没什么太新的东西,没有air pocket,担心代际切换带来观望情绪的可以洗洗睡了,H200和B系列GPU,那是你想买就能买得到的嘛。。
核心要点总结
- 需求强劲 & 不用担心GPU代际过渡导致收入增速放缓:H100供应改善,H200和Blackwell将供不应求,预计需求可能会在明年的大部分时间里继续超过供应。现在还处于算力部署的早期阶段,时间就是金钱,所以大家不会等待/观望最新架构的GPU。
- B系列GPU发货进展超预期:二季度已经开始量产、三季度爬坡、四季度部署到数据中心,比预期快了1季度。
- 主权AI预计将带来大几十亿美元的收入。
- 在英伟达AI基础设施上每投入1美元,云服务商就有机会在4年内通过GPU出租赚取5美元。
- 网络方面,除了IB网络,英伟达也在大力拥抱以太网,针对 AI优化的Spectrum-X(以太网交换机)预计在一年内带来几十亿美元的收入。
- 其他业务基本上也是围绕AI在叙事。
- Jensen的关键词依然是加速计算取代传统计算(新的工业革命)、主权AI、AI工厂、加速计算性能高能耗低成本低、推理负载增长快且推理很复杂,跟公开演讲讲到的东西差不多。
拆股:1拆10,6月10日之后开始。
业绩
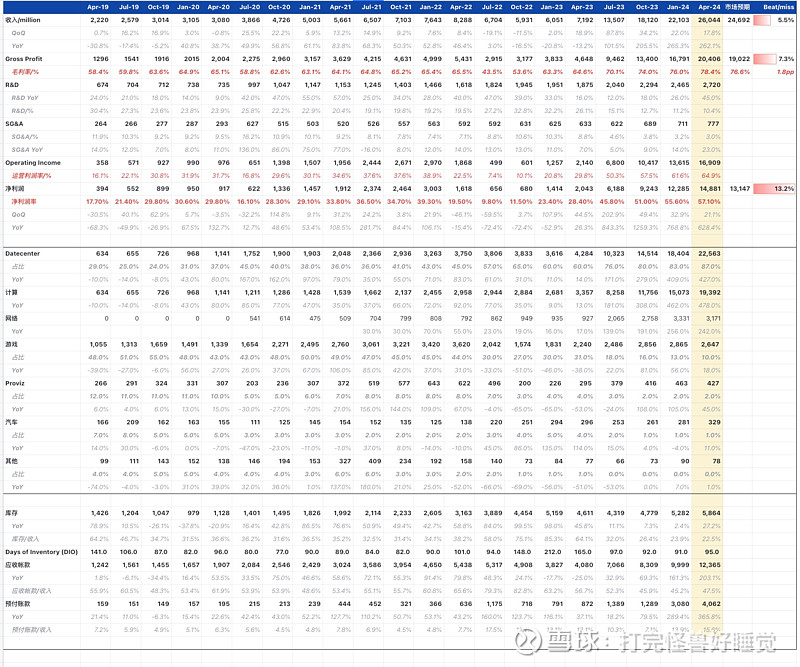
数据中心收入达到226亿美元,创下了新纪录,环比增长23%,同比增长427%,增长来源于对Hopper GPU持续强劲的需求。计算收入同比增长超过5倍,网络收入同比增长超过3倍。环比增长是由所有类型的客户推动的,以企业和消费互联网公司为首。网络收入环比下降,主要是发货节奏导致的,依然是供不应求。
游戏:收入为26.5亿美元,环比下降8%,同比增长18%,与我们对季节性下降的预期一致。GeForce RTX Supers GPU市场反响强烈,最终需求和渠道库存在产品范围内保持健康。
汽车领域:收入为3.29亿美元,环比增长17%,同比增长11%。增长主要是由于全球 OEM 客户的 AI 驾驶座舱解决方案的增长以及英伟达自动驾驶平台的强大性能。
ProViz:收入为4.27亿美元,环比下降8%,同比增长45%。生成式AI和Omniverse工业数字化将推动专业可视化增长的下一波浪潮。
指引
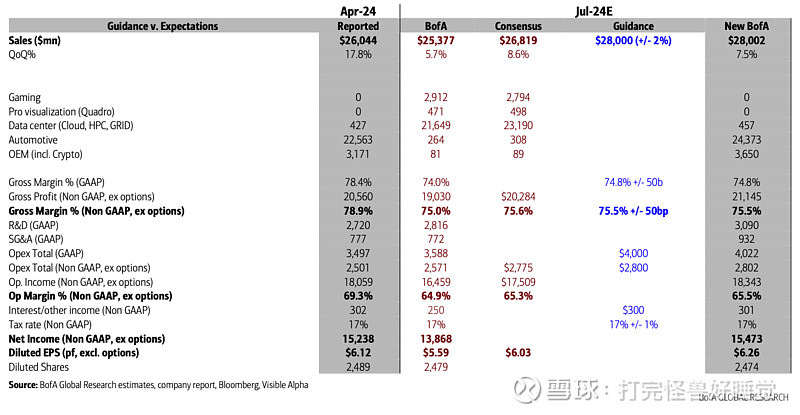
总收入预计将达到 280 亿美元,上下浮动 2%。
预计所有市场平台都将实现环比增长。
GAAP 和非 GAAP 毛利率预计将分别为 74.8% 和 75.5%,上下浮动 50 个基点。与我们上个季度的讨论一致,对于整个财年,我们预计毛利率将在75%左右。
业绩会重要内容摘要
业务数据
本季度CSP占数据中心收入的45%左右,过去4个季度推理占数据中心收入的40%左右。
在英伟达AI基础设施上每投入1美元,云服务商就有机会在4年内通过GPU出租赚取5美元。7000亿参数的Llama 3,单个H200服务器可以每秒提供24000个token,支持超过2400个用户同时使用。这意味着当前价格下每投入1美元购买H200服务器,提供Llama 3 token的API提供商在四年内可以产生7美元的收入。
支持特斯拉将AI训练集群扩展到35000个H100的规模,据此训练出了FSD V12。预计今年汽车行业将成为英伟达数据中心业务最大的企业垂直领域方向,带来几十亿美元的收入。
消费互联网公司强劲增长,生成式AI嵌入到更多的应用程序中,随着模型复杂性、用户数、用户用量的增长,推理需求将会持续增长,需要的AI算力增长。
主权AI的收入今年可以达到大几十亿美元。
H100的供应有所改善,但H200、Blackwell的供应依然受限,H200和Blackwell的需求远远超过了供应,预计需求可能会在明年的大部分时间里继续超过供应。
H200 二季度开始量产出货,Blackwell已经开始全面投产,生产发货将在第二季度开始(这里比预期的要快,之前预计发货将在三季度末端开始),三季度爬坡,客户在四季度建立数据中心,今年会看到很多 B系列的收入。
Blackwell平台有上百种定制方案,对应从训练到推理、从x86到Grace CPU、从以太网到InfiniBand网络,从风冷到液冷的各种场景。客户包括亚马逊、谷歌、Meta、微软、OpenAI、甲骨文、特斯拉和Xai。
网络方面,除了IB网络,英伟达也在大力拥抱以太网,针对 AI优化的Spectrum-X(以太网交换机)预计在一年内带来几十亿美元的收入。
其他业务基本上也是围绕AI在叙事:游戏GPU强调了AI模型可以在上面运行得很好,ProViz业务强调了Ominiverse和GenAI将推动该业务迎来增长浪潮,汽车业务同样也是强调自动驾驶/智能座舱支持的好。
宣布以10 比 1 拆股,6 月 10 日是按分割调整后的基础交易的第一天。
Jensen
没有太多新的东西。主题/关键词依然是加速计算取代传统计算(新的工业革命)、主权AI、AI工厂、加速计算性能高能耗低成本低、推理负载增长快且推理很复杂。跟公开演讲讲到的东西差不多。
从通用 CPU 到 GPU 加速计算,从指令驱动的软件到理解意图的模型,从检索信息到执行技能,以及在工业层面,从生产软件到生成 token。Token 生成将推动 AI 工厂多年的建设。除了云服务提供商,生成性 AI 已经扩展到消费互联网公司和企业、主权 AI、汽车和医疗保健客户,创造了多个数十亿美元的垂直市场。
问答环节的浓缩版
Blackwell 现在全面投产了,发货和交付时间大概是什么时候?
生产发货将在第二季度开始,第三季度爬坡,客户在第四季度建立数据中心。今年会看到很多 B系列的收入。
Blackwell的部署比Hopper更复杂,是否意味着过渡需要的时间更久?
不需要。因为Blackwell GPU是向后兼容Hopper的,无论是软件栈还是硬件的电气和物理特性,所以客户很容易从安装Hopper GPU的数据中心过渡到Blackwell。
Blackwell 有多种配置,很灵活。GB200 将会是非凡的。
如何确保产品得到充分利用,而不是因为供应紧张、竞争或其他因素而出现提前拉货或囤积行为?
当前的状态:GPU的需求还是很大,因为有很多多模态大模型在跑,还有很多AI初创公司,还有主权AI的需求。客户给我们施加了很大的压力,要求我们尽快交付并建立好系统。需求真的非常高,它超过了我们的供应。
从长远来看,需求也很旺:我们正在完全重新设计计算机的工作方式。计算机不再仅是由指令驱动的计算机,它是一个理解意图的计算机,它理解我们与它互动的方式、理解我们的意图、有能力进行推理、迭代处理计划并提出解决方案。这将改变全世界的计算堆栈。
H200 和 Blackwell 产品有很大的需求,在过渡到这些产品时,H100 是否会有所暂停?——不会
本季度对 Hopper 的需求在不断增长,预计在一段时间内需求将超过供应,因为我们现在正在过渡到 H200、Blackwell,每个人都急于让他们的基础设施上线,原因是因为他们正在省钱和赚钱,他们希望尽快做到这一点。
关于竞争的问题,许多云客户已经宣布了他们自己的ASIC,从中期到长期来看,您是否将他们视为竞争对手?
英伟达可以提供全流程的解决方案;英伟达解决方案的TCO更低;每个云中都部署了英伟达GPU,我们更通用,对开发人员更友好;英伟达提供的是系统级解决方案,而且在不断优化这个系统,CSP只有一个芯片。
新产品升级太快了,客户买了老的产品,一年之后就有新的了,老产品就不“香”了,如何看待这种情况?
还处于建设算力的早期阶段,这个时间客户要的就是快速部署,其他的是次要的。
时间非常宝贵,你快速部署了算力,理论上就能更快达到新的里程碑,成为AI的领导者(大模型厂商卷进展)。所以问题是,你想做一次又一次提供开创性 AI 的公司,还是提供提高了0.3%的公司?所以领导地位非常重要,训练时间非常重要。
我们为什么可以一年一迭代?我们有能力构建整个AI基建,我们知道哪里可以优化、怎么优化。
神经网络的训练和推理是否未来会固化,这样就可以用定制的ASIC,以更低的成本、更高的效率来运行这些工作负载,这种风险大吗?——不大
生成式人工智能的每一次进步和人工智能的发展,都要求我们不能只为一个模型设计一个小工具,而是要为整个领域、整个领域的属性设计一个真正好用的东西,但又要遵循软件的第一原则:软件会不断发展,软件会不断变得更好、更大。我们相信这些模型的扩展性,我们将在接下来的几年里轻松地将模型规模扩展一百万倍。
平台的多功能性确实是关键,如果你太脆弱、太具体了,你还不如直接构建一个 FPGA 或者构建一个 ASIC 或类似的东西,但那几乎不是一台计算机。
GB200 系统的需求很大,历史上英伟达的系统业务相对较小比如GH200,为啥GB200需求这么大?
GB200性能、能耗更优,Blackwell有上百种不同的配置,很灵活。
英伟达推出了ARM的Grace CPU来吃x86服务器CPU的份额,尽管x86CPU的性能很好,同样的事情会不会出现在客户端(个人电脑)的市场?
为什么推Grace CPU?实现更好的性能,例如统一内存、可以构建NVL72这样的极致压缩的系统。有架构原因,有软件编程原因,还有系统原因。
微软发布的AI PC很棒,ARM CPU也可以和我们的游戏显卡很好的配合,如果我们看到了类似Grace CPU那样的机会我们会继续探索。
展望未来,未来十年需要解决什么摩擦?也许更重要的是,你今天愿意和我们分享什么?
保持着一年推出一代GPU的节奏,快速升级网络技术,全力以赴地发展以太网。
新的硬件都可以运行CUDA和我们的软件栈。而且我们会不断升级软件堆栈,所以即使你什么都不做,你的硬件也可以运行得越来越快。如果你在我们的架构上进行研发,未来你会看到我们的硬件进入更多的云和数据中心,你研发的东西在各家的云上都能跑。
我们带来的创新将一面提高能力,另一面降低总拥有成本(TCO)。