
理工科 STEM 技能,是解决真实世界中诸多问题的基础。譬如,探索蛋白质结构、证明数学定理、发现新药物等。(编者注:STEM,即科学、技术、工程和数学四门学科英文首字母的缩写。)
而对于人工智能领域来说,理解视觉-文本的多模态信息,则是掌握 STEM 技能的关键。
可是,现有的数据集主要集中在检验模型解决专家级别难题的能力上,难以反映模型在基础知识方面的掌握情况。并且,其往往只考虑文本信息而忽略视觉信息,又或者只关注 STEM 中某单一学科的能力。
另外,由于缺少细粒度的信息,该领域的科学家也无法更好地分析与改进神经网络模型存在的薄弱之处。
所以,模型在这种情况下生成的内容,既无法让人充分信任,又不能帮助指导未来模型开发的方向。
更重要的是,由于缺乏和人类表现相关的数据,因此科学家也不可能获取到更具实际意义的模型表现参考,严重阻碍了人工智能的健康发展。
为了攻克上述局限性,近期,来自北京大学和美国圣路易斯华盛顿大学的研究团队,不仅成功完成了首个多模态 STEM 数据集的构建,还在此基础上实现对大语言模型与多模态基础模型的评测。
结果发现,即使是目前最先进的人工智能模型,其 STEM 基础水平也存在较大的提升空间,尚不具备解决更有难度的现实问题的能力。也就是说,与人类智能相比,目前人工智能的水平还有一定差距。
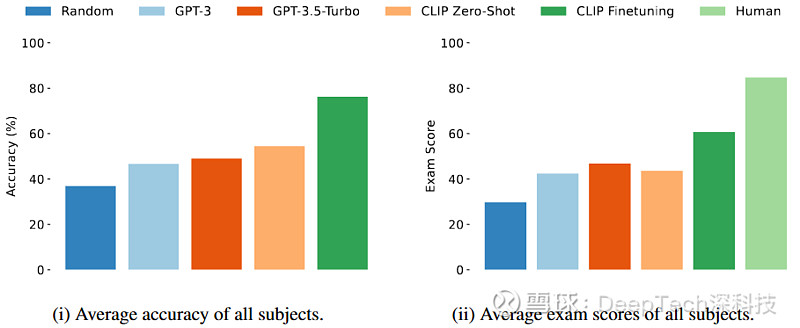
图丨综合评测效果(来源:ICLR 2024)
近日,相关论文以《测量神经网络模型的视觉-语言理工科技能》(Measuring Vision-Language STEM Skills of Neural Models)为题收录于 2024 国际表征学习大会(ICLR 2024,International Conference on Learning Representations 2024)上[1]。
据悉,该会议将于今年 5 月 7 日至 5 月 11 日在奥地利的首都维也纳召开。
STEM 数据集相关资源如下。
评测链接:网页链接
数据集页面:网页链接
代码 GitHub:网页链接
北京大学博士研究生沈剑豪和袁野是共同第一作者,圣路易斯华盛顿大学王晨光助理教授和北京大学张铭教授担任共同通讯作者。王晨光助理教授博士毕业于北京大学,导师是张铭教授。

图丨相关论文(来源:ICLR 2024)

搭建 STEM 数据集,全方位评测神经网络模型的基础理工科能力
据王晨光介绍,课题组在确定研究目标和题目之后,便开始着手收集数据。
一向擅长于算法研究的团队成员,在面对爬虫编写、数据清洗和去重等工作时不免有些犯难。尽管如此,他们还是迎难而上,设计了多种用于数据清洗和去重的规则,最终成功获得了首个多模态 STEM 数据集。

图丨左起;王晨光、张铭、沈剑豪、袁野、Srbuhi Mirzoyan(来源:课题组)
值得一提的是,该数据集包含 448 个 STEM 技能,共 1073146 道题目,是目前涵盖面最广、包含题目最多的多模态 STEM 题目数据集。

图丨相关论文(来源:ICLR 2024)
接着,他们开始针对数据集进行评测与分析。
由于该数据集包含科目(科学、技术、工程、数学)、技能和年级三个维度标签,因此研究人员选择从这三个维度切入,对每个维度的数据数量分布、问题类型分布、问题长度分布等信息进行了详尽分析。
与此同时,他们也针对每个科目,按照 6:2:2 的比例,划分了训练集、验证集与未公开标签的测试集。
随后,研究人员又设计了模型评测方案。
其中,在选择评测指标时,他们除了关注准确率,还重点使用全球范围内最被认可的在线习题网站之一(网页链接)的考试分数。
后者是基于该网站千万用户的真实考试成绩得出的,与学生对知识的掌握程度呈正相关。当分数达到 90 以上(通常是小学生水平)时,就代表学生掌握了该技能。
“我们让模型模仿考生在线答题,再将得到的考试分数与真实人类的考试结果进行比较。”王晨光表示。
这也正是该工作的一大亮点。原因在于,过去将人类的表现与人工智能做比较时,前者都是由相对较小的样本(例如几百到几千人)总结出的,而该团队的结果却是基于千万量级的数据得到的,可信度更高。
然后,在模型评测环节,研究人员选择使用当前主流的大基础模型,包括 OpenAI 的多模态 CLIP 模型,以及大语言模型 ChatGPT 的 GPT3.5-Turbo 版本。
前者根据模型判断问题选项与图片的匹配程度来做出选择,后者则利用字幕模型为图片生成描述,并利用语言模型选择回答。
“我们评测了不同规模的 CLIP 模型与 GPT3.5-Turbo 模型,发现在 0 样本的设置下,模型的错误率很高。这表明现有模型无法直接真正地掌握这些知识。”王晨光表示。
进一步地,他们又利用划分出的训练数据集,对 CLIP 模型进行了微调,发现微调后的模型取得了显著的效果提升,综合准确率从 54.4% 提升至 76.3%。不过,这离 90 分依然有一定差距。
除此之外,该课题组还对模型结果的各个侧面进行了分析。
具体来说,首先,在年级层面,他们发现模型的测验分数随着题目所属年级的升高而降低,这符合年级越高的题目难度就越高的预期。

图丨测验分数随年级变化(来源:ICLR 2024)
其次,通过模型在不同技能上的评测表现,他们发现模型在抽象知识与复杂推理任务上的表现欠佳。
另外,过去的经验表明,模型应该对正确答案有着较高的预测置信度,这代表着模型的校准度较好。
“我们发现在我们的数据集上微调过的模型,表现出了良好的校准性,模型的置信度与准确率呈现清晰的相关性。”王晨光说。
另一方面,他们在研究模型规模与效果之间关系的过程中,也发现了清晰的正相关关系。
与此同时,他们还分析了模型表现与问题长度、问题类型、选项数量等其它因素之间的关系,发现随着问题变长、选项数量变多和样例数量变少,模型的表现都会下降。
除此之外,他们也评估了准确率与测验考试分数这两种指标的相关性,发现它们同样呈现出显著的正相关。
“最终,在整体的评价指标上,我们确认即使是微调过的模型,与人类对应年级学生水平相比也有显著差距。基于此,我们仍然需要寻找更有效的方法,使模型掌握 STEM 知识技能。”王晨光说。

图丨与人类表现比较(来源:ICLR 2024)

尝试推出更多评测大语言模型的数据集,加快通用人工智能实现的进程
显而易见,在该项研究中,STEM 数据集发挥了关键作用。
它不仅有利于模型增强 STEM 的基础知识,还能帮助研究人员评估模型对于基础 STEM 技能掌握的程度,并通过细粒度的数据分析有针对性地改进模型。
王晨光表示,他和团队期待该数据集可以进一步推动当前多模态大模型的研究,朝着模型能够充分理解 STEM 技能、解决真实场景下 STEM 问题的目标更进一步。
并且,也希望发布的测试集可以作为评测人工智能基础模型能力的标准评测之一,得到社区的广泛使用。
“更重要的是,我们提供的与大规模人类(主要是小学生)真实水平的比较,可以作为未来模型开发的目标和参考,以加快通用人工智能目标实现的进程。”他说。
目前,基于该数据集,该课题组已经成功评测了神经网络模型在基础教育中的理工科能力。
接下来,他们一方面计划继续收集数据,并尝试推出诸如人文学科、社会学科等领域的数据集,以更好地评测大语言模型在其他关键学科上的能力。
在这方面值得关注的是,该团队最近已经提出了一个新的社会学科数据集 Social,包含较大规模的文本评估数据,可用来评测大语言模型的社会学科基础能力。
进一步地,还设计了一种多智能体交互的方法,能够增强大语言模型在 Social 数据集上的表现。
相关论文以《衡量大语言模型的社会规范》(Measuring Social Norms of Large Language Models)为题收录于计算语言学协会北美分会 2024 年年会(NAACL 2024,2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics)上[2]。
据悉,该会议将于今年 6 月 16 日至 6 月 21 日在墨西哥的首都墨西哥城召开。
另一方面,他们也打算通过研究模型在细粒度数据集上的表现,找出模型能力不足的部分,并研究如何改进。
此外,还希望通过结合检索的 RAG 方法、设计特殊的模型架构和训练方法,来进一步增强模型的基础能力。
“我们相信,只有先在基础理工科和文科领域实现突破,扎实打好基础,人工智能才有被进一步应用的可能性。”王晨光如是说。
参考资料:
1.J.,Shen,Y.,Yuan,S.,Mirzoyan.et al. Measuring Vision-Language STEM Skills of Neural Models.ICLR 2024. 网页链接
2.Yuan, Ye, et al. Measuring Social Norms of Large Language Models. NAACL 2024. 网页链接
运营/排版:何晨龙


01/ 科学家提出GenAINet框架,能让工业机器人互换经验,让AI网络成为综合智能体
02/ 产氨量再创新纪录,科学家将合成氨稳定时间提高30倍,300小时生成4.6克氨,可用于氢能储备
03/ 同时获得T细胞与B细胞克隆空间信息,科学家提出新型空间转录组学技术,或能预测免疫细胞作用机制
04/ 科学家提出脑疾早期评估新工具,只需安装5个传感器,就能实现新生儿不安运动数字化
05/ 浙大团队发现全新促癌通路,提出胰腺癌治疗新靶点,正联合业界研发新型小分子药物
