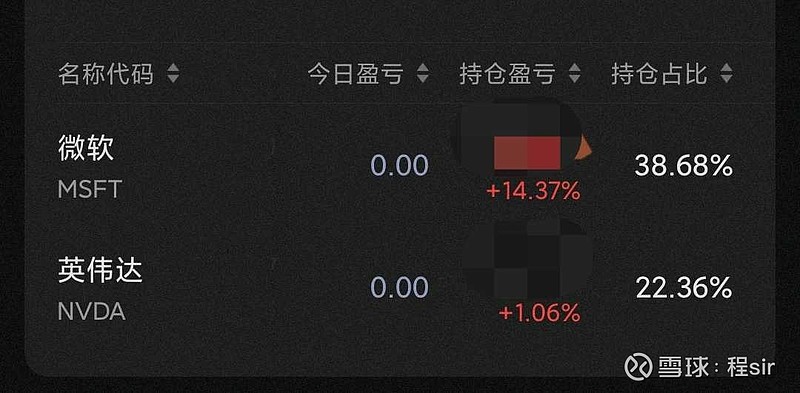
$英伟达(NVDA)$ 建仓了,虽然看起来不是很便宜,但是相信这一次的变化是颠覆性的。各家都做大模型,鹿死谁手其实不知道,但是英伟达无论如何都应该是赢家