扫码了解详情
今年上半年,DeepMind 推出了名为 Gato 的人工智能模型。该模型可用于执行不同模态下(文本、图像、视频、音频等)复杂的计算任务,如生成对话与字幕、玩视频游戏、控制机械臂搭积木等。
图 | Gato 模型(来源:DeepMind)
简单来讲,Gato 凭借单一架构的网络模型就能完成 604 种不同的操作任务,是一款通用型的人工智能模型。例如,Gato 应用于游戏场景中时,不必为每个游戏单独训练智能体模型,只需运用同一套模型参数便可以玩不同的游戏。
图 | Gato 生成对话与字幕(来源:DeepMind)

规模最大化理论备受争议
在 Gato 发布之时,DeepMind 的首席科学家南多·弗雷塔斯(Nando de Freitas)还曾发布 Twitter 声明,支持 Gato 所采用的规模最大化理论。他认为,更大的模型会带来更强的性能,就像 Gato 所具有的强大功能一样。
图 | 盖瑞·马库斯(Gary Marcus)(来源:Robust.AI 公司)
然而最近,人工智能专家、Robust.AI 公司的创始人兼 CEO、纽约大学教授盖瑞·马库斯(Gary Marcus)对“Gato 模型基于规模最大化可实现通用人工智能”的观点表示质疑。
与弗雷塔斯的观念相反,马库斯认为,仅通过扩大模型规模无法确保计算结果的正确性。因此,其并不能从根本上提升性能,从而实现真正的人工智能。
马库斯认为,Gato 不能实现通用人工智能有三个原因:第一,现阶段用以支撑规模最大化理论的数据量不足;第二,实现规模最大化消耗的计算资源过多;第三,无法从规模上扩展很多重要的任务,例如对同一句话在不同语境下的理解,而不仅仅是其语法和语义。
后文提到的实践也证明了马斯库的观点,Gato 模型对很多任务执行得不好,无法通过试错改进提升下一次策略的执行。
业内人士也普遍认为规模最大化理论过于偏激,尽管 PaLM、DALL-E 2、Flamingo 和 Gato 等新人工智能模型的出现增强了该观点的可信度,但是并不能证明该理论一定正确。
他们同马斯库一样,认为真正的 AI 模型应该具备像人类一样执行命令的能力,而不是在模型中直接包含人类已经发现的内容。人工智能工程师在已经创造出的模型中直接添加内容,不会创造出新的模型,因此,不能仅仅依赖于扩大模型规模来实现人工智能中的模型创新。
实际上,规模最大化理论并没有被准确的定义。就目前的理解,它意味着工程师无需创新算法模型,只需要对现有模型的参数规模进行拓展(例如无脑加深网络深度,或对模型进行横向扩展),就能实现通用人工智能。
这种理论显然并不正确,实践证明,PalM、 DALL-E 2、 Flamingo、Gato 等模型依然需要算法模型的创新,而不仅仅是计算规模的堆砌。
到目前为止,还没有人能够给出准确的解释,以说明需要将模型扩大和算法创新到何种程度才能称作规模最大化,因此很难判断规模最大化理论究竟是对是错。
因此,尽管扩充模型规模在通用人工智能领域是有必要的,但是并不是唯一途径。

模型的训练与应用流程
虽然 Gato 的规模最大化理论备受争议,但就 Gato 模型本身而言,其在算法上具有一定创新之处,而且它具有强大的功能,应用范围也相当广泛。在构建 Gato 模型的过程中,来自不同任务和模态的数据被序列化为扁平的数据单元,并由类似于大型语言模型的神经网络转换器(Transformer)模型进行批处理。在此过程中,模型的一部分损失函数被选择性地隐藏,以使得 Gato 只对行为决策和文本目标进行学习。
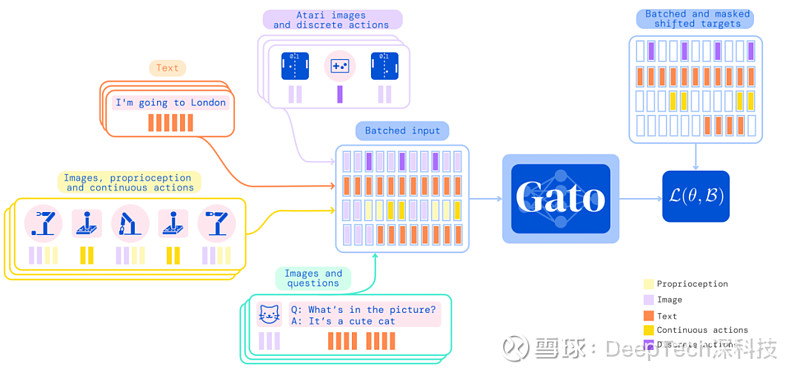
图 | Gato 的训练流程(来源:DeepMind)
在 Gato 模型实际部署运行时,对输入数据进行标记化处理(标记化是指数据的向量表示,例如把一个单词或者一句话表示为一个数值向量,称为 tokenization),产生初始的输入序列。
然后利用环境(不属于 Gato 的一部分,而是要学习的任务,例如游戏本身)生成第一个结果,该结果被标记化并附加到最初序列中,形成动作向量。然后,Gato 模型对动作向量进行“自回归”(一种从统计上处理时间序列数据的方法)式地采样,每次生成一个新的标记化序列。
所有标记序列被采样后,模型就会将动作向量进行解码(可以理解为“反标记化”)并发送到任务环境中,在该环境之中执行相关步骤并产生新的观察结果。然后,模型会重复这个过程,使其动作向量不断更新,直至结果收敛。
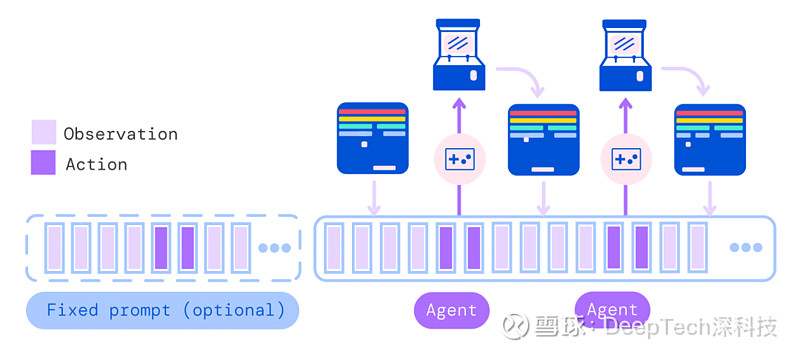
图 | 将 Gato 部署为控制策略(Control Policy)的流程(来源:DeepMind)
Gato 不仅能在自然语言和图像数据集上训练,还能使用大量其它模态的数据集进行训练。这些数据包括从仿真环境和真实环境中获得的经验数据。
为验证 Gato 能否执行全新的任务,研究者分别从多个不同的环境中拿出了新的任务,对单个任务下的训练好的模型参数再训练一定轮次,进行参数优化和微调,然后在指定任务上对模型进行了性能测试。
结果表明,在很大比例的任务中,Gato 都可以通过不断的学习与适应来执行新任务并获得人类专家水平的分数。
然而,由于标记化序列长度过长,以及计算机的内存限制,任务在执行的过程中会存在很多问题,例如速度过慢等。
模型参数规模的扩张是否是开发通用智能的唯一途径,这个问题尚无定论。但目前很明显的是,以 Gato 为代表的众多大规模人工智能模型,距离通用人工智能还有很长的一段路要走。

由 DeepTech 携手《麻省理工科技评论》重磅推出的《科技之巅:全球突破性技术创新与未来趋势(20 周年珍藏版)》已开启预售!点击下方海报可购买图书!