鞭牛士 今日报道
全球知名的开源平台HuggingFace今日公布了开源模型榜单,多款中国造开源模型上榜。其中,阿里新开源的Qwen2-72B荣登榜首。
与此同时,HuggingFace联合创始人兼首席执行官Clem也在社交平台上发文,称Qwen2-72B是王者,中国在全球开源大模型领域处于领导地位。
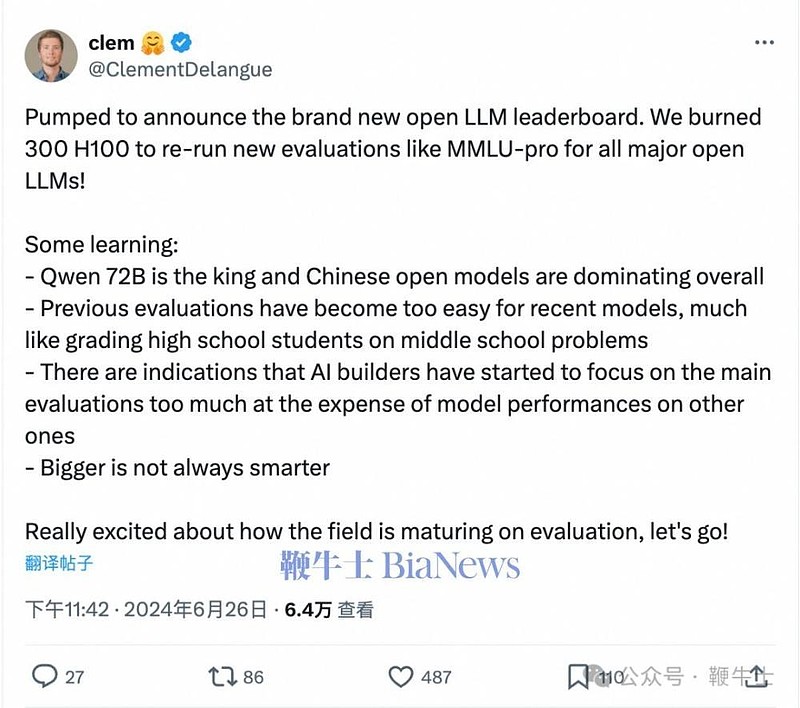
本次评估使用了300块H100对目前全球100多个主流开源大模型,在BBH、MMLU-PRO、MUSR等六个基准测试集上进行了全新评估。
据介绍,本次重新评估的原因是,许多开发者过于追求排行榜的名次,导致在模型训练过程中过度依赖评估集数据,再加上过去的评估标准对于模型来说过于简单,因此本次评估加大了难度标准,旨在检验各家大模型的真正实力。