撰文|李信马 小不董

本以为互联网近期的热点,应该是电商们的促销活动,没想到,大厂大模型却硬生生抢了风头。一周之内,字节跳动、阿里巴巴、百度和腾讯接连宣布大降价!甚至免费!不挣钱了,就是交个朋友,为行业发展做贡献!
这些消息,谁看了不激动?
我们简单梳理一下,5月15日,字节跳动打响了国内大模型价格战的第一枪,旗下的AI大模型豆包(原名:云雀)宣布,主力模型定价比行业价格水平要便宜 99.3% !
豆包大模型的 API 输入价格是 0.0008元/千 tokens(大模型文本的最小单位),自此,中国大模型的市场价格直接卷入“厘时代”,1块钱在豆包能买到整整 125万 tokens !
可能怕现场的朋友们没有直观的感受,字节跳动还特意把两位友商的大模型文心一言和通义千问拿来做了对比,属实简单明了又让人大为震撼!
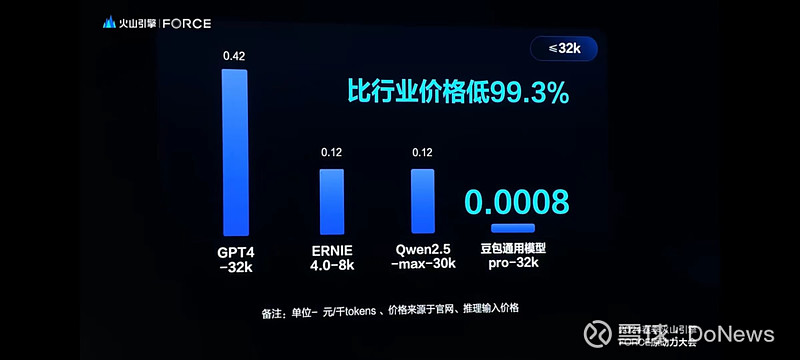
图片来源:火山引擎
字节跳动的豆包一时风光无二,可被拿来对比的,就有些坐不住了。价格战?谁不会!5月21日,阿里云宣布,通义千问也迎来大降价,而且幅度更大!通义千问直接降到 0.0005元/千 tokens,1块钱可以买到 200万 tokens ,相当于5本新华字典了,并提前宣布拿下“性价比之王”的称号。

好好好,都这么玩是吧?
到了下午, 在国产大模型中处于“一哥”位置的百度,在官方公众号发布了一份公告,内容只有一句话:“文心大模型两大主力模型全面免费,立即生效!”
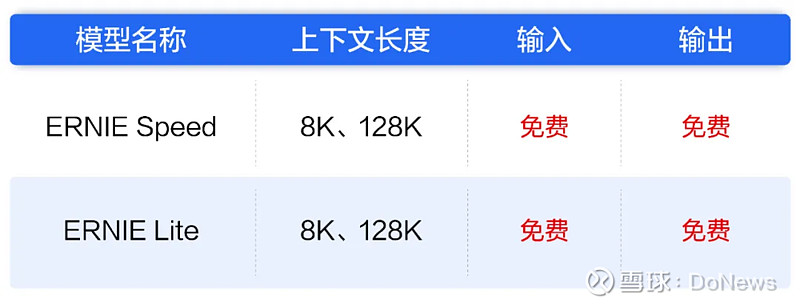
图片来源:百度智能云
新闻越短,消息越大。一句主力模型免费,比“地板价”还令人震撼。到了22日,腾讯也按捺不住了,公布全新大模型升级方案,主力模型之一的混元-lite 模型不仅从 4k 升级到 256k ,而且全面免费;其他模型除了长度升级外,价格也都大幅下降。
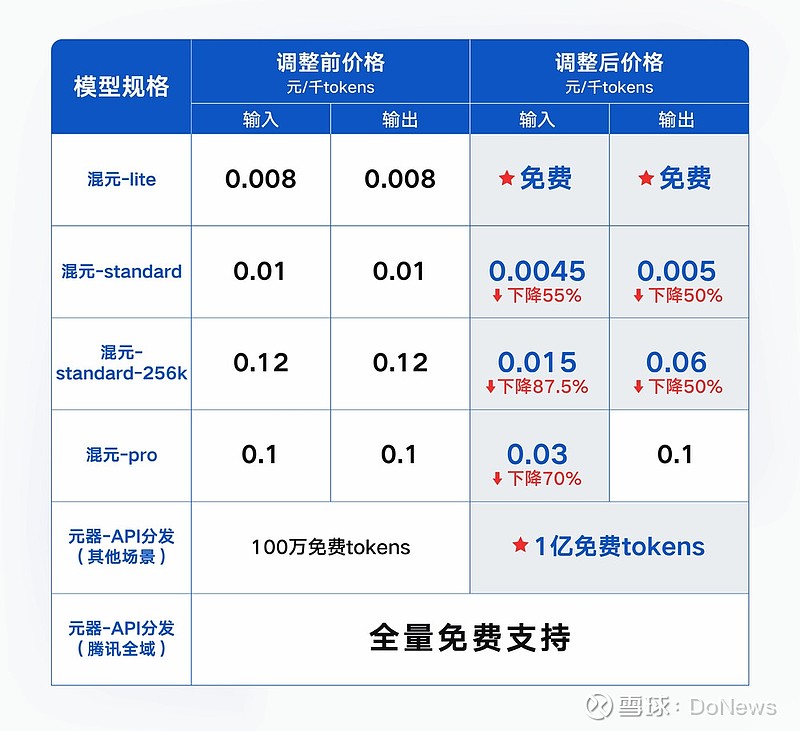
图片来源:腾讯
捋完了国内大厂的降价消息,笔者只想说:“凶残,太凶残了!”
但是对用户们来说,却是喜大普奔,调用大模型的成本大大降低。我们也对四家大厂最新的大模型价格进行了整理,务必让大家掌握一手优惠信息。
首先,是新增的免费模型,这里点名表扬一下百度和腾讯,阿里云通义千问也有两个开源模型限时七天免费。
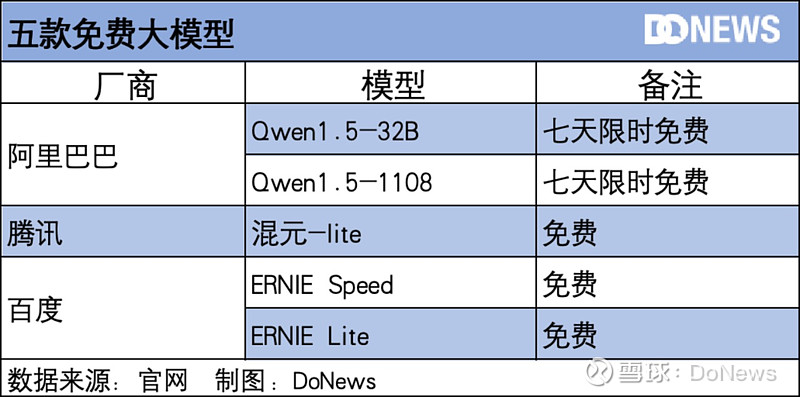
其次,我们来对比一下各大厂主力模型的价格。(注明:大语言模型通常采用输入(input)和输出(output)分别计费的方式,这是因为模型在推理过程中,输入和输出的资源消耗不同。输入计费针对用户向模型提交的请求数据进行计费,输出计费针对模型返回给用户的输出结果进行计费。)
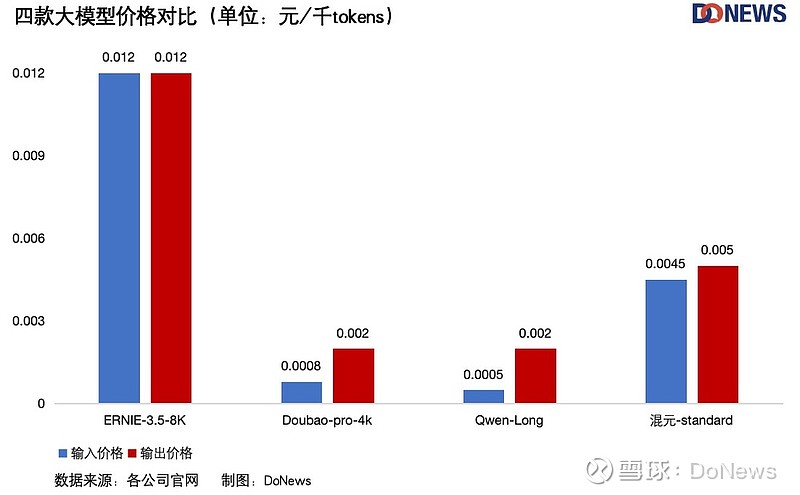
由于不同模型的参数量和支持 tokens 的最大长度各不相同,像是阿里的 Qwen-Long 上下文长度最长1000万,而百度 ERNIE-4.0-8K 却还是 8k ,大厂之间进行横向对比,只看价格多少有失公允,所以我们也做出了每家大厂旗下模型的价格以供参考。
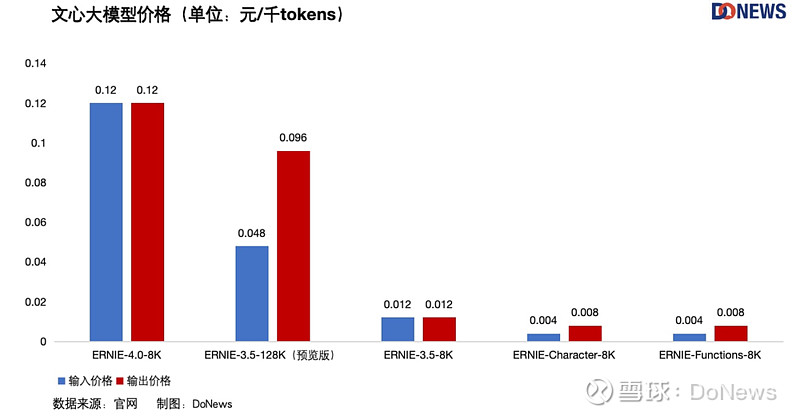
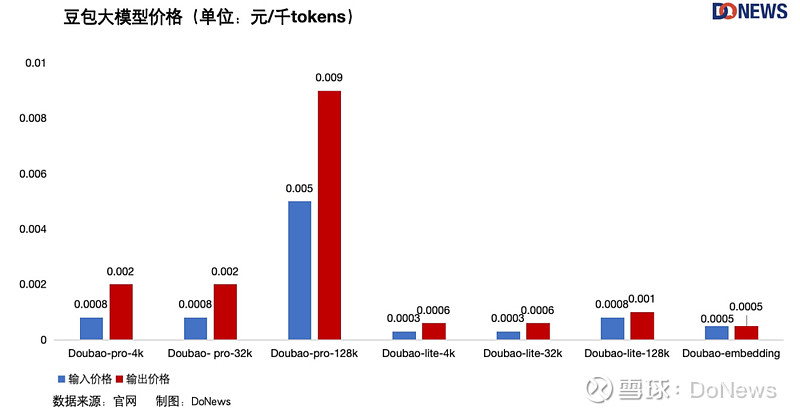
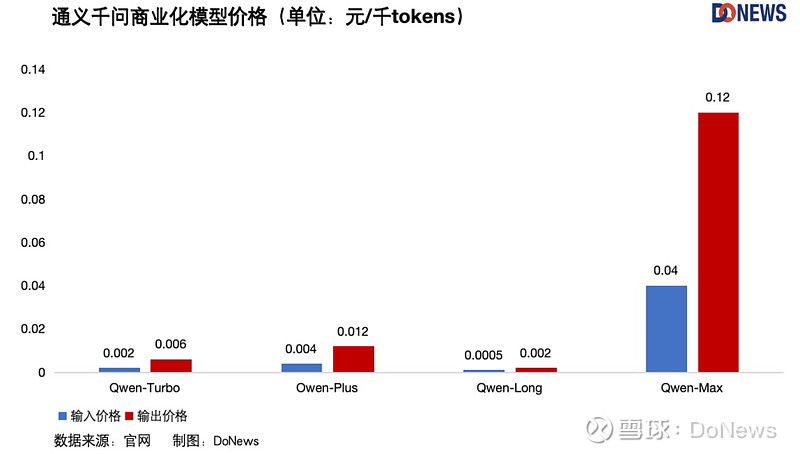
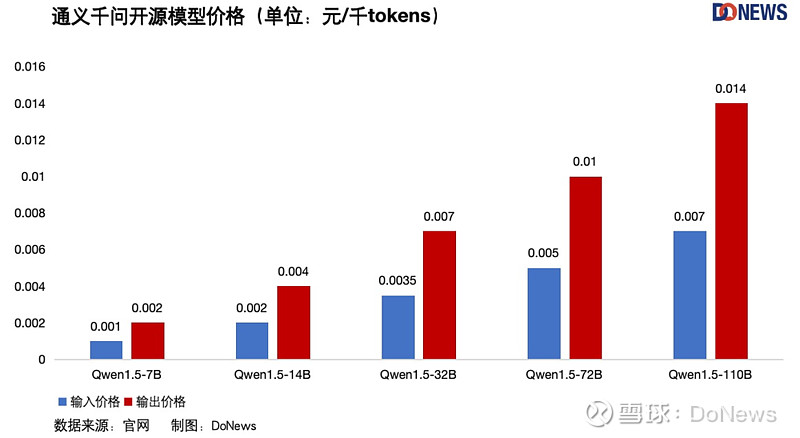
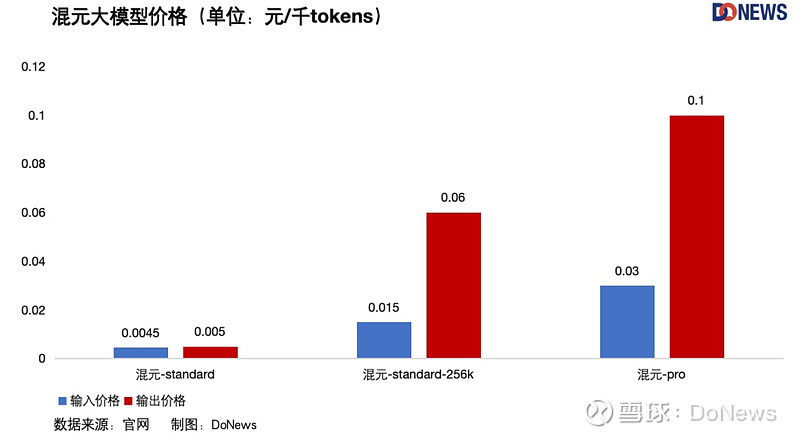
不久前,我们对大模型的吐槽还是太贵,怎么一转眼,价格战就打了起来?
在笔者看来,四家大厂的接连降价,反映了国内大模型行业正在迅速进入大规模商业化落地的阶段,更低的大模型使用成本,就是这一阶段发展的前提。大模型太贵,那企业还怎么落地应用?不落地应用,行业还怎么发展?大厂们的降价,“交个朋友”的意味要远高于赚钱,朋友多了,自家大模型生态繁荣起来,才是真正的未来可期。
这一点,阿里云智能集团资深副总裁、公共云事业部总裁刘伟光在宣布降价时就明确表示,“(降价)它的目的一定是普惠于市场”,“要真正加速市场的提前爆发”。
而且随着技术的进步,就像摩尔定律,大模型的成本也在持续的降低之中。5月22日凌晨,在微软 Build 开发者大会上,纳德拉就说,过去一年 GPT-4 性能提升了 6 倍,但成本降低到了之前的 1/12,对应性能/成本提升了 70 倍。
在大模型发展的上一阶段,比的是技术水平,刷榜评测是主流;而本阶段,综合实力变得更重要。只是在国内市场上,大模型之战,被大厂一下子带入了白热化的状态。说到这,很容易就想起了一段经典的台词:

图片来源:网络
在大模型的赛道上混,也要讲势力,讲背景。刘伟光就认为,“降价”也不是谁都有资格降价的,在中国,有资格、有能力(对大模型)降价的公司,应该满足“四有”条件:
模型的基模能力足够领先,有真正全方位的多模态; 有真正的推理资源,包括大规模推理计算集群背后的网络、基础计算、存储等方方面面的基础数据中心能力的支撑; 当下的模型已经有很多的客户在使用,并且在产生商业的效果; 大模型是公司最核心的业务。对号入座,不难发现,这四家大厂,都是有底气降价,而且有能力推动大模型加速落地的。大厂们的集体降价,对大模型创业公司来说可能有些残酷,但对行业来说,却是添了几大车干柴。
刘伟光说,他相信,2024年中国大模型的日调用量,会从1亿暴涨到100亿,伴随着这一轮“降价促销”,这一预测可能真的会实现。