2. 全市场估值-等权PE PB - scc (网页链接)
3. 指数PE统计 - cjhren (网页链接)
4. 集思路的一些数据抓取 - landmine (网页链接)
5. 用ATR指标来轮动ETF 抛砖引玉吧算是 (网页链接)
6. 【组合管理】——投资组合理论(有效前沿)(网页链接)
7. 关于ETF品种轮动的研究(四)(网页链接)
8. 求各位大神解答,如何实现定投回测?(网页链接)
9. 均线回归定投策略(网页链接)
10. 基金智能定投法: 均线偏离法程序测试(网页链接)
11.查询指定指数PE中位数和在历史中的位置(含数据存文件)(网页链接)
12.如何科学准确的计算指数对应的PE(平均市盈率)?(网页链接)
(一)目前采用的估值研究策略来自于2和3.研究策略代码来源于贴子2,3(版权所有)
(二)计算结果范例:
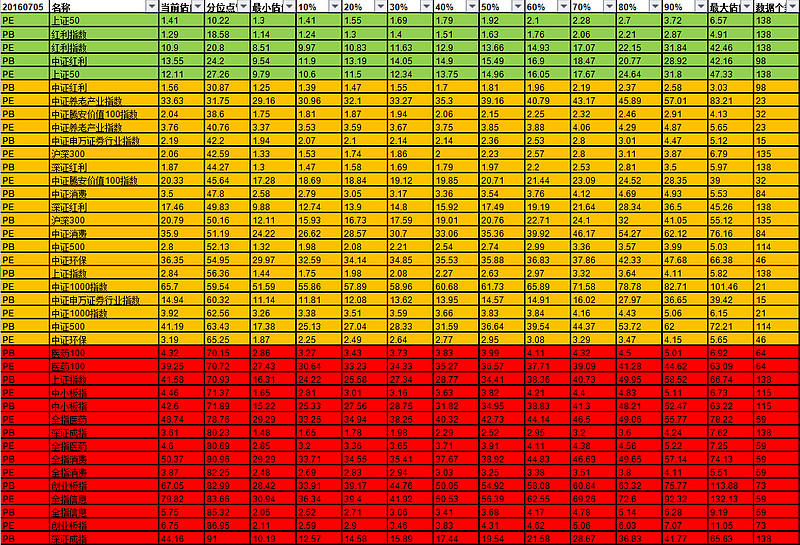
(三)代码记录如下:(&# 39;为乱码,应为&# 39;,建议大家直接去2,3原贴克隆复制,感谢聚宽平台和发贴人的奉献,@JoinQuant聚宽 )
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import bisect
#指定日期的指数PE(等权重)
def get_index_pe_date(index_code,date):
stocks = get_index_stocks(index_code, date)
q = query(valuation).filter(valuation.code.in_(stocks))
df = get_fundamentals(q, date)
if len(df)>0:
pe = len(df)/sum([1/p if p>0 else 0 for p in df.pe_ratio])
return pe
else:
return float(&# 39;NaN')
# 指定日期的指数PB(等权重)
def get_index_pb_date(index_code,date):
stocks = get_index_stocks(index_code, date)
q = query(valuation).filter(valuation.code.in_(stocks))
df = get_fundamentals(q, date)
if len(df)>0:
pb = len(df)/sum([1/p if p>0 else 0 for p in df.pb_ratio])
return pb
else:
return float('NaN&# 39;)
#指数历史PEPB
def get_index_pe_pb(index_code):
start=&# 39;2005-1-1'
# start='2015-1-1&# 39;
end = pd.datetime.today();
dates=[]
pes=[]
pbs=[]
for d in pd.date_range(start,end,freq='M&# 39;): #频率为月
dates.append(d)
pes.append(get_index_pe_date(index_code,d))
pbs.append(get_index_pb_date(index_code,d))
d = {&# 39;PE' : pd.Series(pes, index=dates),
&# 39;PB' : pd.Series(pbs, index=dates)}
PB_PE = pd.DataFrame(d)
return PB_PE
all_index = get_all_securities([&# 39;index'])
index_choose =[
&# 39;000016.XSHG',
&# 39;000300.XSHG',
&# 39;000905.XSHG',
&# 39;000852.XSHG',
&# 39;000001.XSHG',
&# 39;399001.XSHE',
&# 39;399006.XSHE',
&# 39;399005.XSHE',
&# 39;000922.XSHG',
&# 39;399324.XSHE',
&# 39;000015.XSHG',
&# 39;000827.XSHG',
&# 39;000932.XSHG',
&# 39;399812.XSHE',
&# 39;000978.XSHG',
&# 39;000991.XSHG',
&# 39;000990.XSHG',
&# 39;000993.XSHG',
&# 39;399707.XSHE',
&# 39;000847.XSHG'
]
df_pe_pb = pd.DataFrame()
frames=pd.DataFrame()
today= pd.datetime.today()
for code in index_choose:
index_name = all_index.ix[code].display_name
print u&# 39;正在处理: ',index_name
df_pe_pb=get_index_pe_pb(code)
results=[]
pe = get_index_pe_date(code,today)
q_pes = [df_pe_pb[&# 39;PE'].quantile(i/10.0) for i in range(11)]
idx = bisect.bisect(q_pes,pe)
quantile = idx-(q_pes[idx]-pe)/(q_pes[idx]-q_pes[idx-1])
# index_name = all_index.ix[code].display_name
results.append([index_name,'%.2f&# 39;% pe,'%.2f&# 39;% (quantile*10)]+['%.2f&# 39;%q for q in q_pes]+[df_pe_pb['PE&# 39;].count()])
pb = get_index_pb_date(code,today)
q_pbs = [df_pe_pb['PB&# 39;].quantile(i/10.0) for i in range(11)]
idx = bisect.bisect(q_pbs,pb)
quantile = idx-(q_pbs[idx]-pb)/(q_pbs[idx]-q_pbs[idx-1])
#index_name = all_index.ix[code].display_name
results.append([index_name,&# 39;%.2f'% pb,&# 39;%.2f'% (quantile*10)]+[&# 39;%.2f'%q for q in q_pbs]+[df_pe_pb[&# 39;PB'].count()])
df_pe_pb[&# 39;10% PE']=q_pes[1]
df_pe_pb[&# 39;50% PE']=q_pes[5]
df_pe_pb[&# 39;90% PE']=q_pes[9]
df_pe_pb[&# 39;10% PB']=q_pbs[1]
df_pe_pb[&# 39;50% PB']=q_pbs[5]
df_pe_pb[&# 39;90% PB']=q_pbs[9]
df_pe_pb.plot(secondary_y=[&# 39;PB',&# 39;10% PB',&# 39;50% PB',&# 39;90% PB'],figsize=(14,8),title=index_name,style=[&# 39;k-.', &# 39;k', &# 39;g', &# 39;y', &# 39;r', &# 39;g-.', &# 39;y-.', &# 39;r-.'])
columns=[u&# 39;名称',u&# 39;当前估值',u&# 39;分位点%',u&# 39;最小估值']+[&# 39;%d%%'% (i*10) for i in range(1,10)]+[u&# 39;最大估值' , u&# 34;数据个数"]
df= pd.DataFrame(data=results,index=[&# 39;PE',&# 39;PB'],columns=columns)
frames = pd.concat([frames, df])
frames
ps:freq=&# 39;M'改为freq=&# 39;D'即为按天计算,可增加数据点个数