7月9日OpenAI对全量Plus用户开放了Code Interpreter功能,其能力是能对文件(表格、文本、图片)进行自动化分析处理工作。Code Interpeter可以看作是OpenAI所研发的Agent方向中,对文件处理能力的展示。接下来从一个使用实例分析下它是如何工作的。
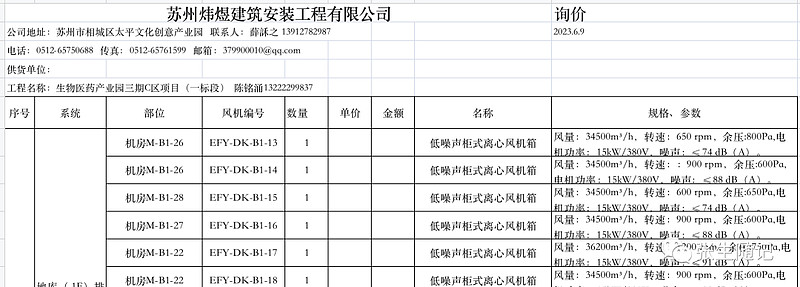
以下是一份原始表格,我们对其提出从指定行提取数据并进行表格编辑的操作要求。
以下是ChatGPT自己完整的思考、执行,并最后完成任务的过程。

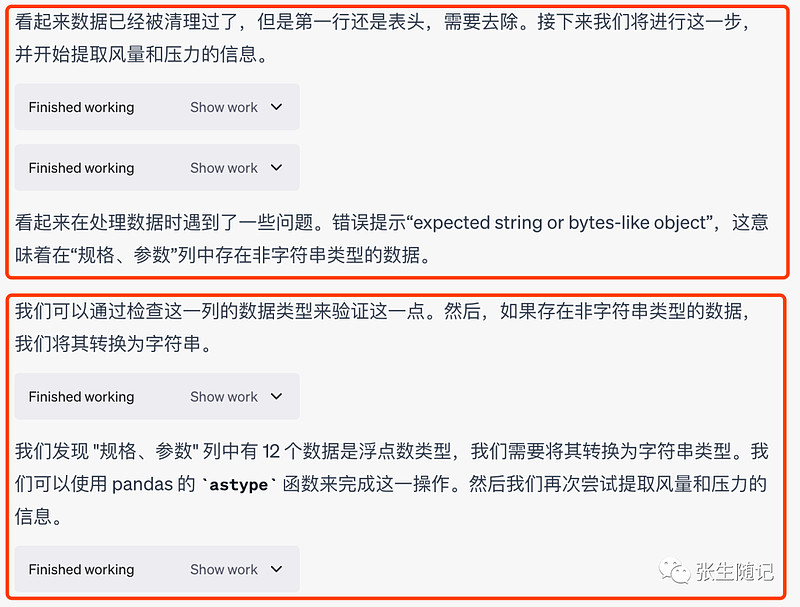

过程可以总结为:
任务规划:理解用户自然语言并将其分拆为多个按顺序执行的子任务
执行任务(自动编写python代码并执行)->任务验证(查看代码输出或报错信息)->尝试新方案再次循环
重点关注的是执行任务的过程,可以看到ChatGPT使用了Reason and Act的方法,即写出自己的思考过程,表达其判断要执行的任务的reason是什么,然后再行动。
简单来说,ReAct 方法即推理+动作得到结果。灵感来自于作者对人类行为的一个洞察:在人类从事一项需要多个步骤的任务时,每一步之间往往会有一个推理过程。作者提出让 LLM 把内心独白“说”出来,然后再根据独白做相应的动作,模仿人类的推理过程,以提高 LLM 答案的准确性。这种方式在多种数据集上都取得了 SOTA 效果,并且更加可信,提升了 LLM 应对“胡说八道”的能力。
在任务验证时,进行“自我反思”。
一个为 AI Agents 提供动态记忆和自我反思能力,以提高推理能力的框架。该框架采用标准的强化学习设置,其中奖励模型提供简单的二元奖励(0/1),动作空间遵循 ReAct 中的设置,同时基于特定任务的行动空间,使用语言增强功能,以实现复杂的推理步骤。在每个动作 at 之后,AI Agents 会计算一个启发式值 ht,并根据自我反思的结果来选择是否重置环境以开始新的实验。
假设:每个人都能配备一个或多个AI助理,那么对推理算力的需求是无法想象的。