抽取式文本摘要一般在高资源语言(如英语)方面能获得较好效果,这不同于一些缺乏大量标注数据的小语种数据集。
文本摘要指将文本进行概括、总结,往往需要用到一种抽取式方法,即从原文中抽取若干语句形成摘要。
(来源:Pixabay)在零样本多语言提取文本摘要中,模型通常在英语摘要数据集上进行训练,然后应用于其他语言的摘要数据集。但由于不同语言之间存在语法或语义差异,在英语数据集上创建的单语标签在其他语言的数据集上可能不是最优的。
为此,中国科学院和微软亚洲研究院联合提出了一种神经标签搜索摘要(NLSSum,Neural Label Search for Summarization)模型。
近日,相关论文以《零样本多语言提取摘要的神经标签搜索》(Neural Label Search for Zero-Shot Multi-Lingual Extractive Summarization)为题发表在国际计算语言学学会(ACL,Association for Computational Linguistics)会议上。ACL 成立于 1962 年,是计算语言学和自然语言处理领域最具权威性会议之一。该论文也于 2022 年 4 月 28 日提交到 arXiv 上。
研究者在论文中称:“本次研究是基于零样本的多语言抽取式文本摘要,目的是将在高资源语言上学习的模型(如英语)转移到相对低资源的语言(如土耳其语)。具体方法是在英语摘要数据集上训练一个提取模型,再将这个训练好的模型应用于一种不同语言的文档,即提取另一种语言的文档的句子。”
近来,大型预训练的多语言模型,如 M-BERT、XLM 和 XLM-R,在零样本多语言自然语言理解任务上表现出色。在预训练过程中,它们将不同语言的表示投射到相同的向量空间中,使得在微调过程中跨不同语言的迁移学习更容易。
在文本摘要中,大多数数据集只包含人为编写的抽象摘要作为基本事实,需要将这些数据集转换为可提取的数据集。因此,研究人员采用贪婪式启发算法,通过最大化候选摘要集之间的 ROUGE(用于评估自然语言处理中的自动摘要指标,Recall-Oriented Understudy for Gisting Evaluation),每次在候选摘要集与黄金摘要之间添加一个句子,当文档中剩余的句子都不能再增加 ROUGE 时,该过程停止。
贪婪式启发算法在英语数据和翻译后的数据上产生不同的标签,这些标签可以相互补充。该差异被定义为单语标签偏差,这是进一步提高零样本多语言摘要性能的关键。
如下表所示例子,英语句子很可能被选为一个摘要句子,因为它与英语参考语(高ROUGE)有很大的重叠;而当文件和摘要被翻译成德语时,句子和摘要之间的 ROUGE 明显降低。
 图 | 对不同语言的单语标签偏差(来源:arXiv)
图 | 对不同语言的单语标签偏差(来源:arXiv)
针对多语言零样本中的单语标签偏差问题,研究人员除了提出 NLSSum,还提出一种多语言标签(Multilingual Label)标注算法 。
同时,为了解决上述问题,他们还根据英文摘要数据集,使用不同的机器翻译方法创建多组标签,并使用 NLSSum 为不同数据集中的这些标签搜索合适的权重。
具体地说,在 NLSSum 中,研究人员试图用两个神经权重预测器来搜索这些标签的层次权重(句子级和设置级),这些标签权重被用来训练摘要模型。在训练过程中,将两个神经权值预测因子与总结模型联合训练。
NLSSum 只在训练和推理过程中使用,可以简单地将训练后的摘要模型应用于另一种语言的文档。该过程可分为以下五个步骤:
1.多语言数据增强。这一步旨在提高提取模型的多语言传输能力,并减轻训练(在英语上)和推理(在未经预习的语言上)之间的差异。
2.多语言标签生成。提取模型由多语言标签监督,四组标签组成。
3.神经标签搜索。在这一步骤中,研究者为不同策略的标签设计了分层的句子级和设置级的权重。最终的权重用加权平均值计算,并分配给相应的句子。
4.微调。通过加权的多语言标签(步骤3生成)的监督,对增强的英语文档(步骤 2 生成)进行微调。
5.零样本。应用对英语数据进行微调的模型(步骤 4 生成)来提取目标语言文档上的句子。
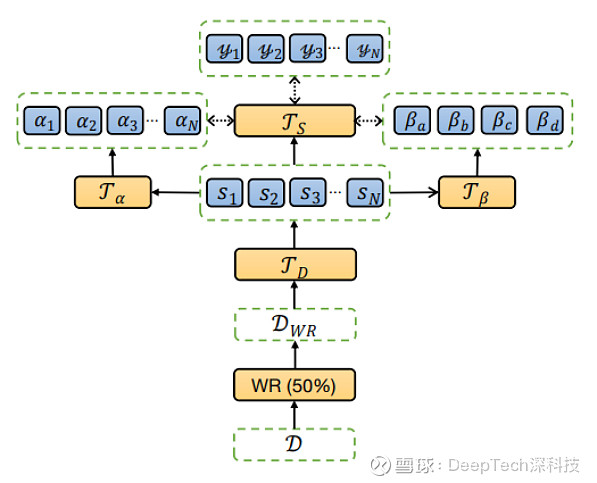 图 | NLSSum 概述。输入的英文文档由 50% 的单词替换进行论证,输出由多语言标签监督(来源:arXiv)
图 | NLSSum 概述。输入的英文文档由 50% 的单词替换进行论证,输出由多语言标签监督(来源:arXiv)
最终结果显示了 NLSSum 的有效性,它在首个大规模多语言摘要数据集 MLSUM 上显著优于原始XLMR模型2.25 个 ROUGE-L(L指代Longest Common Subsequence,最长公共子序列)评分。人工评估也表明,NLSSum 模型比其他模型更好。
研究者还提到,这是第一个研究零样本多语言提取摘要中单语标签偏差问题的工作,即解决将文档、摘要从英语翻译成其他语言时,重新转换的标签会随着文本表示的转换而变化问题。他们为此引入多语言标签生成算法,以提高多语言零样本模型的性能。同时提出 NLSSum 来搜索不同标签集的合适权重。-End-

参考:网页链接