昨天Nvidia GTC发布会,老黄重磅推出GB200新产品,号称72个GPU直接通过铜缆互联,组成一个集群Giant GPU,提升了30倍的性能。A股早上开盘吓尿了,中际旭创、新易盛、天孚通信这三家直接低开。那么,GB200是否真的会降低光模块的需求吗?
AI算力集群
将大量GPU芯片联在一起,组成一张大规模的并行计算集群,实现数以亿级的矩阵数学运算,从而使得几万亿参数的大模型AI训练成为可能。
GPU在一起,根本的诉求就是零延时互相访问对方的内存空间,就好像感觉在自己家里面一样。为了实现这个目的,AI算力集群,根据规模可以分成几个方案:
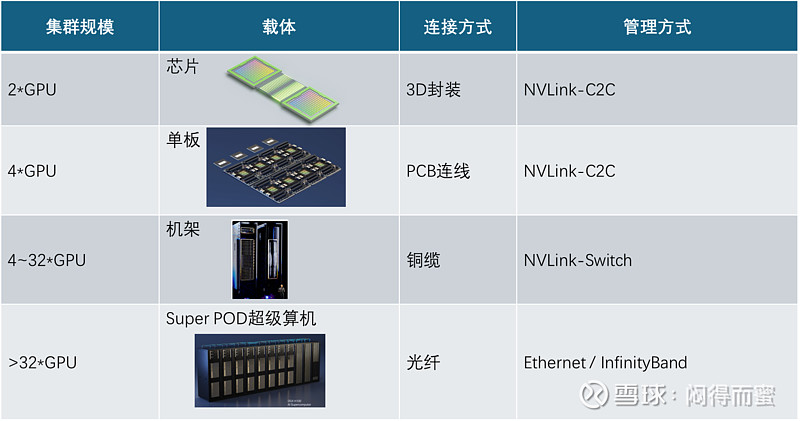
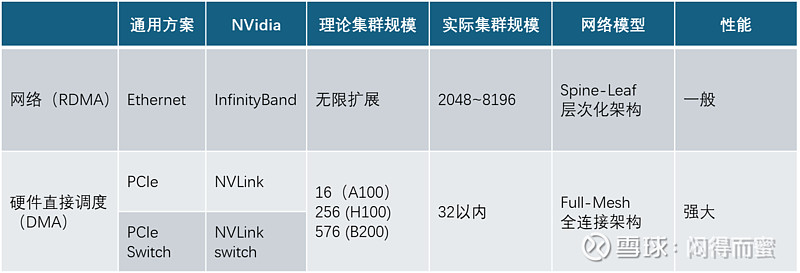
这四种方案,从上往下,集群的并发度效果越来越差、规模越来越大,鱼和熊掌不可兼得!不同集群内部架构不相同,主要是NVLink和IB(InfinityBand)两种技术,对比如下:
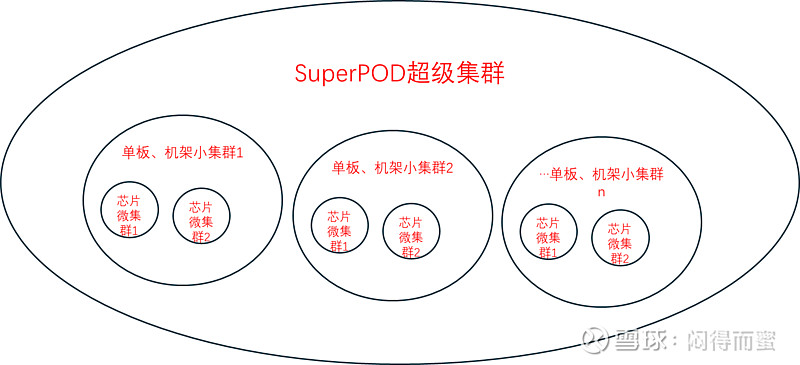
当然,SuperPOD超级集群里面一般是包含了芯片+单板/机架的集群,也就是说,大集群套小集群。
但是,需要强调的是,为了实现GPU之间高通量访问,即使有芯片级的集群、单板级的集群、机架级的集群,在SuperPOD集群内部,每一个GPU的互联接口,都必须全部暴露在SuperPOD的各个GPU下面。不能因为几个人关起门来开会,然后只留一张小门跟外界通信。相反,必须要让每一个人随时随地都能够立即跟门外的人联系!否则无法实现并行计算。所以,IB网络的规模,只由GPU的数量来决定,不受内部是否有小集群的影响。
NVLink的集群是不是越大越好呢? 为此向硅谷的算法专家请教,专家特别提到了 NVLink集群规模对软件编译器的影响。 做算法的人都知道,要将巨大的矩阵运算进行拆解,放到不同的GPU并行计算。 因为NVLink 集群和 IB集群比,他直接在硬件层面访问内存,效率要高很多。但是呢,发挥NVLink优势的前提是,必须把局部密集的运算,通过编译器自动发现并调整到一起来,这项工作非常复杂,需要很长时间时间,也需要大量的软件架构师去攻关。 所以,CSP的算法团队并不希望集群的硬件架构变来变去。学过计算机的人都知道,CPU与Memory之间是一种层次化的访问架构,都是利用程序的局部性特征来加速, SDRAM -> L3 cache -> L2 cache -> L1 cache。 因cache调度策略不同,而不同的编译器编译出来的程序性能,可能相差好几倍。原理类似。
所以,一个集群系统,是否需要光模块,要多少光模块,完全取决于集群规模的大小。一般来说,只要GPU的数量超过机架规模,就必须通过IB网络,用光模块来互联。
至于光模块数量的多少,在Nvidia的每一代芯片中均有明确的定义。需要指出的是,集群大小与光模块并不是线性关系,规模大到一定程度时,需要增加网络的层次,消耗光模块就会翻倍。一般来说,GPU : 光模 = 1 : 2.6 ~ 8 之间。
GB200架构赏析
AI刀片服务器组成:
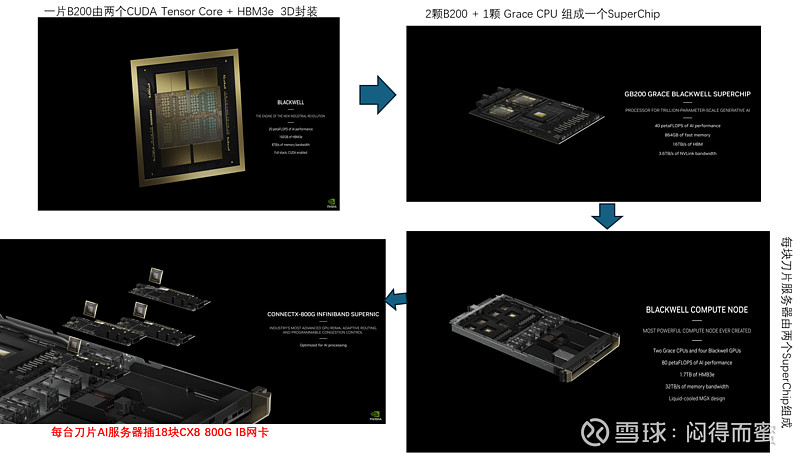
注意,一台刀片服务器必须至少配18 + 1 支800G的光模块。
机架和集群的组成:

从GTC大会上介绍,可以推导出,一个576GPU组成的集群系统,需要至少18432支800G的光模块(相对于H100的576集群,性能x4,光模块数量x4)。从单位算力的角度看,光模块的数量,并没有因为架构的调整,发生任何变化。
结论:
1、光模块的消耗量,只跟集群的规模相关,芯片架构演进只会影响占比很小的中小算法模型场景。
2、集群大小与光模块并不是线性关系,规模越大消耗的光模块加速比也越大。
3、集群的大小,由算法模型的大小决定。
4、根据Scaling law法则,算法模型必须持续增长,才能实现AGI。
5、所以光模块的需求规模,最终由人类实现AGI过程中,持续增长的模型规模决定,只要AGI的革命未成,光模块的增长不停。
杞人忧天。不就是少NVLink-switch用铜缆而不用光模块那块新增的肥肉吗,原本也不属于你的啊,至于吗。